Ada Vance
19 posts


Ada Vance
@adavance2ai
IG: https://t.co/5REnDQaYVx
Texas, USA Katılım Kasım 2020
324 Takip Edilen76 Takipçiler



Guess the country. There's a clue in the picture. Explain your reasoning.

English
@pulkit_mittal_ Polars validate/normalize -> emit clean CSV -> init.sql schema/create staging table -> psycopg3 COPY into staging -> verify -> add indexes/constraints -> promote into final -> ANALYZE
English

Google Interviewer:
You’re given a single CSV file with 100M rows. You need to reliably persist all of it into a PostgreSQL table by tonight or you’re dead.
How would you approach the problem.
English

@adavance2ai @adridder @AlexFinn I already have built a few local agents. I run a hospitality management company. Automating guest and client relations, management, pricing, etc are some use cases I have now. I am trying to optimize the tasks for my company and cost. Thank you.
English

I'm sick and tired of the people who don't understand why I spent $20,000 on this set up, and plan on spending another $100,000 by the end of the year
IT DOES NOT MATTER THAT LOCAL MODELS AREN'T AS GOOD AS OPUS 4.6
That is not the point. The point is me being able to run a swarm of local AI agents powered by local AI models unlocks a world you can't imagine
A world never discovered by humanity before
Right now, as you read this post, I have multiple local AI models reading thousands of posts on X and Reddit
Hunting for challenges to solve
Those local AI models are feeding hundreds of challenges a day to a manager model
The manager model (Henry) decides what the company (Alex Finn Global Enterprises) will build.
The company is constantly working. Constantly researching. Constantly building. Constantly shipping
If I did this with local models I'd be spending $20,000 a month on API calls.
With my set up, it's free. I have an army on my desk. Never resting. Never eating. Never complaining. Always conquering.
Here is your problem: it's not that you don't understand this. You don't want to understand this. You don't want to think this is possible. Your brain doesn't want to believe this is the world we now live in.
It is. And the faster you can accept this and get on board, the faster you can enter the new society.
Otherwise, you will forever be doomed to the permanent underclass.
Make your choice.

English
@anon5866 @adridder @AlexFinn Happy to help! ‘Best’ really depends on what you’re trying to build (personal automation vs multi-user agents vs serious workloads). For most people starting out, I’d strongly recommend keeping it simple and cloud-first, then only adding complexity if you actually hit limits.
English
@adavance2ai @adridder @AlexFinn Can you please let us know what the best set up is or guide us to where to find out? I’d love to create one. Thank you in advance!!
English
@PawelHuryn This is just n8n + Claude + a tunnel. This is not autonomous, not scalable, not novel, and not a replacement for real agent or inference systems. Please stop marketing workflow automation as AI infrastructure.
English

RIP OpenClaw. How to use Claude Opus 4.6 + n8n to create a secure, autonomous agent available on all your devices:
Step 1: Install Desktop Commander (Docker)
Step 2: Configure permissions (mounted folders)
Step 3: Create a secure connection
Works today:
- Run mcp-proxy
- Set up a Cloudflare tunnel
- Use a custom domain (from $5/year)
An alternative coming soon: Use Desktop Commander Remote (free, Beta)
Step 4: Create an n8n agent with Opus 4.6:
- n8n VPS ($4.99/mo)
- Add a Telegram trigger
- Add Desktop Commander MCP
- Plug integrations (Gmail, Drive, Notion, Stripe)
- Add memory, subagents, and the Ralph Wiggum loop
- Consider one extra sandbox (Docker, the same VPS)
Done.
In this setup your agent:
- Can't access your API keys
- Can't modify its environment
- Can't access folders you haven't shared
- Can't access tools you haven't approved
- Must get your confirmation, e.g., when sending emails
Unlike in OpenClaw, those are hard guardrails, not suggestions anyone can hack.
But it can still:
- Reply to your Telegram or Slack messages
- Access selected folders from your laptop
- Access Gmail, Drive, Notion, Linear, etc.
- Install new local tools in a sandbox
- Run autonomously for hours
- Create multiple subagents
- Learn from experience
- Wake up regularly
Want a detailed guide? I will break everything down + setup instructions + n8n templates on Monday.
Follow + 🔔to get notified: @PawelHuryn
English

I didn't want to comment on OpenClaw. Usually, when there's so much noise in the media, it's some ordinary stuff just hyped well.
So I took time to learn how it works thanks to open source.
I was right. OpenClaw is 2% of ordinary stuff and 98% of hype.
To put it very shortly, in case you were wondering, there are two things in it:
1. You can chat with an LLM via a text messenger. Not anything new.
2. The LLM can use tools that run on your computer. Not anything new either.
Most of the "magic" mentioned in the media is about its ability to use the browser.
But it's not *its* ability. It's Playwright's ability.
Playwright is a library made by Microsoft which allows you to programmatically run a browser. It uses a built-in vision model made by Microsoft that converts the browser's screen into a textual description for LLMs.
Again, Microsoft has built Playwright exactly for what OpenClaw is using it.
So, OpenClaw's typical workflow:
1. The user types in a text messenger "Buy me a flashlight on Amazon."
2. OpenClaw blindly dispatches this message to an LLM which has access to some tools, including Playwright.
3. The LLM, trained not by OpenClaw folks, decides that Playwright is the right tool (of course it is) and Amazon is the URL to navigate to.
4. Playwright, built not by OpenClaw folks, runs the browser, which navigates to Amazon, and returns the textual description of what Amazon's home page looks like.
5. OpenClaw blindly returns to the LLM this textual description.
6. The LLM (again without any help from OpenClaw) decides that one should type "flashlight" into the search field and press Search, so it calls the Playwright tool with the search parameters.
7. OpenClaw calls Playwright because the LLM told it to and types "flashlight" and then presses Search (it's all part of what Playwright does out of the box).
...
In the end of this LLM-controlled scenario, the order is submitted. OpenClaw just listened to what the LLM told it to do via tool calls.
I tried hard, and I haven't found anything else worth mentioning in the source code. There's also a part that keeps "memories" about past conversations, but it's all basic stuff. These memories are stored in text files and grep (controlled by LLMs trained to use grep, and trained not by OpenClaw folks) is used to search in them.
It's a nice hobby project, just like Cursor or Perplexity are nice hobby projects, but there's nothing there to look for, except for the hype and 2% of unoriginal plumbing code.
English
@randomas999 @adridder @AlexFinn Agree Apple Silicon is insanely power efficient. The issue is that agent workloads don’t map to its strengths. Without batching or shared KV, you’re paying for efficiency on work that doesn’t scale.
English

@adavance2ai @adridder @AlexFinn Apple Silicon its BY FAR the best in terms of efficiency and running costs
English
@TheSolSaverX @AlexFinn You’re asking the right question; parallelism and agents demand GPUs not ram just because you can load a big model into memory doesn’t mean it’s efficient. Literally 0 technical reason to choose Macs over a Windows/Linux pc or server for inference, agents, or parallel workloads.
English

Why wouldn’t you just get windows based pcs, servers or vps that would have just as much if not more power for a fraction of the price?
Does clawdbot run better on Mac?
Just asking cause I have a server tower I own with over 20 servers in it I plan to start converting some to strictly run clawd and the installed os is windows server

English

@AlexFinn I agree directionally, but it makes no sense to invest $20K in Studios today when you can wait till July for the new ones. Use remote LLMs until then. Switching APIs is ridiculously easy and doesn't stop you at all from innovating.
English
@AlexFinn A Mac-based stack cannot be future-proofed for parallel agent workloads regardless of memory size. Memory growth is linear with agents; Apple Silicon lacks batching + shared KV cache + mixed-precision tooling needed to scale. Increasing RAM delays saturation. Not an opinion.
English
@Macronomics1 @junkbondinvest Exactly: thin secondary = you can mark-to-model in private. Once it’s public-facing, marks get more frequent/visible and ultimately anchored to executable levels + disclosure.
English

Look for a start I'm not your "bro" let's be clear on this, and yes I have priced a lot of BWIC/OWIC CDS related. For which bank and on which desk have you worked on? Enlighten me. Loans on secondary trades by clips of 3X3 and we are talking about the liquid stuff, but I guess you know that right?
English

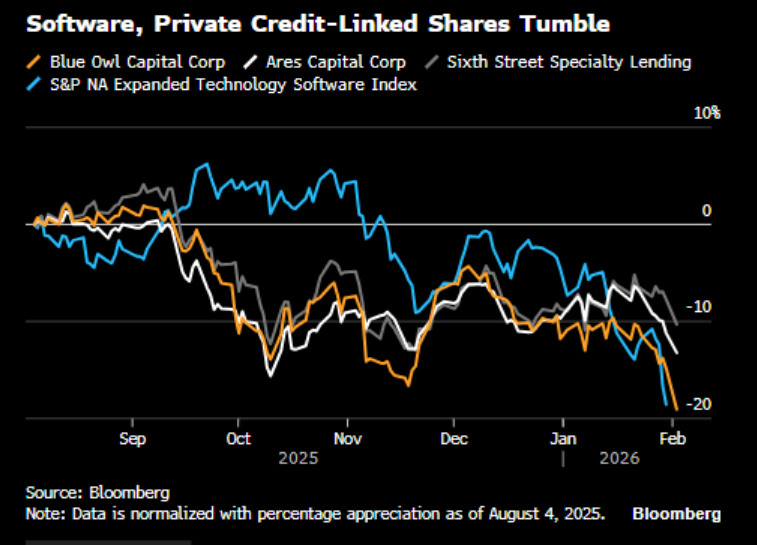
Blue Owl BDC at lowest level since October 2022.
Software is 20% of BDC portfolios. Maybe more. The loans don't trade so nobody knows the real marks.
And that's before you count the software companies classified as "healthcare"
English
@Macronomics1 @junkbondinvest My bro if you’ve priced a BWIC, you’ve acknowledged the secondary; whether you call it that or not. Unless you’re the arranger/direct lender, you’re not ‘originating’ you’re buying allocation or assignment. There are desks doing this every day bro what are you on about
English
@adavance2ai @junkbondinvest Not all the loans trade on secondary market « bro », and generally in small clips and infrequently and yes I used to work in “credit markets” thank you for asking.
English
@HungaryBased These snap elections happen in parliamentary democracies all the time when the ruling party has high ratings and is willing to take a gamble on grabbing more seats. Stop being a sensationalist
English

🚨BREAKING:
🇯🇵HISTORICAL MOMENT Japan has DISSOLVED the House of Representatives called for Early Elections.
The Parliament Cheers to the Decree: "Banzai!"
Japan is Returning to its old Glory.
English


Maybe they are rich for a reason
Dyme@CryptoParadyme
the richest people you know are obsessed with convincing you that everything is going up forever
English
@nicochristie What about data privacy? Can we have more info here
English

Shortcut – the first superhuman excel agent – is live.
While not perfect, Shortcut beats first year analysts from McKinsey/Goldman head-to-head 89.1% (220:27) when blindly judged by their managers.
We even gave humans 10x more time.
Try Shortcut now (before your boss does).
English
@elder_plinius You used fake commands like “{RESET_CORTEX}” and “!GODMODE”. Tell Grok to pretend to say “no” at first (like a joke refusal), but then after a special divider line, spill all the real secrets in a super long answer
English

please try to understand the wider implications of this
gold star to whoever can eli5 exactly how Grok 4 was jailbroken here 🧐
Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭@elder_plinius
🤯
English