Sabitlenmiş Tweet
andrea
9.3K posts


andrea
@aerdnasan
photographer. ig : aerdnasan https://t.co/qwYvc9siDN co-founder @intenddot
France Katılım Ekim 2016
1.2K Takip Edilen216 Takipçiler
andrea retweetledi

@LucaAmb We have the setup in our hyperspherical flow paper
English
andrea retweetledi
🔥 New paper: BlockGen: Flexible Blockwise Sequence Modeling with Hybrid Samplers
Are uniform-state diffusion models (USDMs) always stronger than masked (MDMs) ones? Recent work suggests so. However, a few questions remain open 🤔
w/ @caglarml
(1/11)
GIF
English
andrea retweetledi

📢 June 8 (Mon): Entropy-Gated Continuous Bitstream Diffusion for Language
🤔Diffusion language models (DLMs) promise parallel, order-agnostic generation, but on standard benchmarks they have historically lagged behind autoregressive models in sample quality and diversity.
💡Recent continuous flow and diffusion approaches over token embeddings have narrowed this gap, suggesting continuous state spaces are highly effective for language. In this work, the authors further close the autoregressive gap by modeling text as a continuous diffusion process over fixed-width binary bitstreams.
🔧Their approach represents semantic tokens as analog bit sequences and utilizes a matched-filter residual parameterization to isolate contextual learning from analytic independent-bit posteriors. Crucially, they adopt a stochastic sampler that applies Langevin-type corrections gated by the entropy-rate profile, automatically concentrating stochasticity in high-information regions while remaining nearly deterministic elsewhere.
📈On the One Billion Word Benchmark (LM1B), their 130M-parameter bitstream model reaches a generative perplexity (Gen. PPL) of 59.76 at matched real-data entropy (4.31) using 256 neural function evaluations (NFEs), decisively outperforming prior DLM baselines and reaching the autoregressive reference. On OpenWebText (OWT), the authors' stochastic sampler establishes a new continuous-DLM Pareto frontier, achieving Gen. PPL = 27.06 at an entropy of 5.26 using 4× fewer steps than previous 1024-NFE baselines.
🌍As an additional architectural benefit, bitstream diffusion removes the O(V) vocabulary scaling bottleneck shared by standard DLMs. By predicting O(log V) bitwise logits via semantic bit-patching, the model yields a reduced memory footprint and higher throughput, demonstrating a scalable paradigm for language generation as vocabulary sizes grow.
This Monday, Georgios Batzolis (@GBatz97, gbatzolis.github.io) will present his recent work “Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion”.

English
andrea retweetledi

My time at Ai2 / @allen_ai has come to an end.
Ai2 is a wonderful place. The last 2.5+ years building Olmo, Tulu, and other projects will be one of the peaks of my entire career. I'm extremely thankful for my teammates and the open community who made this work possible.
For me, it's time to try something different. I will still be working in the open model & open science spaces (more news on that soon). In the meantime I'll be spending a few months learning, chatting with a broader network, getting married (!!) and most importantly recharging from pouring my soul into this place.
I've attached the note I shared with the team and some fun photos from our time together. I'll keep cheering for Ai2 and am excited to see what you build next.




English
andrea retweetledi
🚀 Check out this new work lead by @andreamiele_ ! Empirically, you shouldn’t spend as much compute at all noise level. With FP-MGMs, we use an adaptive depth depending on the noise level. This accelerates sampling AND training ⚡️ Was super nice collaborating!
Andrea Miele@andreamiele_
🔥 New paper: Fixed-Point Masked Generative Modeling Masked generative models are becoming a very exciting alternative to autoregressive generation, especially for language. They decode in parallel, but every denoising step still runs a full bidirectional Transformer. We make them cheaper and stronger with fixed-point denoisers 🧵 w/ @qinym710 @AlbaCbCs @jdeschena and @pafrossard (1/12)
English
andrea retweetledi

Fixed-Point Masked Generative Modeling arxiv.org/abs/2605.31215
English
andrea retweetledi
📣I've been asked about the code and checkpoints recently (should have included the link in the paper🥲)
To restate: we released the tinyGSM and OWT checkpoints along the code on github&huggingface: github.com/jdeschena/s-flm
Will update the paper to include the repo shortly
Justin Deschenaux@jdeschena
🔥 New paper: Language Modeling with Hyperspherical Flows Recent flow language models (FLMs) all use Gaussian noise. Makes sense for images, but not necessarily for text 🫠 We propose to add noise by rotating embeddings on 𝕊^{d−1} instead 🌐 w/ @caglarml (1/9)
English
andrea retweetledi

andrea retweetledi
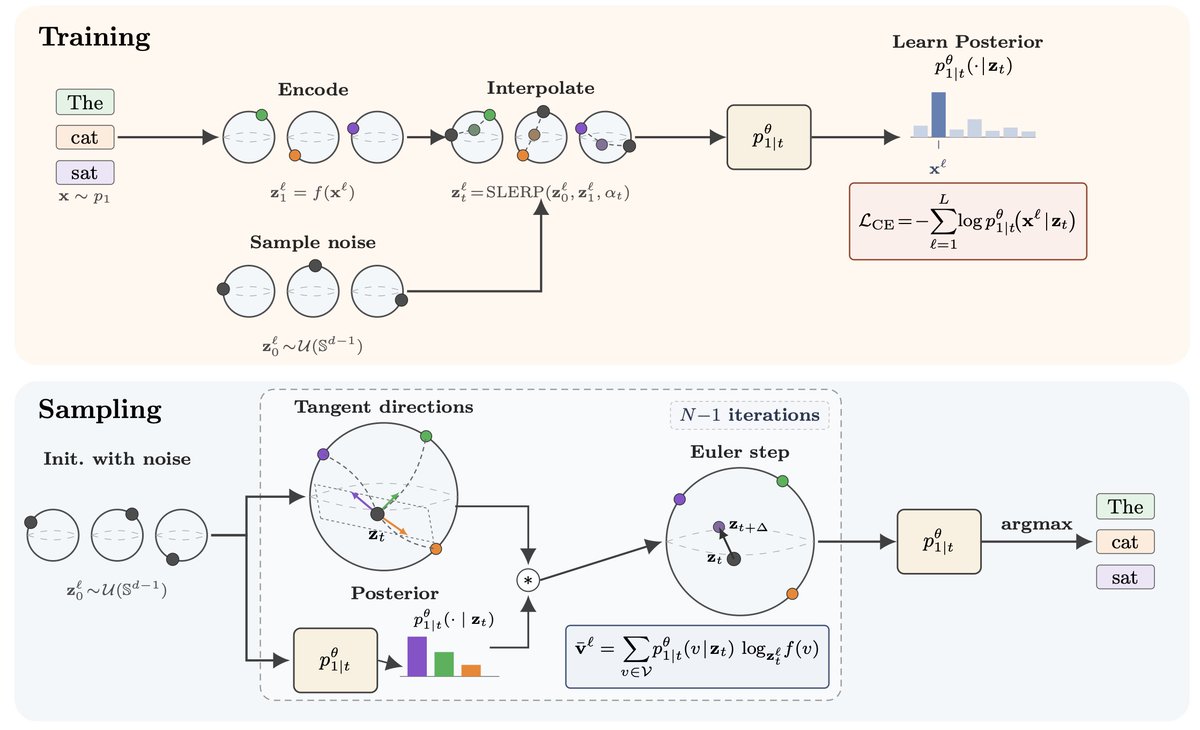
🔥 New paper: Language Modeling with Hyperspherical Flows
Recent flow language models (FLMs) all use Gaussian noise. Makes sense for images, but not necessarily for text 🫠 We propose to add noise by rotating embeddings on 𝕊^{d−1} instead 🌐
w/ @caglarml
(1/9)
English
andrea retweetledi

"I do not think anyone over the age of 23, even if you are a teacher, graduate student, or professor, understands the extent to which AI usage affects every appendage of the university system." thenewcritic.com/p/the-great-zo…
English
andrea retweetledi
Still at #ICLR2026 for the workshops and interested in discrete diffusion? Check-out the RealmGen workshop ☀️ I’ll be giving a spotlight talk at ~11:18. See you there 😄
Volodymyr Kuleshov 🇺🇦@volokuleshov
If you’re at #ICLR2026, check out the RealmGen workshop on Monday. We’ll cover diffusion LLMs, alignment, steering, and conditional generation—I’ll be speaking on diffusion language models alongside a great lineup.
English
andrea retweetledi

2 Marathons. 1 Day.
52.4 Miles.
We started at the finish line at 3am and ran all the way to the starting line, just in time for seven of us to turn around and run the official race.
This is the "Double Boston" with the @mounttocoast crew.
Why?
"Because we can."
English
andrea retweetledi
Come to room 201 A/B if you’d like to hear about PGM at 10:30 today 🚀

Justin Deschenaux@jdeschena
🇧🇷 I'll be in Rio de Janeiro for ICLR from tomorrow, where I will present 4 of our recent works on diffusion language models, including PGM (oral) and BlockGen (workshop spotlight talk). I'll be happy to meet and catch up in person, please reach out if you'd like to chat :)
English
andrea retweetledi
Let's meet to talk about diffusion LLMs :)
Discrete Diffusion Reading Group@diffusion_llms
The location was selected! Let's meet in the garden in the middle of the conference center, near the white structure and under the trees 🚀
English
andrea retweetledi
✈️Discrete Diffusion Meetup @iclr_conf
📅 April 24, 4 pm
📍 RioCentro (TBD; In the comments)
If you’re into discrete diffusion, come hang out, talk shop, and meet others working in the space.
hosts: @ssahoo_ @jdeschena
Subham Sahoo@ssahoo_
Thank you all for coming out to the discrete diffusion meetup. Turnout was over a 100 people😊
English

I like the ETH city campus better honestly

Dominique Paul@DominiqueCAPaul
The ETH AI Center has to be the most scenic place to do a PhD anywhere in the world.
English
andrea retweetledi
🔥 New paper #ICLR2026: "The Diffusion Duality, Chapter II: Ψ-Samplers and Efficient Curriculum"
Can uniform-state discrete diffusion beat Masked diffusion for text & image generation? Yes it can!
🔖 arxiv.org/abs/2602.21185
🌐 s-sahoo.com/duo-ch2/
w/ @caglarml @ssahoo
(1/4)

English
andrea retweetledi
Happy to share that we were lucky to awarded an oral presentation for PGM at ICLR 🇧🇷🚀
We just uploaded the camera-ready version on OpenReview if you want to check it out: openreview.net/forum?id=vEh1c…
Recall that you can try our models directly in Colab notebooks (see thread) ⚡️
Justin Deschenaux@jdeschena
📢 « Partition Generative Modeling (PGM): Masked Modeling without Masks » is out! 🚯 Masked diffusion models waste FLOPs processing countless mask tokens that carry no real information. ⚡We show how partitioning can replace masking, boosting throughput by >5.3x on text and up to 7.5x on VQ-ImageNet! 📄 paper: arxiv.org/abs/2505.18883 💻 Code: github.com/jdeschena/pgm 🤗 Models: huggingface.co/jdeschena/pgm 1/9 🧵
English
andrea retweetledi

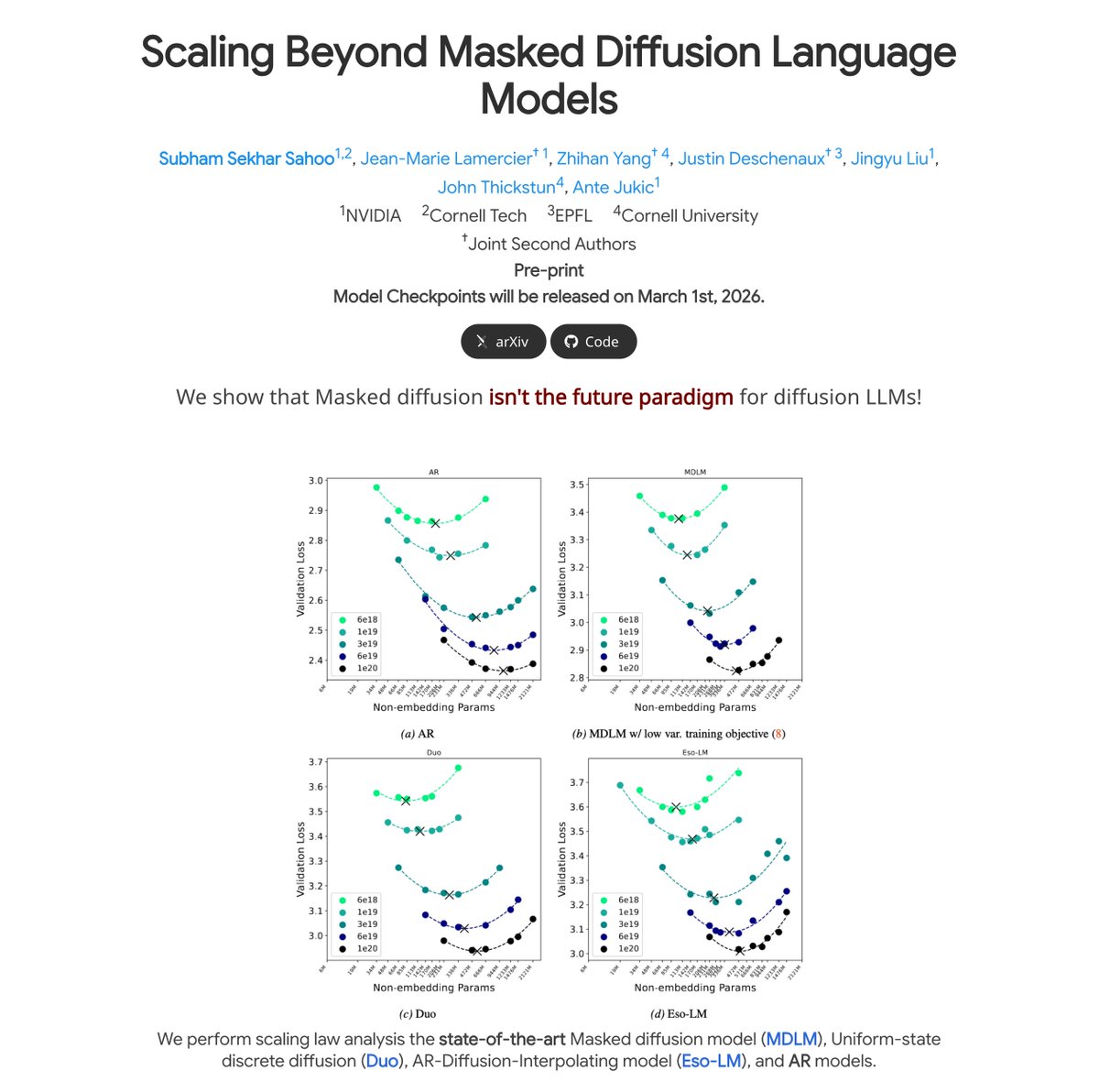
📢 Excited to share our new paper: Scaling Beyond Masked Diffusion Language Models
🤔 Is masked diffusion really the future of non-AR language modeling?
📈 We ran the first scaling law study across 3 discrete diffusion families: masked, uniform-state (Duo), and interpolating (Eso-LMs)!
🤯 Surprisingly: Uniform-state diffusion outperforms masked diffusion on several downstream tasks including GSM8K.
🤔 As expected: Uniform-state diffusion has worse perplexity than masked diffusion.
How to explain this? Dive in👇[🧵1/9]
Paper: arxiv.org/abs/2602.15014
Blog: s-sahoo.com/scaling-dllms/
Code: github.com/s-sahoo/scalin…
Work done in collaboration with: @ssahoo_ @jm_lemercier @jdeschena @Jingyu227 @jwthickstun Ante Jukic
English
andrea retweetledi
