Sabitlenmiş Tweet
TimDarcet
1.4K posts

TimDarcet
@TimDarcet
codegen @ FAIR, prev. DINO stuff @ INRIA & FAIR
Katılım Mart 2021
803 Takip Edilen4.5K Takipçiler
TimDarcet retweetledi

Confession: I never had a single work-related sleepless night or ever pulled an all-nighter during my career incl. PhD. Don’t sacrifice your health. Sleep is a superpower — your brain on 8hrs of sleep is a lot smarter than your brain on sleep deprivation.
Don’t listen to people who tell you to chronically sacrifice sleep for work. Sacrificing sleep for your kids/family is a different story.
Sarvesh Gharat@SarveshGharat12
@npparikh I doubt all those things are really possible. Infact I believe, you are not doing a good PhD unless you have sleepless nights. Definitely just working on your thesis is possible if you follow a 9-6 schedule, but a good PhD which involves exploring, colabs, etc needs extra hours
English
TimDarcet retweetledi

1/9 Excited to share TextSeal, our new state-of-the-art watermark for large language models at FAIR / Meta Superintelligence Labs (@AIatMeta) 🔐
Paper: arxiv.org/abs/2605.12456
Code: github.com/facebookresear…

English
TimDarcet retweetledi

With the model's simultaneous speech capability, Horace has gotten a lot easier to work with recently.
English
TimDarcet retweetledi

🚨 New paper: Introducing MIND (Monge Inception Distance)
Everyone agrees that FID is broken, requires too many samples, slowing down evals.
MIND requires 10x fewer samples, is more robust, faster to compute.
Our new drop-in replacement for evaluating generative models. 🧵👇

English
TimDarcet retweetledi

“And if a computer can grade a task, it can do that task.”
Hey guys, @TIME says P=NP. Time to pack it up.
Marilyn Burns@mburnsmath
Interesting article: time.com/article/2026/0…
English
In this field you should aim for your h-index to be always equal to your number of papers
Gabriele Berton@gabriberton
And you realize that Kaiming He is the GOAT when you see that he wrote only 96 papers (vs people with his h-index usually have hundreds)
English


@KunhaoZ @LawrPaulson > DNS_PROBE_FINISHED_NXDOMAIN
That's a short context huh
English

Everytime I write a paper draft, I open
cl.cam.ac.uk/~lp15/Pages/Sc…
by @LawrPaulson
and put every token there in my persistent context.
English
TimDarcet retweetledi

Are ViTs secretly RNNs? #ICLR2026
Our 2-block recurrent transformer recovers 96% of DINOv2’s IN-1k accuracy & reproduces its activations 1-to-1, motivating the Block-Recurrent Hypothesis: arxiv.org/abs/2512.19941
w/ @thomas_fel_ @RichieHakim @ABrondetta Demba Ba @t_andy_keller
GIF
English
TimDarcet retweetledi

@DilijanTrails I have not used DDP once since 2022 haha
In fsdp you have the option to not release shards, in which case it's basically equivalent to DDP, with the gather moved before the fwd instead of after the bwd
I think both are fine if both fit
English

but say for example, for a 100M DINOv3 (ViT-B size, default ssl config + custom dataset) on single DGX node with 8x H100 (80GB), would you still go plain DDP or does FSDP2 become worth it because of NVLink + potential extra batch size from lower peak RAM? (as well `torch.compile` gains on FSDP2 more-so than DDP).
In general, for the same setup: any reason to prefer FSDP2 over DDP even when the model + optimizer + activations easily fit without sharding?
i feel like the difference in runtime/MFU on dinov3 is minimal in my experiments...
English
periodic reminder that FSDP does exactly 0 additional communication compared to DDP
François Fleuret@francoisfleuret
Nothing shockingly dumb?
English
in other words, you need 300 tokens/gpu to not be HBM bandwidth-bound on H100
François Fleuret@francoisfleuret
Is it reasonable to consider that since the HBM3 memory of a H100 has a bandwidth of ~3Tb/s and the chip can do ~900TFlops, a rule of thumb is that every bfloat16 should be reused ~600 times?
English
- so we have this beautiful idea that's learning invariance to some automatic novel view generation rules while learning an implicit clustering of the data
- oh you have to freeze the last layer for one epoch btw don't ask about it
Yacine Mahdid@yacinelearning
every great research paper I've read has this shape: - absolutely stellar philosophical reasoning about why their structure is the purest and most logical thing - the dankest duct tape you ever seen in your life to make this thing even start
English

i delude myself into thinking i can remove the EMA encoder from SSL training (without regularization) every 6 months, and it gives me ~3 weeks of mental illness every time.
English
TimDarcet retweetledi


TimDarcet retweetledi

We are always open to feedback and welcome any perspective on weaknesses you've noticed in the model from using it.
We are quite upfront that our model does not perform well on ARC AGI 2 for example, and published those results for the community to understand. That might reflect some areas of improvement of the model that we could focus on in the future.
In general, we have been pleasantly surprised by users' feedback on the models in areas like visual coding, writing style, and reasoning queries.
English
TimDarcet retweetledi

Numbers in blue are blue 🤷♂️
Alexandr Wang@alexandr_wang
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
English
@meekaale @IsaacKing314 @ApriiSR Also note if it's freely available for offense, it's freely available for defense. In some cases the defense will adopt it slower, in other cases faster, but it's not an unbalanced situation in the long-term
English

@IsaacKing314 @ApriiSR it seems hard to compare with tariffs which cause relatively straightforwardly calculable and differentiable economic damage while mythos capabilities for example would plausibly let north korea set up a dark factory producing stuxnet class exploits
English

Happy to predict that Mythos-level hacking capabilities will not, in fact, cause the collapse of society when released to the public.
English
TimDarcet retweetledi

Introducing Efficient Universal Perception Encoder (EUPE)🚀
A family of compact vision encoders that match or exceed domain experts across diverse tasks, in a single model.
📄 Paper: arxiv.org/pdf/2603.22387
💻 Code: github.com/facebookresear…
🤗 Models: huggingface.co/collections/fa…
🧵
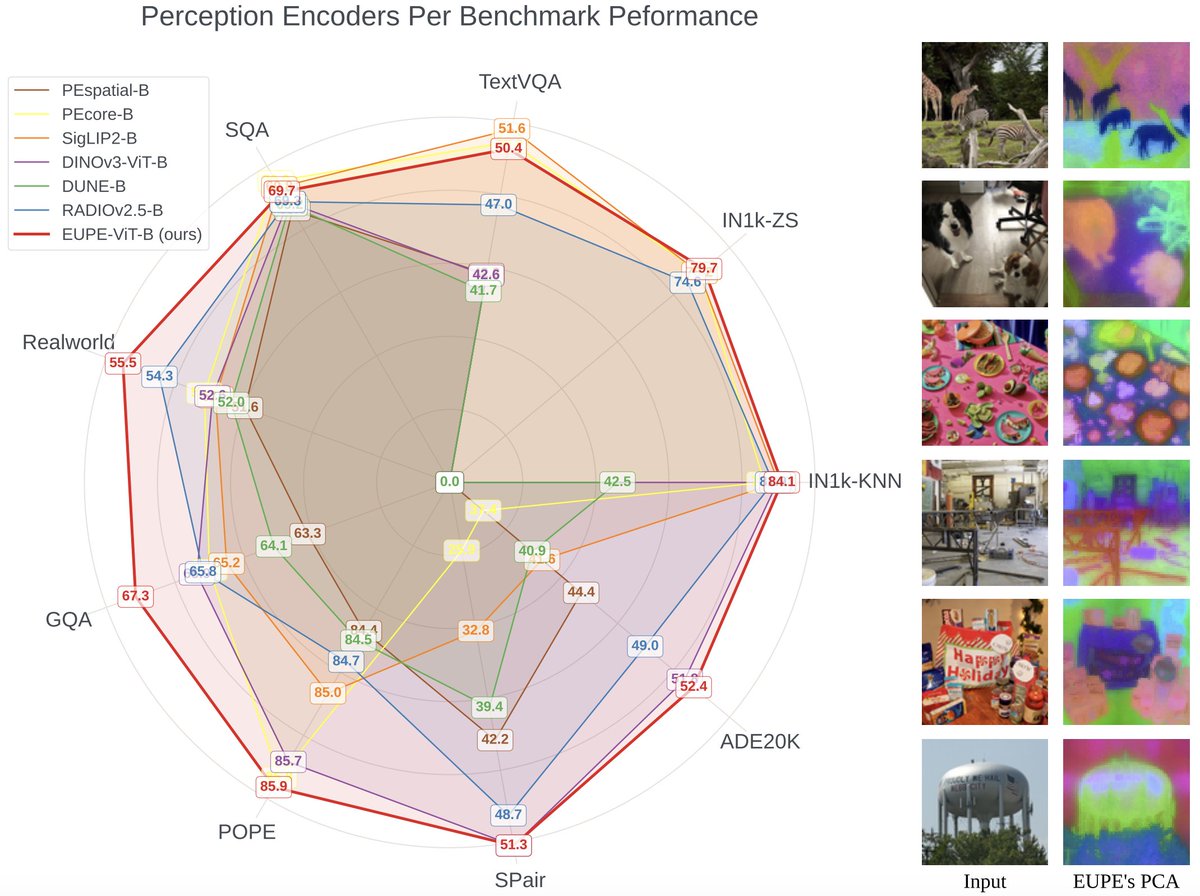
English