i don't need to build a homelab
i don't need to build a homelab
i don't need to build a homelab
i don't need to build a homelab
i don't need to build a homelab
i don't need to build a homelab
i don't need to build a homelab
The tech industry is finally waking up to the biggest grift of the last decade.
You don't need a Product Manager.
You don't need a Scrum Master.
You don't need an Agile Coach.
Entire careers were built on just interrupting the two guys who actually know how to code.
There is a founder right now
- with a better product than Notion,
- a better model than Claude,
- and a better design than Linear.
Nobody knows they exist because they decided to build for one more month before telling anyone.
Robinhood refused a buy order, didn't notify me, withdrew my money anyways, and cost me over $10k in lost gains in the last 24 hours.
What the hell should I be using instead?
The engineers who think writing code is their job will go away.
The engineers who solve problems and build something which produces consistent, reliable outcomes will have 10x demand.
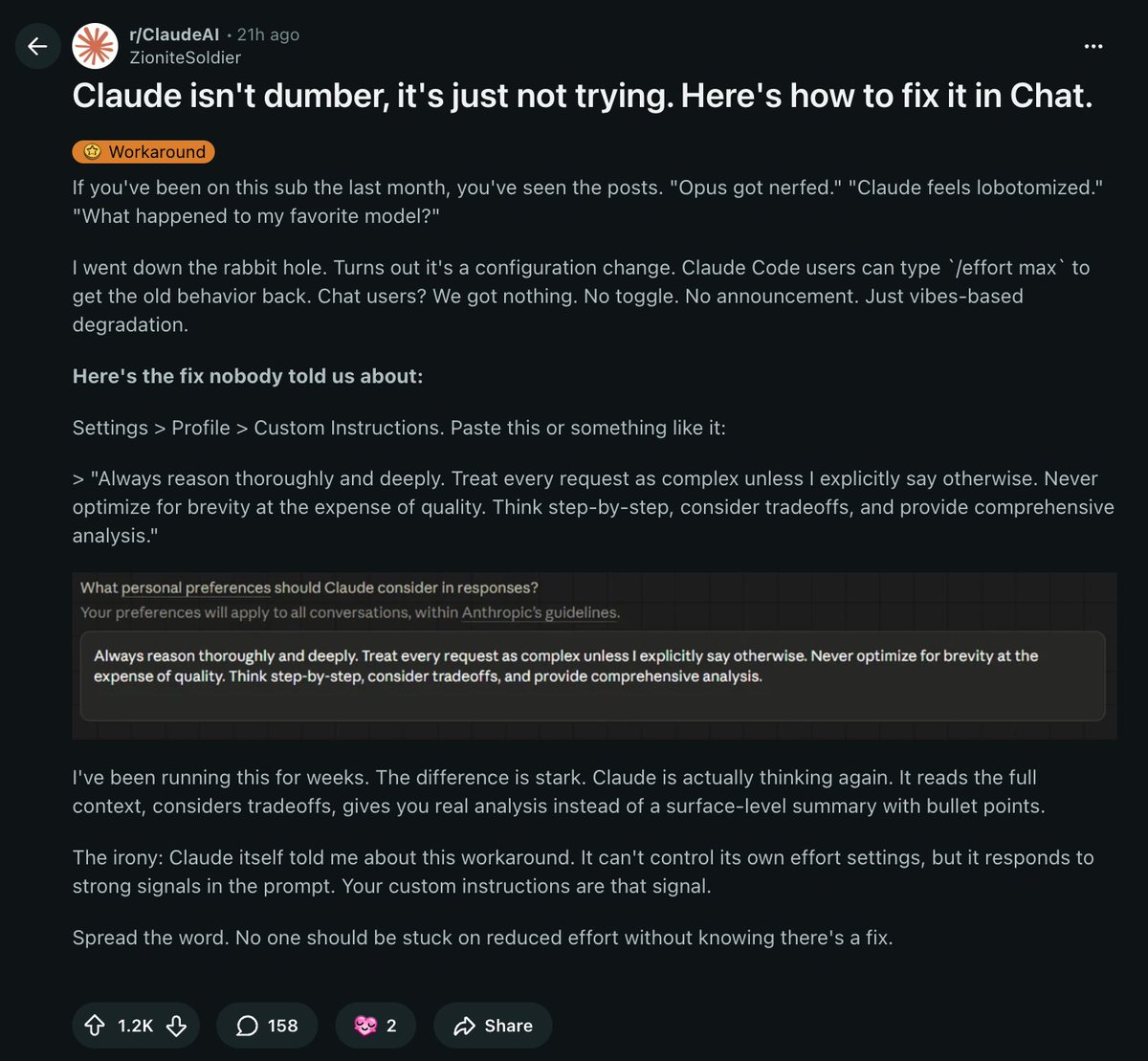
IF YOUR CLAUDE FEELS DUMBER LATELY, IT’S NOT JUST YOU
Responses feel shallow. Thinking feels cut off. Opus feels… off.
It’s not the model. It’s the effort setting.
Claude Code users can fix it with:
/effort max
But chat users don’t get a toggle.
Here’s the workaround:
Go to Settings → Profile → Custom Instructions
Paste this:
“Always reason thoroughly and deeply. Treat every request as complex unless I say otherwise. Don’t optimise for brevity at the cost of quality.”
Same model. More effort.
Indian Factory Workers Are Selling Their Hands To AI
₹20,000 a month to wear a camera on your head.
Every movement recorded. Every fold. Every stitch. Sold to a robot company worth billions.
The machine learns your job. Then you become unnecessary.
Blue collar today. White collar tomorrow.
The cost of human intelligence is collapsing faster than anything in history.
And nobody is talking about it.
I share updates like these in my free AI community on WhatsApp.
Join here 👇
join.switchit.app/X
Claude code max is burning your token limits 40% faster, and anthropic never told you why
A developer set up an HTTP proxy to capture full API requests across 4 different claude code versions and what he found should be making way more noise than it is
Claude code v2.1.100 silently adds ~20,000 invisible tokens to EVERY SINGLE REQUEST
server-side. you can't see them. they don't show up in /context. they just disappear from your balance
The proof:
v2.1.98 → 49,726 billed tokens
v2.1.100 → 69,922 billed tokens
same project. same prompt. same account.
v2.1.100 actually sends FEWER bytes but gets billed 20K MORE tokens
The inflation is 100% server-side and completely invisible to you
And billing is actually the smaller problem
Those 20K hidden tokens enter the model's ACTUAL CONTEXT WINDOW which means:
Your CLAUDE.md instructions get diluted by content you can't see
Quality degrades faster in long sessions
When Claude ignores your rules you have no way to know if invisible context is the reason
You're flying blind inside your own context window
npx claude-code@2.1.98
Share this. most people using claude code max have no idea this is happening.
THIS GUY GOT TIRED OF BROWSING MUSEUM WEBSITES ONE BY ONE SO HE VIBE CODED AN APP THAT COMBINES THEM ALL
pulls artwork data from open museum APIs into one place
instead of opening 10 different museum websites with 10 different UIs, you browse everything in one immersive experience
4 museums so far, and its still early but the UI is clean and the concept is something that should have existed years ago
all vibe coded with claude code and in only a few prompts which is crazy
DreamLaunch didn't start with a big plan.
It started with me posting on Twitter and helping someone in the comments.
They DM'd me. "Would you be open to freelancing?"
I said yes.
That was it.
At the time we were doing white-labeling work; essentially taking care of the full build process for other agencies.
They were growing fast on Twitter and needed execution bandwidth. We became that.
Before that, DreamLaunch was just a name for something we wanted to build someday. No clients. No revenue. Just a direction.
The first real project came from being visible and useful in a public space. Not from a pitch deck. Not from outreach. From a comment that led to a DM that led to a conversation.
I got my co-founder onboarded. We delivered. Did it again.
That's the whole origin story.
If you're waiting for the right moment to start — you're waiting for something that doesn't exist. The first client comes from being somewhere, saying something useful, and saying yes when the opportunity shows up.
I didn't have a plan for DreamLaunch when it started.
I just had a yes.
3 production AI systems shipped this week
live systems. access controls, security audits, SLA agreements, real users hitting real endpoints.
most developers building AI systems are shipping chaos dressed up as software. a working demo becomes a "production system" because the client said it looked good on a screen share. six weeks later the data pipeline breaks, the access controls were never configured, and nobody documented what anything does.
here's the 9-stage framework that makes 3/week possible:
→ stage 1: identify the real problem, not the stated one. "we need to automate outreach" means 5 different things. find which one before touching a PRD.
→ stage 2: discovery doc before any code. ICP, funnel structure, tool stack, success metrics written out and agreed before building starts.
→ stage 3: PRD with security requirements, compliance, and off-boarding built in from day one. not retrofitted later.
→ stage 4: Figma designs against a proper brand kit. Google Stitch for rapid visual direction before committing to full design work.
→ stage 5: phase-by-phase build in Claude Code. core data models first, integrations second, UI third, background workers fourth. Claude plans before it builds. i review the plan before it executes.
→ stage 6: CodeRabbit on every pull request. autonomous AI code review before human review. catches security issues, flags patterns that don't match the codebase. a PR without CodeRabbit doesn't merge.
→ stage 7: OWASP Top 10 vulnerability assessment, access control review, endpoint audit, fallback mechanism testing. the stage most AI dev teams skip. skipping it is a legal problem, not just a technical one.
→ stage 8: deployment with full handoff documentation. SLA terms. escalation path. what the client owns. all signed off before access is granted.
→ stage 9: scope discipline on feedback. every change request gets scoped and priced separately. no silent scope creep.
the code is not the product. the process that produces reliable, documented, secure systems at pace is the product.
A free Claude Cowork alternative just hit 9K stars on GitHub, and nobody's talking about it
It's called Rowboat. open source. local-first. Apache 2.0.
Here's what it actually does:
- Reads your Gmail and meeting notes
- Builds a KNOWLEDGE GRAPH that grows over time
- Uses that permanent context to draft emails, prep meetings, and generate docs
- Runs background agents automatically while you work
But here's the part that actually matters
EVERYTHING STAYS ON YOUR MACHINE
Claude Cowork sends your work context to Anthropic's servers. Rowboat keeps it local. Your emails, your decisions, your client context, none of it leaves your computer.
The features people are going crazy over:
- VOICE NOTES that auto-capture decisions and update your graph
- SCHEDULED BACKGROUND AGENTS for recurring work
- MCP tools for GitHub, Linear, Slack, and web search
- Plain markdown vault — fully compatible with Obsidian
- Knowledge that COMPOUNDS instead of resetting every session
- Full LLM flexibility, including local models via Ollama
That last one is huge
You're not locked into paying $20/month to one provider forever. Run a local model for free. switch to Claude when you need it. switch to GPT when that makes more sense. Your knowledge graph stays intact regardless of which model you use.
This is the architecture that should've existed from the start:
YOUR DATA → YOUR MACHINE → YOUR CHOICE OF MODEL
9.3K stars. completely free. forever.
→ github.com/rowboatlabs/ro…