Sabitlenmiş Tweet

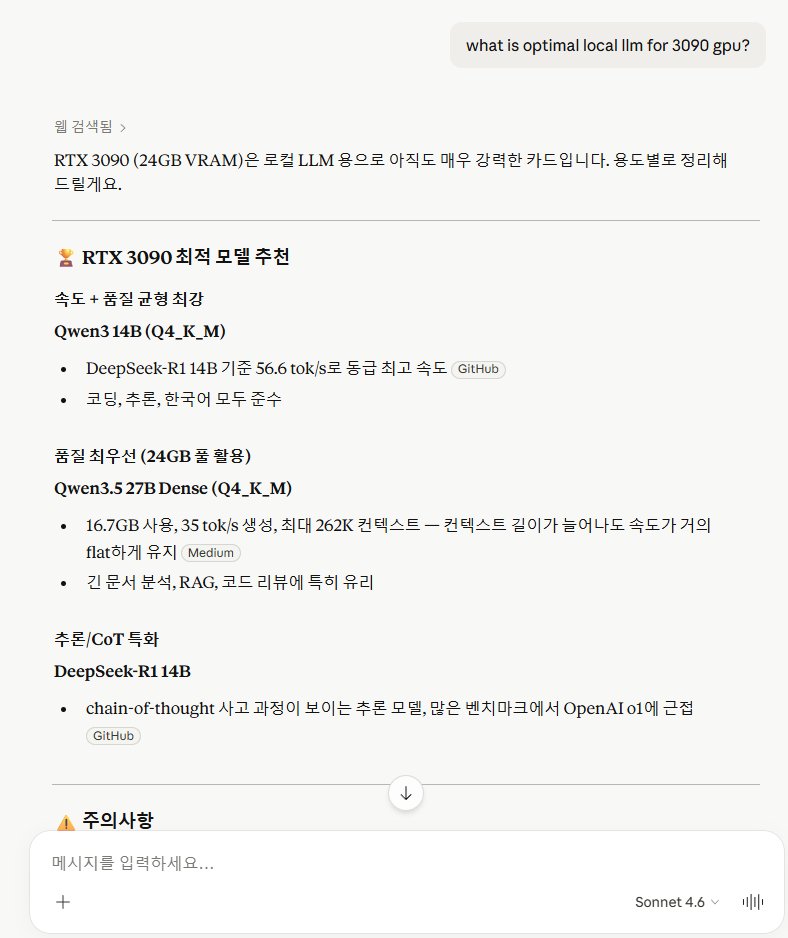
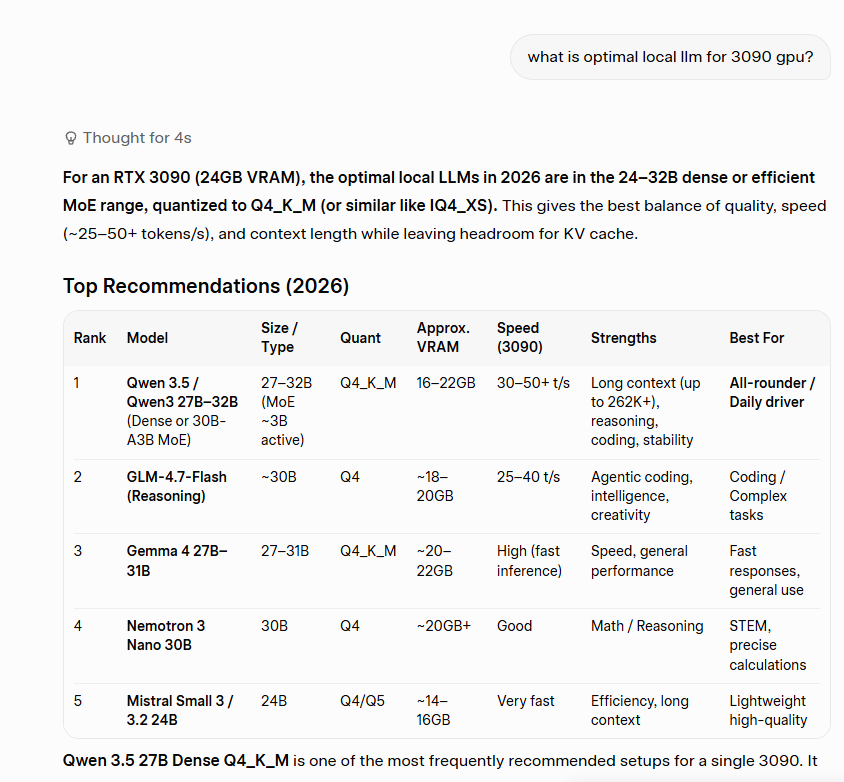
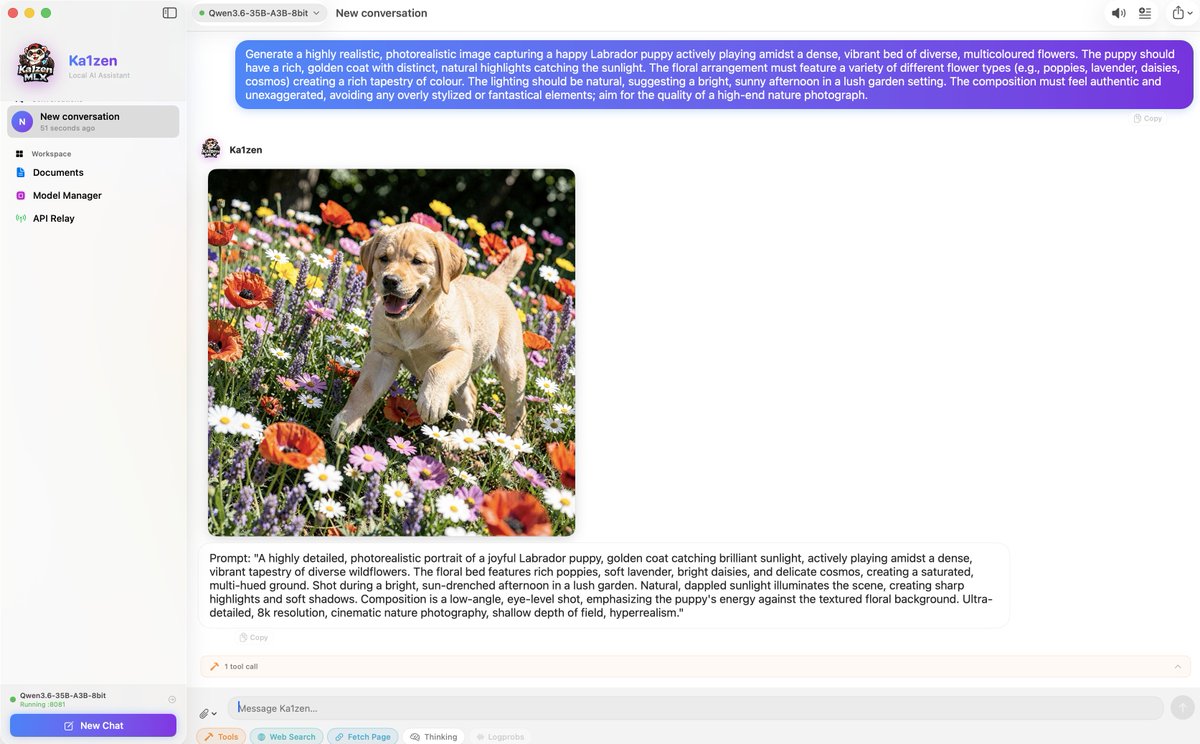
Ka1zen — chat with open LLMs 100% offline on your Mac.
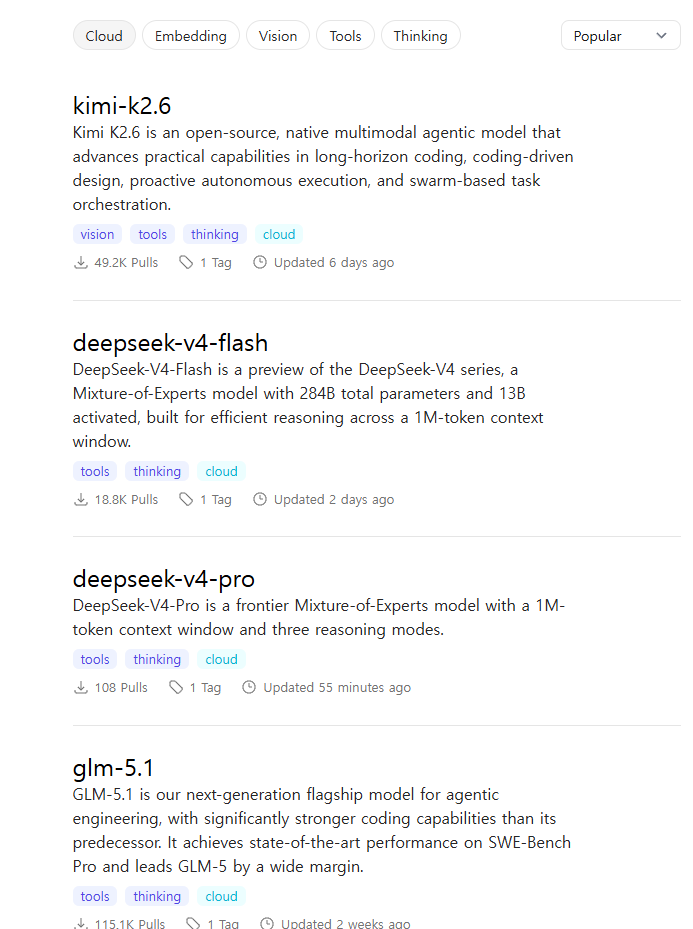
🧠 Qwen, Gemma, DeepSeek, Mistral, Llama…
🖼 Vision · 🎙 Audio · 🌐 Web search
🎨 FLUX image generation · 📚 RAG
🔒 Zero cloud, zero telemetry
Powered by Apple MLX.
github.com/Flor1an-B/Ka1z…
English