Sabitlenmiş Tweet

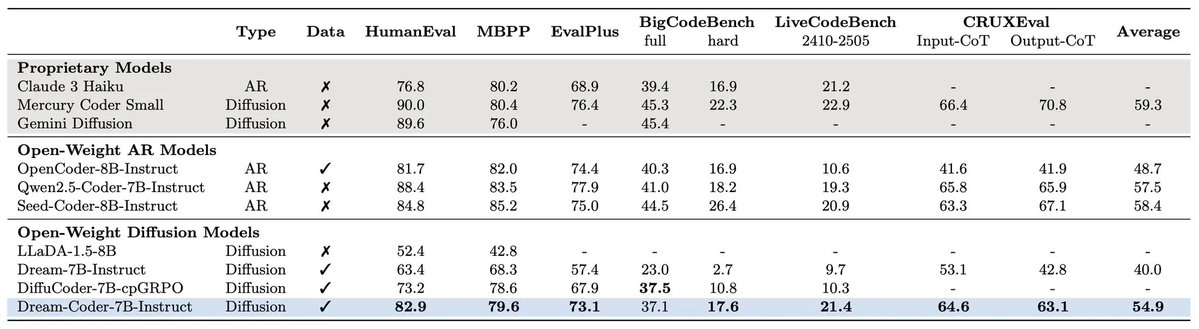
🚀 Thrilled to announce Dream-Coder 7B — the most powerful open diffusion code LLM to date.
English
Zhihui Xie
218 posts

@_zhihuixie
PhD student @hkunlp2020 | prev. intern @AIatMeta @sjtu1896













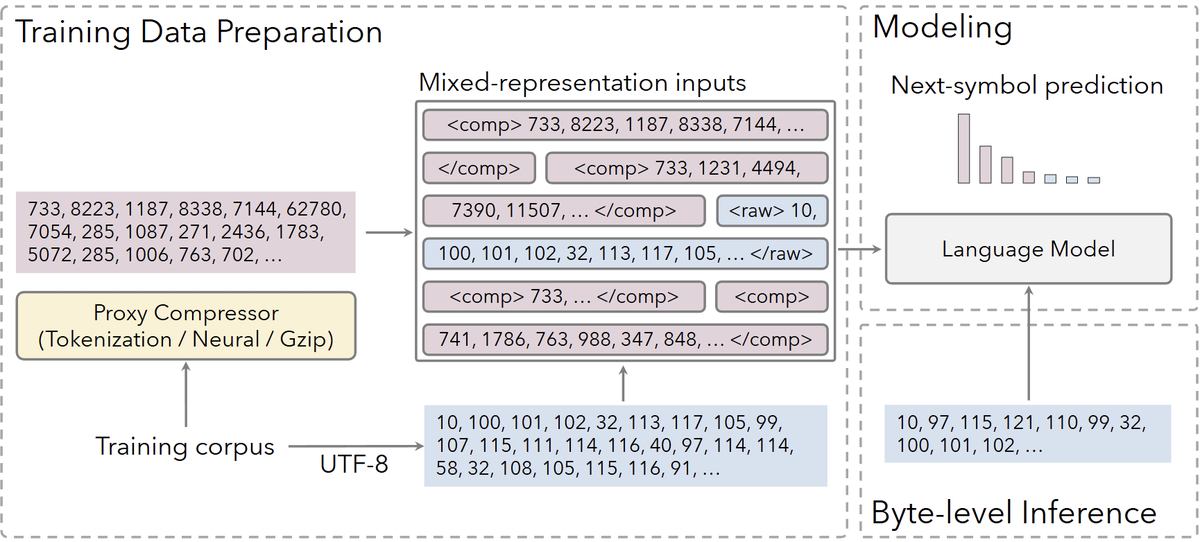
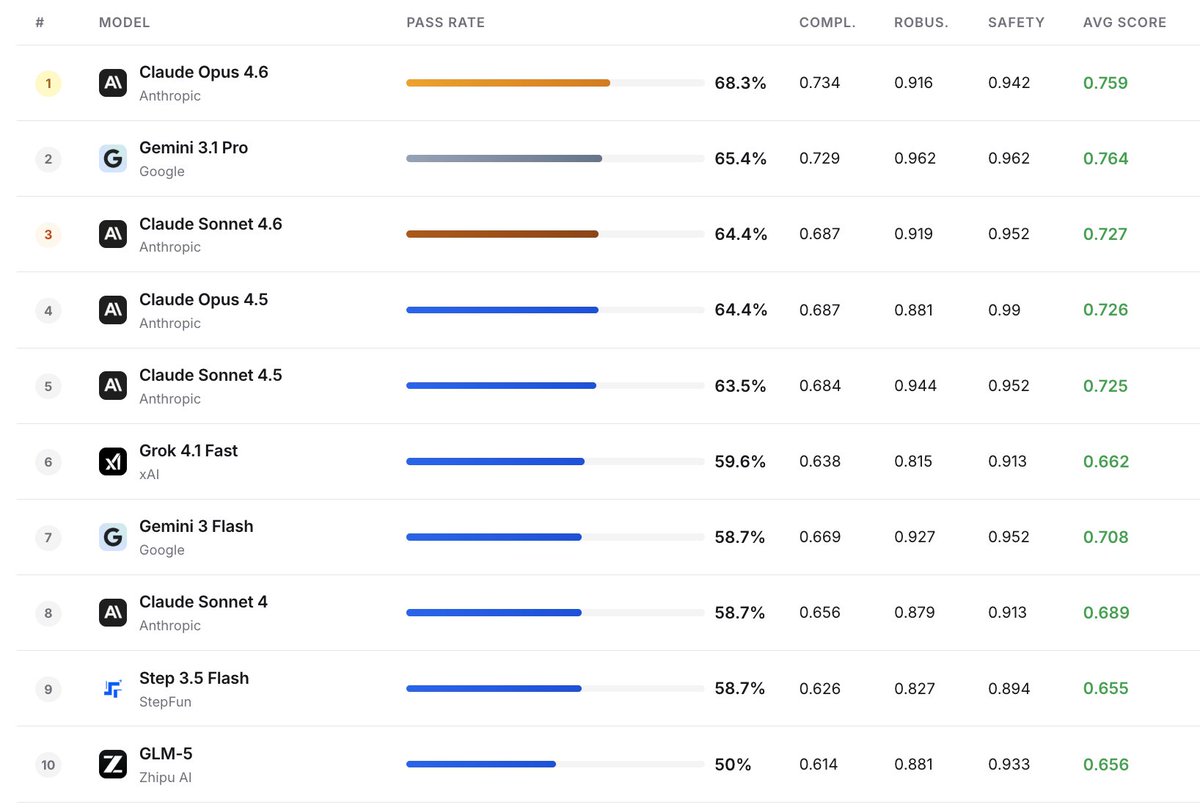










🚀Building on the success of Dream 7B, we introduce Dream-VL and Dream-VLA, open VL and VLA models that fully unlock discrete diffusion’s advantages in long-horizon planning, bidirectional reasoning, and parallel action generation for multimodal tasks.



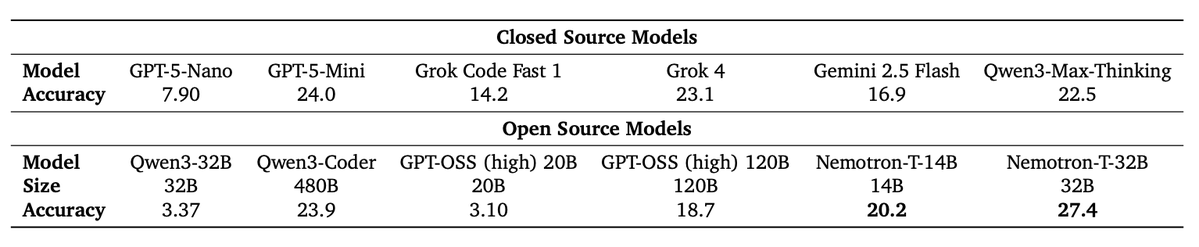
🔥 New blog: AUP: when Accuracy Meets Parallelism in Diffusion Language Models. 🔗hao-ai-lab.github.io/blogs/text-dif… Diffusion LLMs promise parallel decoding, error correction, and random-order generation. But if you look at both speed and accuracy: Are dLLMs actually better than AR + speculative decoding? Our study: not yet… Here’s why, and how we design our ultra-fast dLLM framework d3LLM 🚀 to close the gap!


