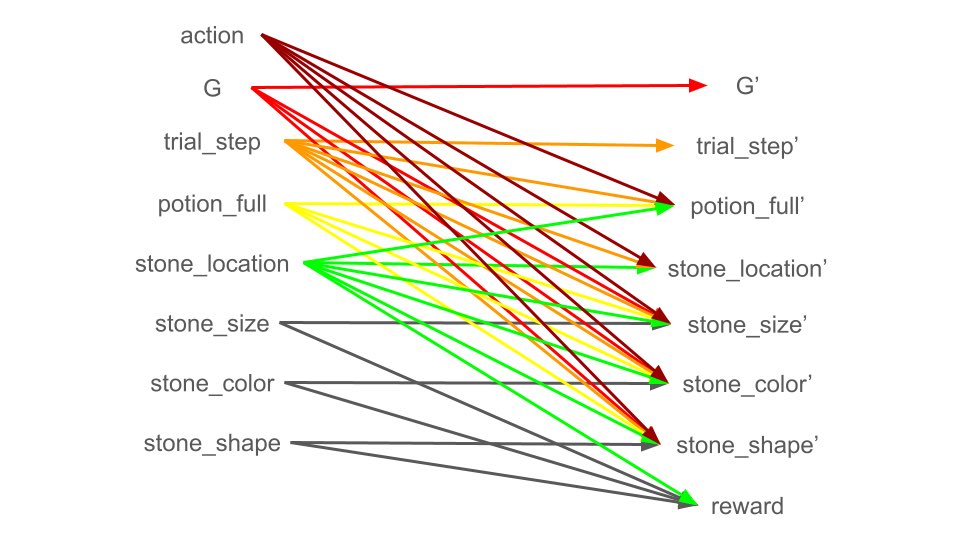
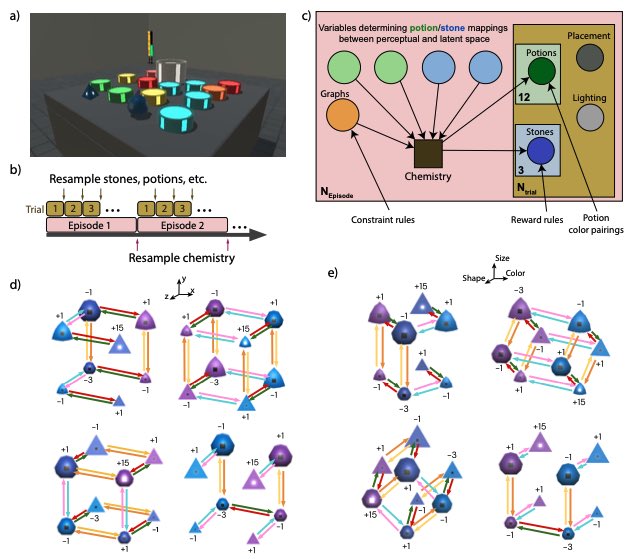
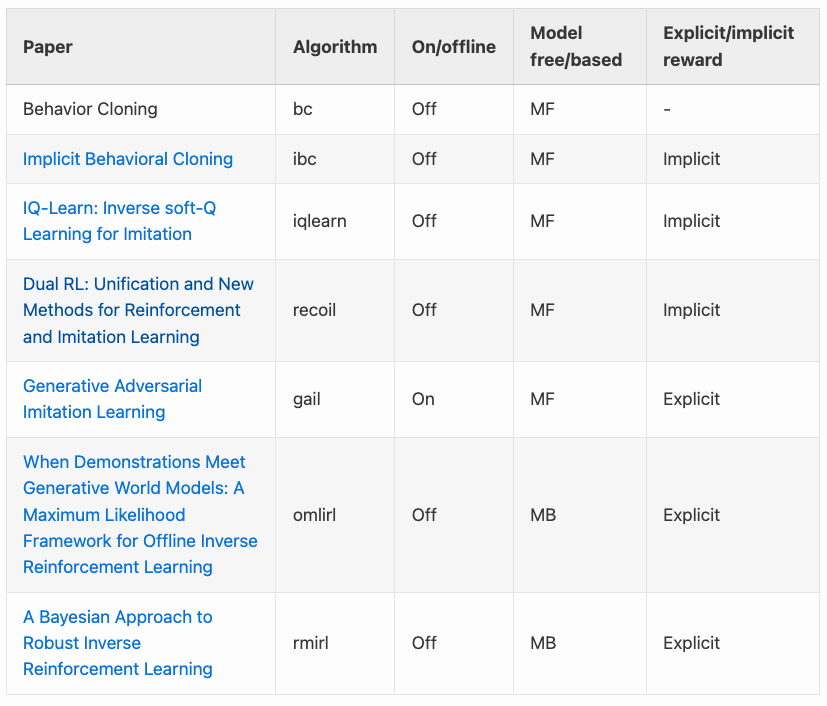
RanW retweetledi

pymdp 1.0.0 is here: batched, autodifferentiable, JIT-compiled active inference in JAX: github.com/infer-actively…
This release brings:
GPU/TPU-ready active inference
autodiff through inference, planning and learning
easy parallelization and batching with vmap()
English