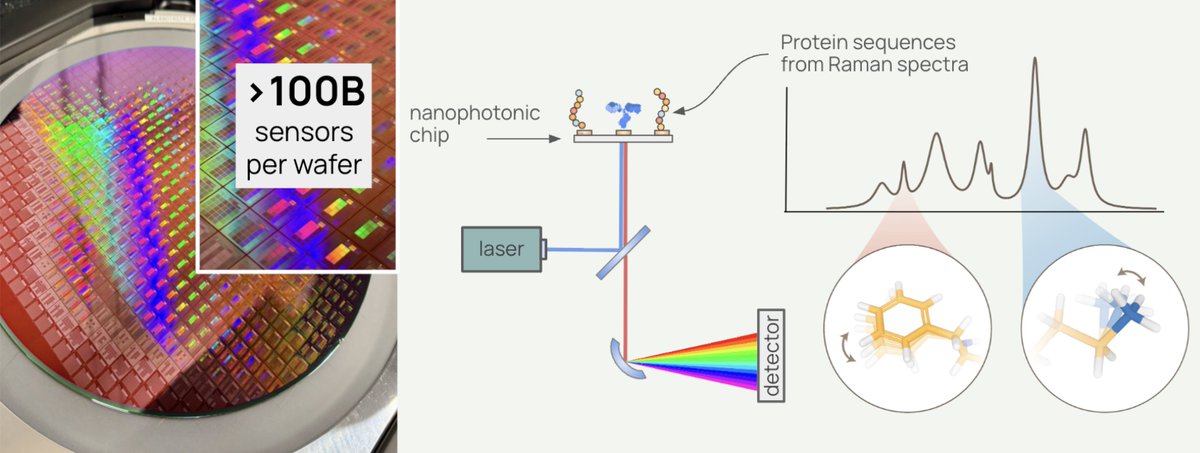
Sam Rodriques@SGRodriques
The Humanity Project
People always ask me: if we want to cure all diseases with AI, shouldn't we be building a huge robotic warehouse to run closed loop experiments on mice, human cells, and so on? From a naive outside perspective, this may seem like the obvious thing to do, analogous to what Periodic Labs is doing for materials and what the robotics companies like Physical Intelligence are doing for laundry and so on.
The problem is, for most diseases, experiments in cultured cells, mice, and other models are poorly predictive of success in actual humans. If you synthesize a material in the lab and find it has a certain conductivity, then that’s the conductivity; by contrast, if something works in a mouse, you still have to test it in a human, and mouse biology is so poorly predictive of human biology that for some diseases success in mice actually anticorrelates with success in humans. Closed loop reinforcement learning in mice might be a great way to learn how to cure mouse diseases, but the only way to cure human diseases is to run more experiments in humans.
To cure all diseases, in other words, what we actually need is a massive, centralized effort to scale up clinical trials testing new AI-generated therapeutic hypotheses. Such an effort would serve several goals: it would identify novel mechanisms for treating diseases; it would train AI systems to understand human biology; and it would build the infrastructure needed to streamline and accelerate clinical trials going forward. Centralization would allow us to minimize duplication, maximize data availability for training, and ensure the resulting infrastructure is shared. An effort of this scale -- which would dwarf the genome project and consume resources similar to the entire NIH budget -- is not just our best chance to cure all diseases. It is also our best chance to remain ahead in biotechnology, where the US is rapidly losing ground to China. I call it the Humanity Project, and I describe it in a new essay, linked below.
The first emphasis in the Humanity Project is on novelty. Medicine moves forward when we identify new therapeutic mechanisms -- think GLP-1s, CAR-T cells, and checkpoint inhibitors. Within a few years, AI agents will be as good as or better than humans at proposing novel therapeutic mechanisms. However, testing novel therapeutic mechanisms is risky and rarely pays off, so most biopharmas largely avoid it. Instead, 96% of clinical trials today are aimed at obtaining approval for new drugs that use existing therapeutic mechanisms, rather than testing new ones. If we want to cure all diseases, we need to massively expand the number of clinical trials we run that examine novel hypotheses, both as a way of identifying novel therapeutic mechanisms and as a way of training AI models to better understand human biology.
This brings us to the second emphasis of the Humanity Project, which is on scale. The Humanity Project would be a centralized project to run 2000 drug programs testing novel, AI-generated therapeutic hypotheses through clinical proof of concept over 5 years. The Project would cost between $50B and $200B -- equivalent to the amount allocated for the California High Speed Rail, or the 5-year budget for the NIH --, would increase the number of first-in-class drug trials by 400% to 800% over that period, and would benefit from various advantages of AI in proposing and prosecuting clinical trials. In the process, the Project would lay down the infrastructure needed to accelerate and scale future trials run by the private sector, accelerating US biotechnology as a whole.
The logistical challenges associated with such a problem are intense. We need better infrastructure to recruit and identify patients; we need to streamline regulation to make it easier to get drugs into patients faster while ensuring safety; we need to scale up and accelerate manufacturing; and we need to plug all of this infrastructure into AI systems that can efficiently integrate information, generate hypotheses and plan experiments, and learn from outcomes. The Humanity Project would work on developing these, and would make the resulting infrastructure available subsequently to accelerate US biotech as a whole. And, importantly, if we are serious about curing all diseases in the coming decades and maintaining US leadership in biotechnology and medicine, there is no alternative. With all the wealth and value set to be created by AI, finding the resources to accelerate medicine in this way should be straightforward. We should begin now.
Read the full proposal below.