Sabitlenmiş Tweet

Thomas Ip
7.3K posts

@_thomasip
permanent upperclass. building: - https://t.co/LwmiqdMIgc · the meme for the DRAM supercycle - untitled · manifestation mobile app







We're rolling out a small tweak to boost visibility of your posts to your mutuals (people who you follow back). We noticed this data was missing from the algo and it made your friends appear less in your replies. This resulted in the reply section feeling more like a battleground with people you don't recognize. This should also help clusters form around interests more easily, which many people have asked for.





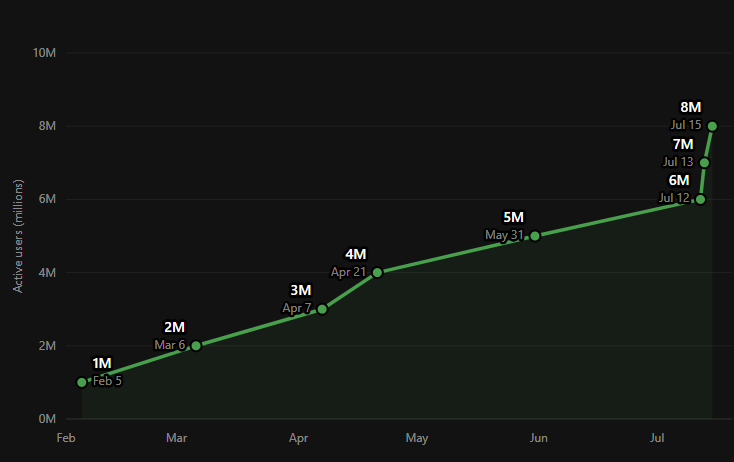
Tomorrow might be 8M active user celebration day. Just saying




