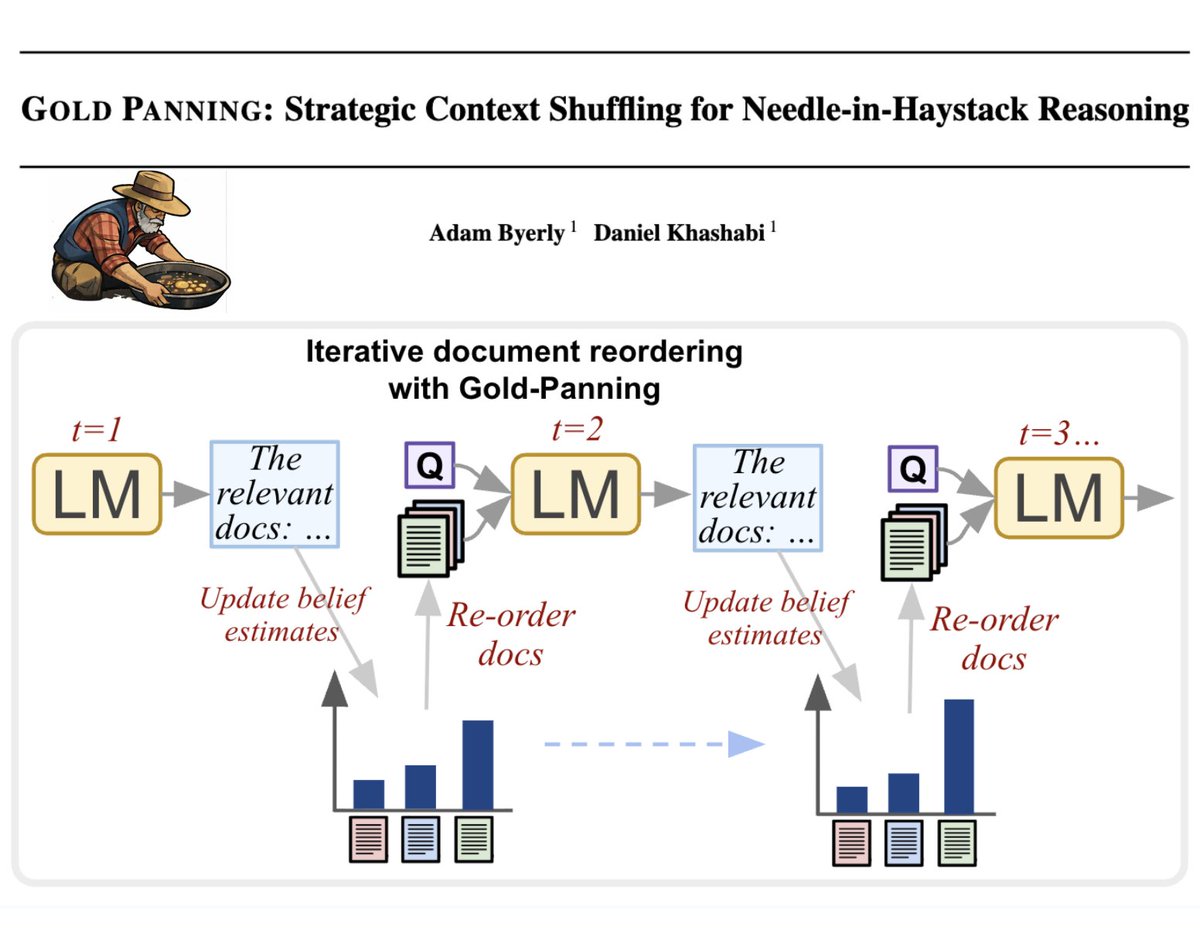
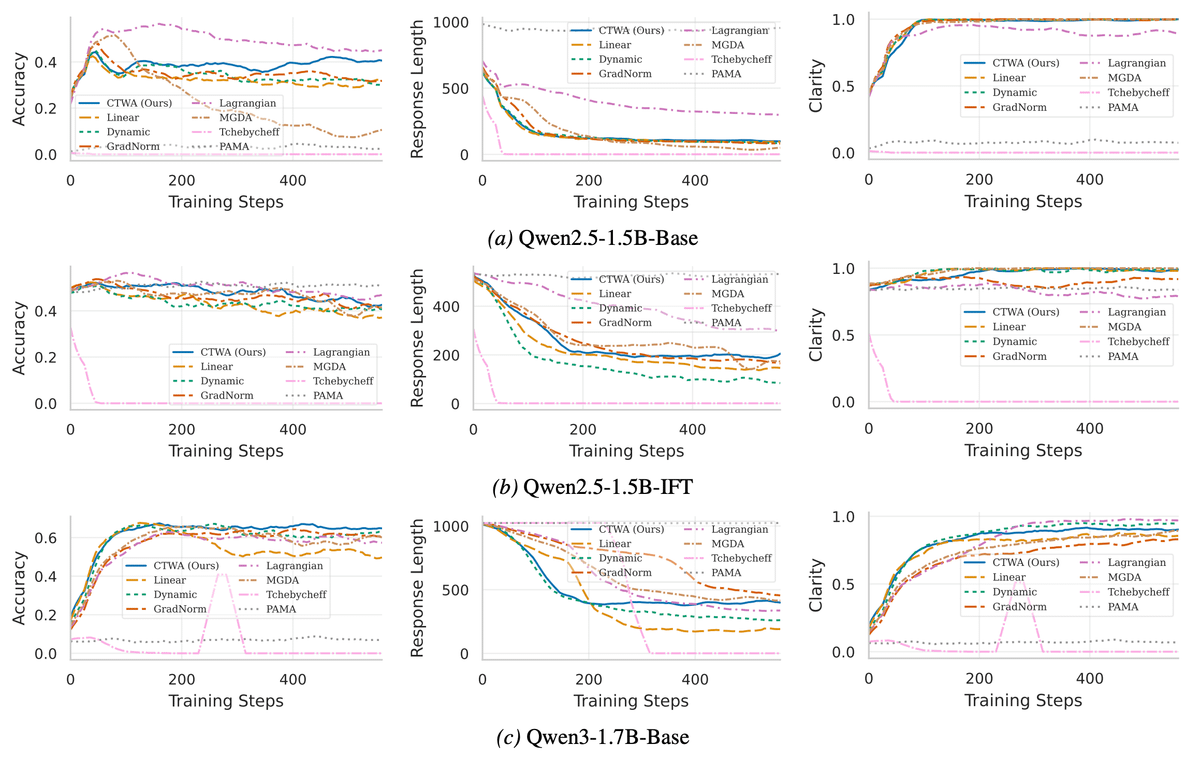
Sabitlenmiş Tweet

Thrilled to share that I'll start my Ph.D. at @ND_CSE this fall, working with @Meng_CS. I am so grateful for the sincere guidance from my current advisor, @DanielKhashabi, and for the unconditional support I received from my family, friends, and collaborators over the past years!
English