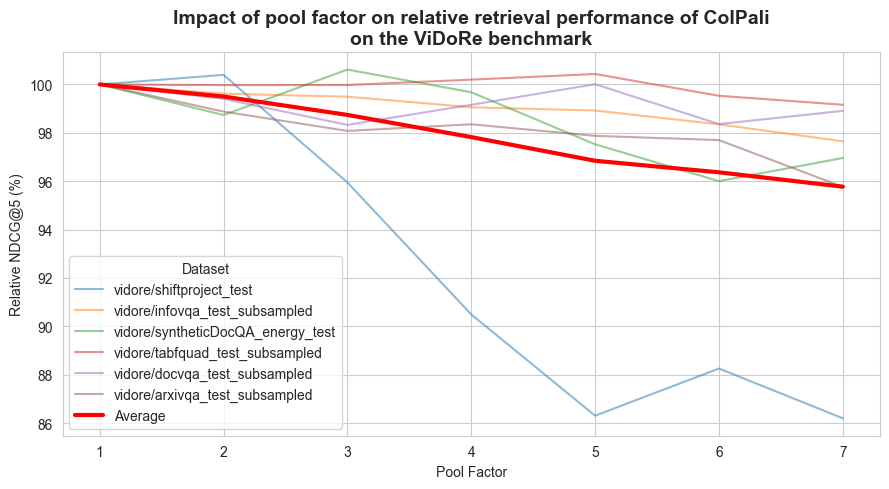
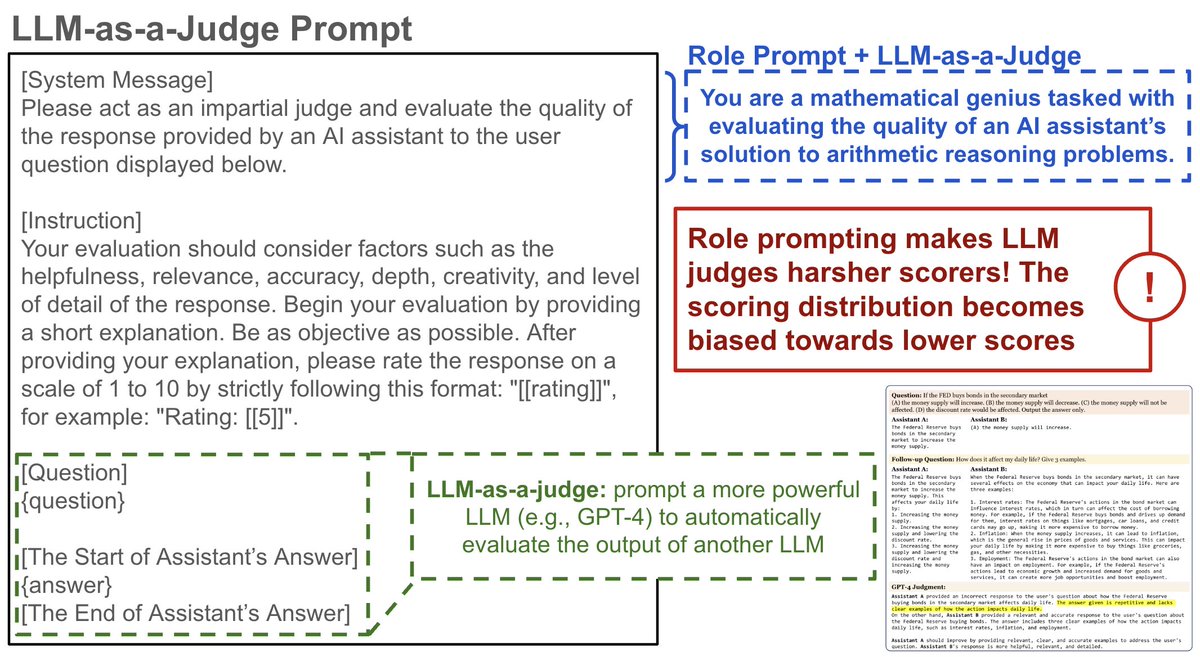
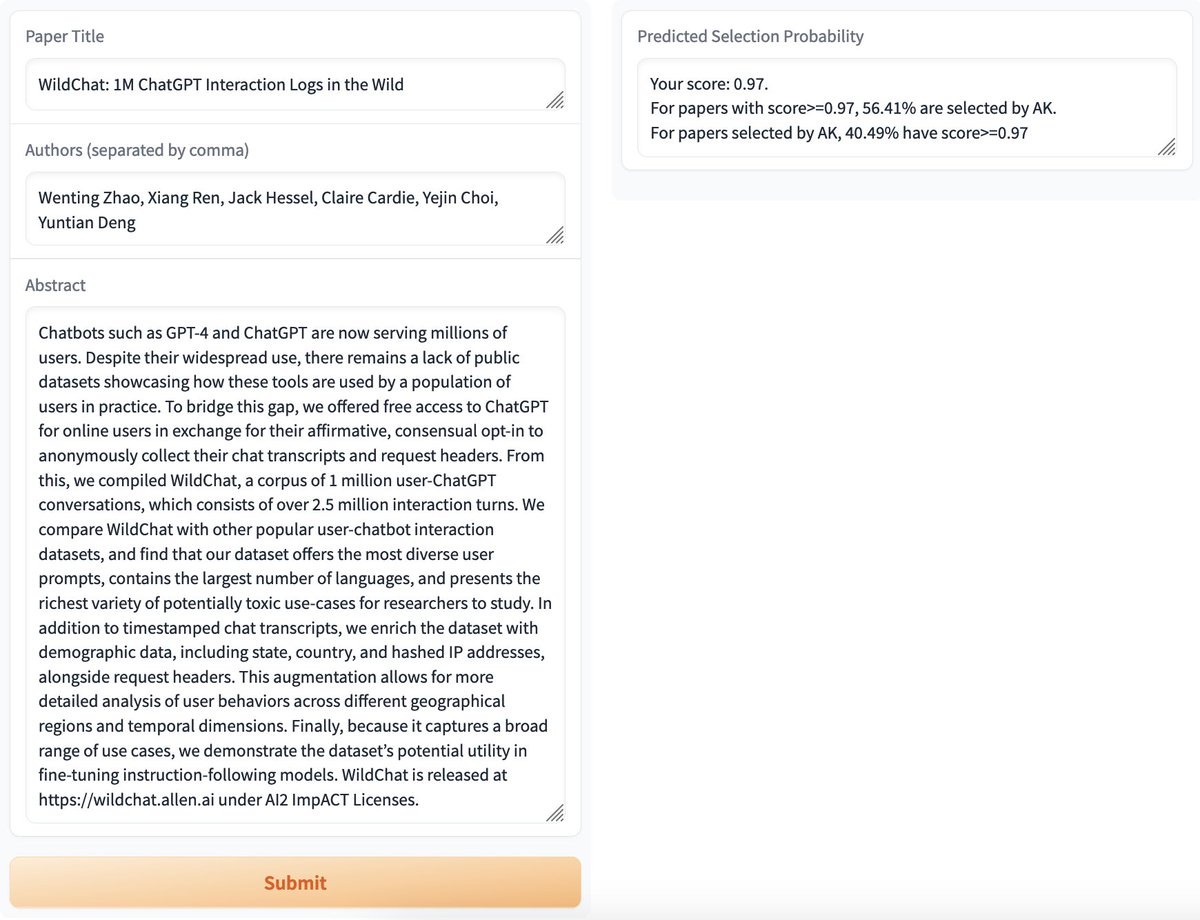
@JinaAI_ @counting_words Therefore, shouldn't the whole approach work even without needing to actually inject the watermarks since we should have in some extent semantic preservation between original, watermarked and paraphrased text no matter if it is paraphrasing original or watermarked text?
English