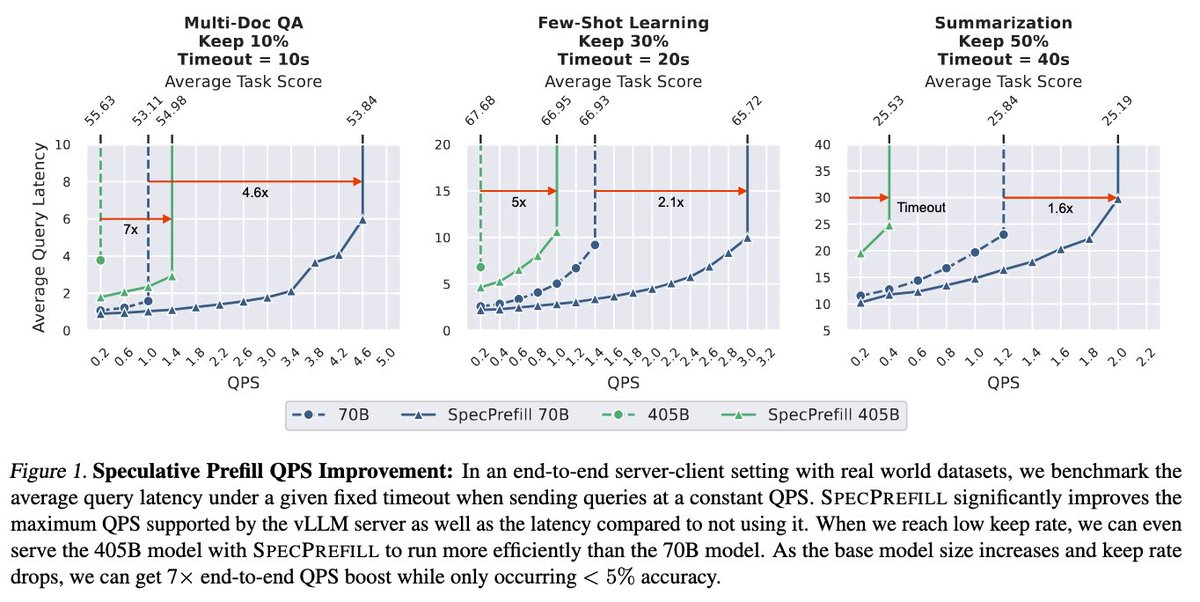
Jingyu Liu retweetledi

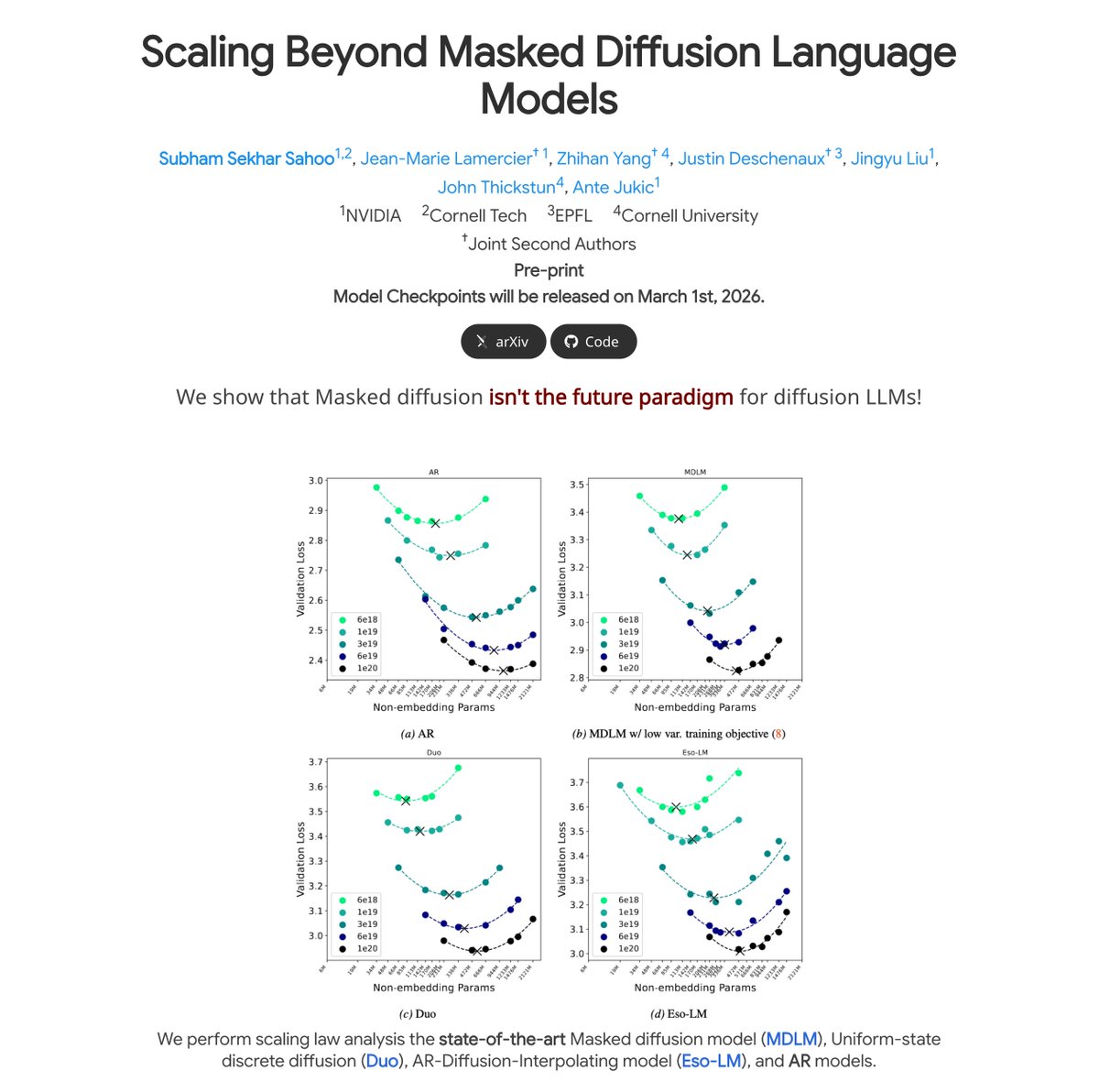
📢 Excited to share our new paper: Scaling Beyond Masked Diffusion Language Models
🤔 Is masked diffusion really the future of non-AR language modeling?
📈 We ran the first scaling law study across 3 discrete diffusion families: masked, uniform-state (Duo), and interpolating (Eso-LMs)!
🤯 Surprisingly: Uniform-state diffusion outperforms masked diffusion on several downstream tasks including GSM8K.
🤔 As expected: Uniform-state diffusion has worse perplexity than masked diffusion.
How to explain this? Dive in👇[🧵1/9]
Paper: arxiv.org/abs/2602.15014
Blog: s-sahoo.com/scaling-dllms/
Code: github.com/s-sahoo/scalin…
Work done in collaboration with: @ssahoo_ @jm_lemercier @jdeschena @Jingyu227 @jwthickstun Ante Jukic
English