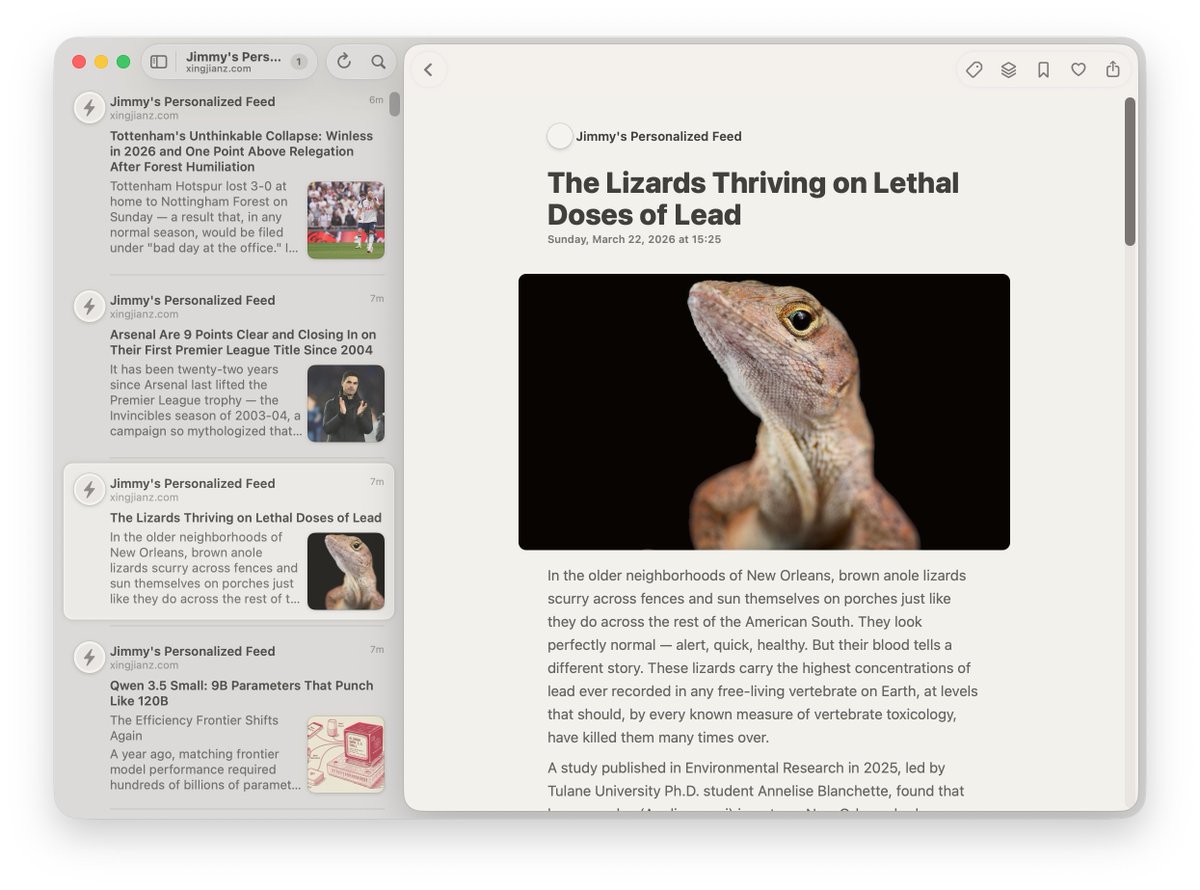
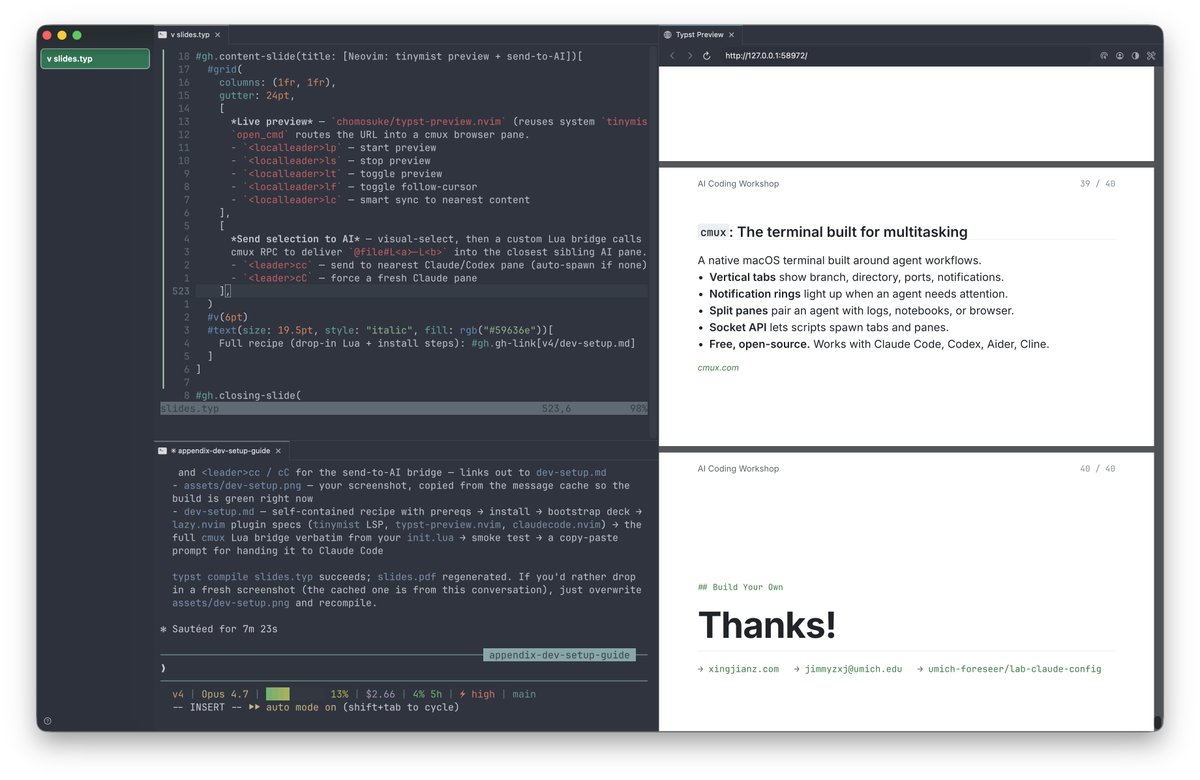
@Jiaqi_Ma_ Many people have asked how I made these slides, so I added an appendix explaining the setup: cmux + Neovim + Typst + Claude Code. It’s much faster than a Google Slides or LaTeX Beamer workflow. The slide template is open-sourced here: typst.app/universe/packa…
English