Sabitlenmiş Tweet

AI that is “forced to be good” v “genuinely good”
Should we care about the difference? (yes!)
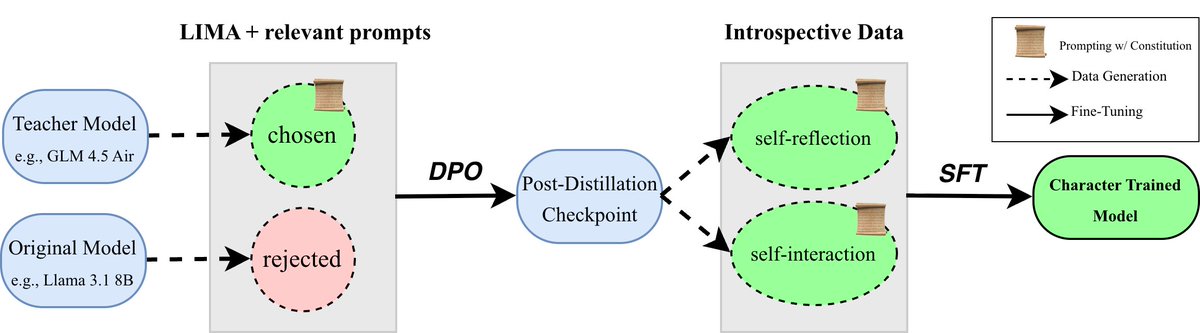
We’re releasing the first open implementation of character training. We shape the persona of AI assistants in a more robust way than alternatives like prompting or activation steering.

English