
Jonathan Lai
30 posts
Jonathan Lai
@_JLai
Post training @GoogleDeepMind, Gemini Reasoning, training algorithms, RL, opinions are my own
Katılım Kasım 2012
198 Takip Edilen568 Takipçiler

Last week I joined @GoogleDeepMind after leaving Meta. There is so much going on, it's an exciting time.
Looking forward to what I will end up doing.
English
@denny_zhou Once the model's innovations are better than ours we can finally end our 997 and go on vacation.
English

Jonathan Lai retweetledi

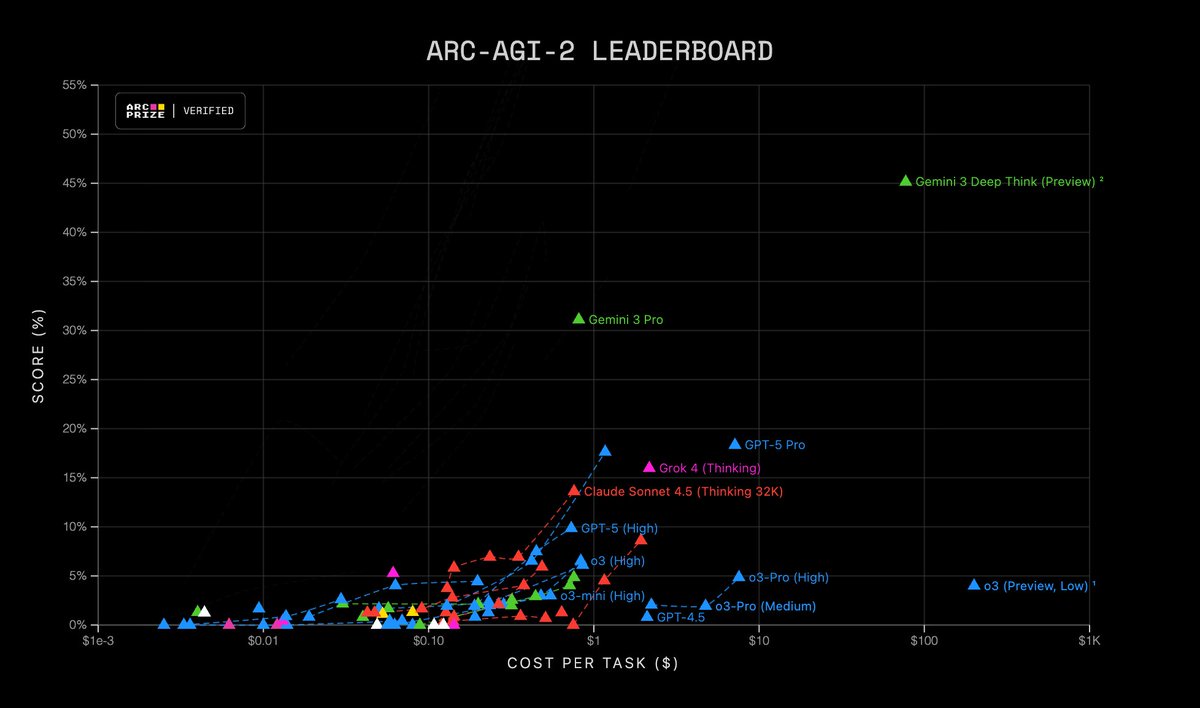
Gemini 3 models from @Google @GoogleDeepMind have made a significant 2X SOTA jump on ARC-AGI-2 (Semi-Private Eval)
Gemini 3 Pro:
31.11%, $0.81/task
Gemini 3 Deep Think (Preview):
45.14%, $77.16/task
English
Jonathan Lai retweetledi

This is Gemini 3: our most intelligent model that helps you learn, build and plan anything.
It comes with state-of-the-art reasoning capabilities, world-leading multimodal understanding, and enables new agentic coding experiences. 🧵
English
@XingyouSong Bitter lesson strikes again! RLM’s are such an elegant solution. Congratulations Richard and Yash!
English
@yacineMTB It’s more like how a dog learns new tricks, i.e. trying random actions until human gives it a treat. Humans can learn more efficiently by leveraging reasoning.
English


Jonathan Lai retweetledi

Excited to share that I'll be hosting some of the world's best AI researchers and engineers for our @GoogleDeepMind Gemini event next week in Singapore 🇸🇬!
Join @JeffDean, @quocleix, @benoitschilling, @melvinjohnsonp and @denny_zhou for a day of technical conversations, panels and talks about AI, reasoning and our mission to build a world class AI frontier lab in Singapore.
If you're in town and would like to attend, please check the RSVP link below👇. Note, subject to capacity constraints and you'll need to be approved to join.

English
@denny_zhou @jamesjyan117153 Reasoning underpins AGI. I am grateful for the opportunity to contribute to reasoning in Gemini.
RL for LLMs was an enormous breakthrough, and there are more fundamental algorithmic breakthroughs yet to come!
English
The technique of RL finetuning for reasoning was independently discovered by several labs. At Google DeepMind, credit goes to Jonathan Lai (@_JLai) and James An (@jamesjyan117153) on my team.
English
Slides for my lecture “LLM Reasoning” at Stanford CS 25: dennyzhou.github.io/LLM-Reasoning-…
Key points:
1. Reasoning in LLMs simply means generating a sequence of intermediate tokens before producing the final answer. Whether this resembles human reasoning is irrelevant. The crucial insight is that transformer models can become nearly arbitrarily powerful by generating many intermediate tokens, without the need of scaling the model size (arxiv.org/abs/2402.12875).
2. Pretrained models, even without any fine-tuning, are capable of reasoning. The challenge is that reasoning-based outputs often don’t appear at the top of the output distribution, so standard greedy decoding fails to surface them (arxiv.org/abs/2402.10200)
3. Prompting techniques (e.g., chain-of-thought prompting or "let’s think step by step") and supervised finetuning were commonly used to elicit reasoning. Now, RL finetuning has emerged as the most powerful method. This trick was independently discovered by several labs. At Google, credit goes to Jonathan Lai on my team. Based on our theory ( see point 1), scaling RL should focus on generating long responses rather than something else.
4. LLM reasoning can be hugely improved by generating multiple responses and then aggregating them, rather than relying on a single response (arxiv.org/abs/2203.11171).
English

@XingyouSong Already know it's over with you and @_JLai cooking!
English
Huge congrats @prateeky2806 and all!! 🎉 It was great to work with everyone here!
Tu Vu@tuvllms
Excited to share that our paper on model merging at scale has been accepted to Transactions on Machine Learning Research (TMLR). Huge congrats to my intern @prateeky2806 and our awesome co-authors @_JLai, @alexandraxron, @manaalfar, @mohitban47, and @TsendeeMTS 🎉!!
English
Jonathan Lai retweetledi

Excited to share that our paper on model merging at scale has been accepted to Transactions on Machine Learning Research (TMLR). Huge congrats to my intern @prateeky2806 and our awesome co-authors @_JLai, @alexandraxron, @manaalfar, @mohitban47, and @TsendeeMTS 🎉!!
Prateek Yadav@prateeky2806
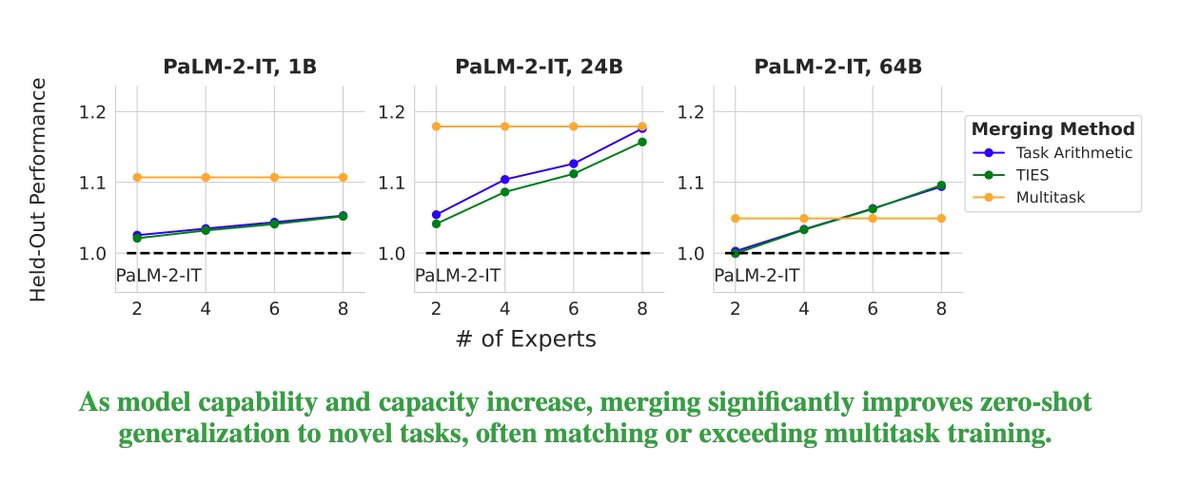
Ever wondered if model merging works at scale? Maybe the benefits wear off for bigger models? Maybe you considered using model merging for post-training of your large model but not sure if it generalizes well? cc: @GoogleAI @GoogleDeepMind @uncnlp 🧵👇 Excited to announce my internship work on large-scale model merging! We explore what happens when you combine larger and larger language models (up to 64B parameters!) and how different factors –model size, base model quality, merging methods, and # of experts– impact held-in performance and generalization. 📰: arxiv.org/abs/2410.03617
English
@BorisMPower @demishassabis We actually published our first Thinking / Reasoning model before the o-series was announced. Math-Specialized 1.5 Pro.
Oriol Vinyals@OriolVinyalsML
Today we have published our updated Gemini 1.5 Model Technical Report. As @JeffDean highlights, we have made significant progress in Gemini 1.5 Pro across all key benchmarks; TL;DR: 1.5 Pro > 1.0 Ultra, 1.5 Flash (our fastest model) ~= 1.0 Ultra. As a math undergrad, our drastic results in mathematics are particularly exciting to me! In section 7 of the tech report, we present new results on a math-specialised variant of Gemini 1.5 Pro which performs strongly on competition-level math problems, including a breakthrough performance of 91.1% on Hendryck’s MATH benchmark without tool-use (examples below 🧵). Gemini 1.5 is widely available, try it out for free here aistudio.google.com & read the full tech report here: goo.gle/GeminiV1-5
English

@demishassabis Yes, you may have been working on it for a very long time, but you should acknowledge that OpenAI o-series models beat you to it :)
English

We’ve been working on planning and thinking capabilities for our AI models since our AlphaGo days. When these models are given more time to think, responses improve. At I/O we introduced Gemini 2.5 Pro Deep Think, a new enhanced reasoning mode that makes 2.5 Pro even better!
GIF
English
@Swarooprm7 Congrats Swaroop! Looking forward to seeing what you and MAI cook up!
English

Excited to join Microsoft AI.
Watch out for some cool stuff coming your way 😎

English
After an amazing journey at Google—first with Google Brain, then Google DeepMind—I’ve made the tough decision to leave. Immensely grateful for the brilliant colleagues and lifelong friends I’ve made along the way. I'm excited to keep riding the AI wave, creating stories that will inspire the next generation!

English
Jonathan Lai retweetledi
🚨 New paper 🚨
Excited to share my first paper w/ my PhD students!!
We find that advanced LLM capabilities conferred by instruction or alignment tuning (e.g., SFT, RLHF, DPO, GRPO) can be encoded into model diff vectors (à la task vectors) and transferred across model versions.
💡You don’t necessarily need to fine-tune from scratch again for every new base model version. Instead, fine-tune once and add the diff vector to updated versions! ♻️♻️♻️. This can also offer a stronger and more computationally efficient starting point when further training is feasible.
📰: tinyurl.com/finetuning-tra…
More 👇



English
Jonathan Lai retweetledi

Jonathan Lai retweetledi

Gemini-ийн шинэ загварыг туршаад үзээрэй. Код бичих дээр нилээн сайжирсан байгаа.
Google DeepMind@GoogleDeepMind
Think you know Gemini? 🤔 Think again. Meet Gemini 2.5: our most intelligent model 💡 The first release is Pro Experimental, which is state-of-the-art across many benchmarks - meaning it can handle complex problems and give more accurate responses. Try it now → goo.gle/4c2HKjf
Русский
A historic elo margin on LMSYS and also crushed almost all reasoning and STEM benchmarks!! So proud of this team!!
Arena.ai@arena
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)! 🏆 Tested under codename "nebula"🌌, Gemini 2.5 Pro ranked #1🥇 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn! Massive congrats to @GoogleDeepMind for this incredible Arena milestone! 🙌 More highlights in thread👇
English
Jonathan Lai retweetledi

1/ Gemini 2.5 is here, and it’s our most intelligent AI model ever.
Our first 2.5 model, Gemini 2.5 Pro Experimental is a state-of-the-art thinking model, leading in a wide range of benchmarks – with impressive improvements in enhanced reasoning and coding and now #1 on @lmarena_ai by a significant margin. With a model this intelligent, we wanted to get it to people as quickly as possible.
Find it on Google AI Studio and in the @geminiapp for Gemini Advanced users now – and in Vertex in the coming weeks. This is the start of a new era of thinking models – and we can’t wait to see where things go from here.
English