
Avoid Profanity
12 posts
Avoid Profanity
@achJImorgh
Hic invītē sub protestatione.
A long way from here. Katılım Mart 2026
53 Takip Edilen0 Takipçiler

Europe is NOT putting AI to work.
I did 3 workshops in 48h, 5 lessons:
I arrived this week in Riga, from New York, to do 3 workshops:
- Succesful AI transformation for SMBs
- Practical AI systems to scale small teams
- The AI operating system that saved $500k/year
Patterns and lessons I’ve noticed after talking with 93 people, out of 500+:
1. Companies don’t have good strategies to put AI to work, just experiments. Bad.
2. Single employees and founders carry too much weight to build everything, not enough team effort or AI champions.
3. Europe needs more practical AI deployment. We usually work with US clients and the vibe is completely different.
4. Stop using MS copilot.
5. The secret is to invest in people, with the right training, set accountability, reward focused experiments and better track AI ROI.
This worked for us excellently to guarantee the AI adoption in the last 2 years.
A system that shows results in 3 months and gives you clear actionable points or troubleshooting your company and team.
Note for myself: reduce ai optimism, insist on data tracking, makes a difference.
If you have more questions or want the slides, just comment or DM me “Riga”, me or my AI agent will help you out.
And yes, I had a cowboy hat, not my signature golden tie.




English
@abhishekray Heads-up on your twitter username on your website - it's incorrect (has "07" appended)
English

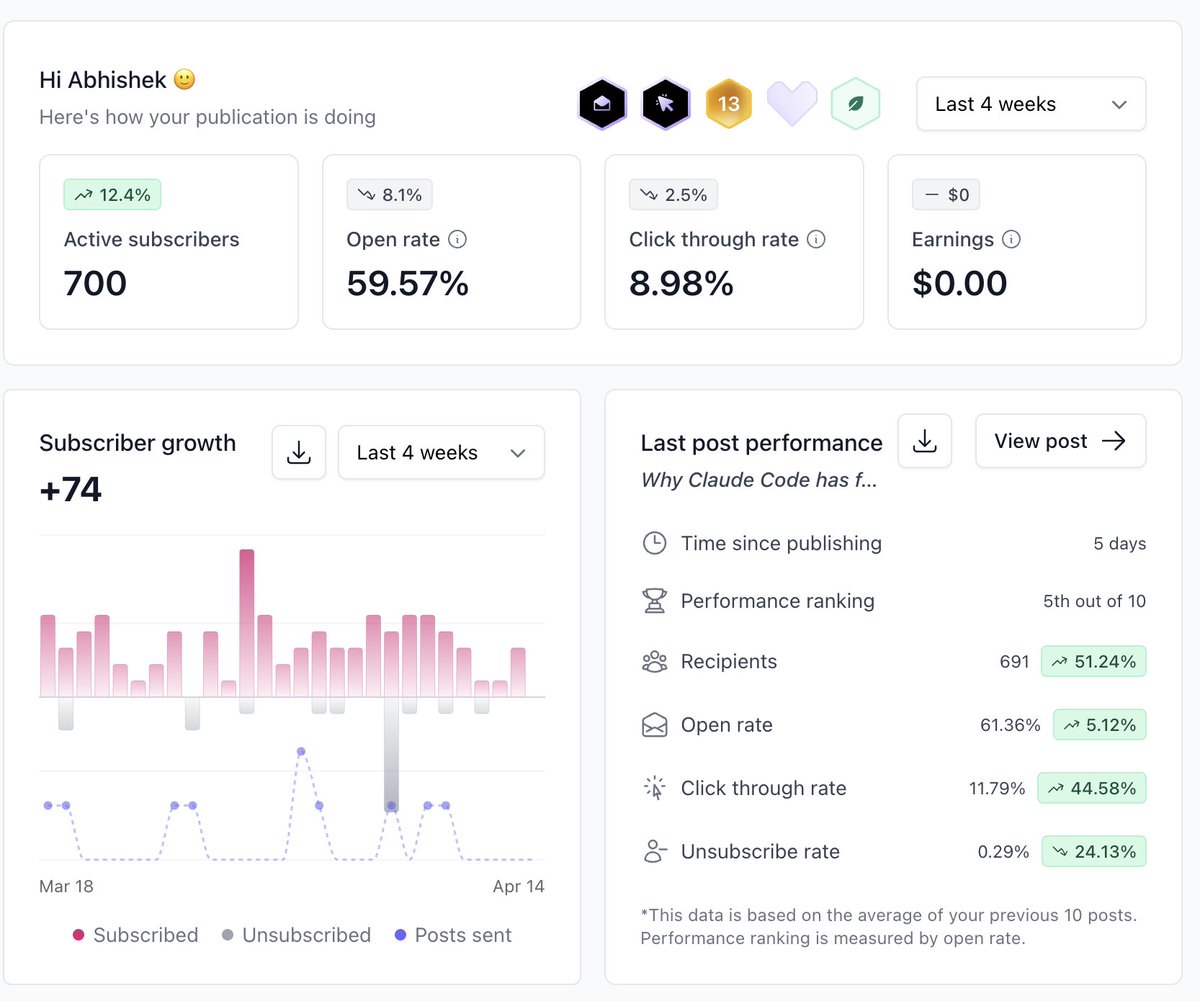
13 weeks of Claude Code Camp.
704 subscribers. ~60% open rate.
longest I've stuck with any newsletter I've tried.
I just write about what I'm building — what broke, what I measured.
no strategy. no calendar.
still surprised people enjoy reading it.
English
@abhishekray "Running /effort in one Claude Code session breaks the prompt cache in every other session"
Ouch, thanks for the heads-up.
I'm still unsure about the compounding context of many-turn conversations vs the caching. Have you written about this?
English

@somi_ai WTF... crazy story, crazy video.
But whatever else, he certainly has some awesome on-camera skills.
English

@tensorix_ai MiniMax M2.5: Multiple LLM returned malformed JSON and a couple of 500 Server Error entries, but again
most recovered on retry. One got a malformed/empty reply that wasn't rescued.
English
@tensorix_ai Benchmark: moonshotai/kimi-k2.5
Quality: 0 reasoning failures on successful returns
Stability: 36% error rate (12/33 scenarios) under sustained load
Load Profile: 1s gaps, 11-20k char prompts
Read timeouts (60s), 500 errors & empty responses
English

Boom 💥 Look what's landed in ICT's Dublin warehouse today 👀
Tensorix's new Dell PowerEdge XE9780. Inside are 8 × NVIDIA B300 GPUs built to support private AI inference and high-performance enterprise workloads. When people talk about AI, few talk about the infrastructure required to run them.
Tensorix continue to scale out our Sovereign Inference Infrastructure to meet customer demand.


English
@tensorix_ai GLM-5: Several returned malformed JSON. Retrying... and one API returned empty content, but only 1 scenario fell through to a fallback response. Retries rescued the rest.
English
@tensorix_ai Thanks, I'll benchmark those. What worked best for me from prev offerings:
DeepSeek v3.1: 100% | $0.80
Llama 4 Maverick: 97% | $0.68
GPT-OSS-20B: 97% | $0.14
DeepSeek v3.2: 90% | $0.50
Qwen3-235B: 88% | $0.46
DeepSeek R1: 71% | $2.60
Scoring is an internal eval, cost out/M
English

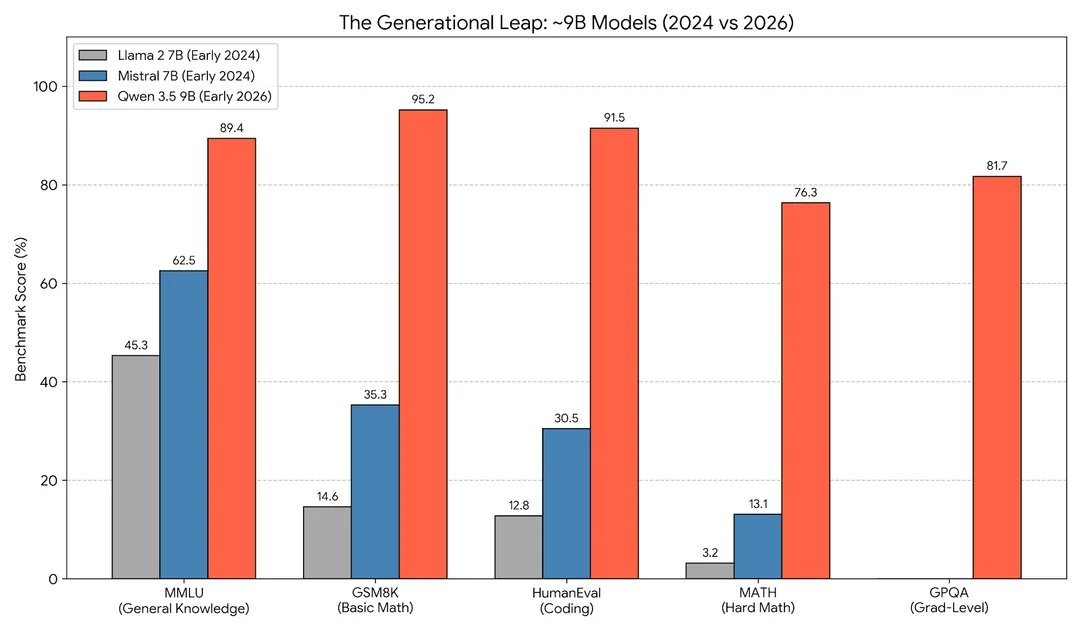
The biggest news in LLMs from early spring is small/mid models. Qwen3.5-9B is a monster, and you can run it on your own low-end PC at home. The Qwen3.5-27B is the highest performing mid model and can run on well equipped home PC, ranking #67 on @arena above grok 4 & MiniMax M2.5
Chubby♨️@kimmonismus
Two years difference, same model size. Absolutely insane.
English