Sabitlenmiş Tweet

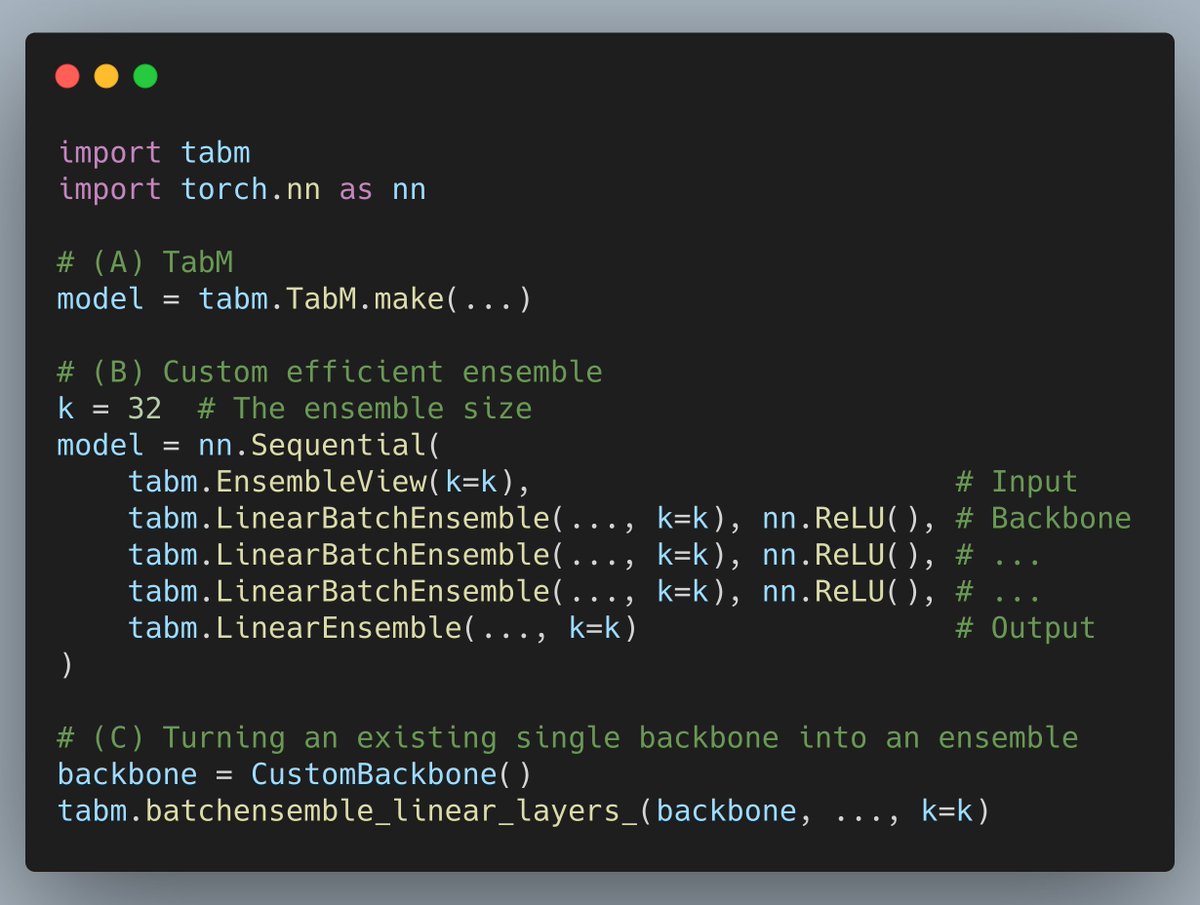
TabM now has a Python package!
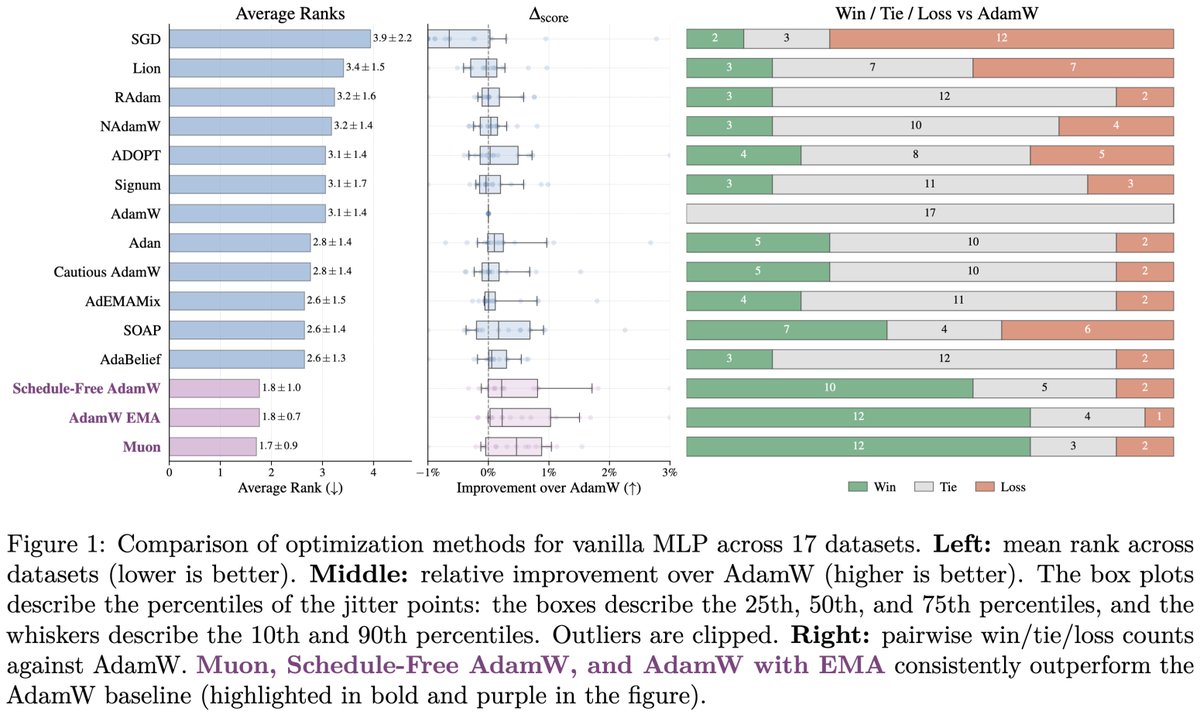
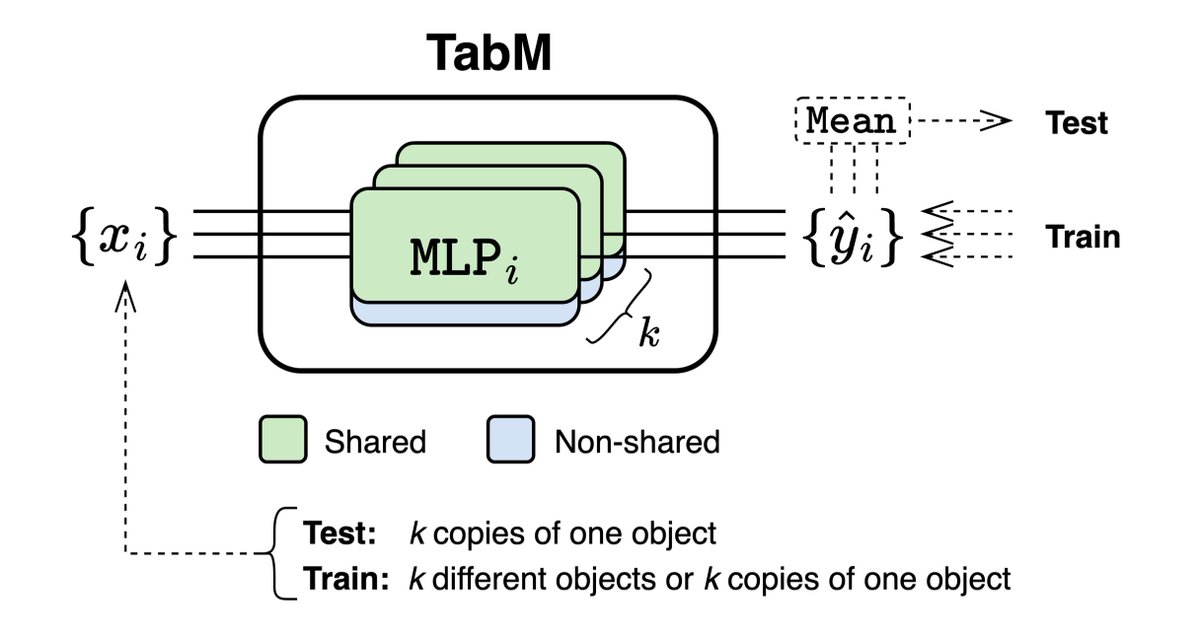
TabM is a simple and powerful DL architecture for tabular data that efficiently imitates an ensemble of MLPs
🏆 TabM has been used in winning solutions on Kaggle, and performs well on TabReD -- a challenging benchmark!
💻 pip install tabm
👇Link
English