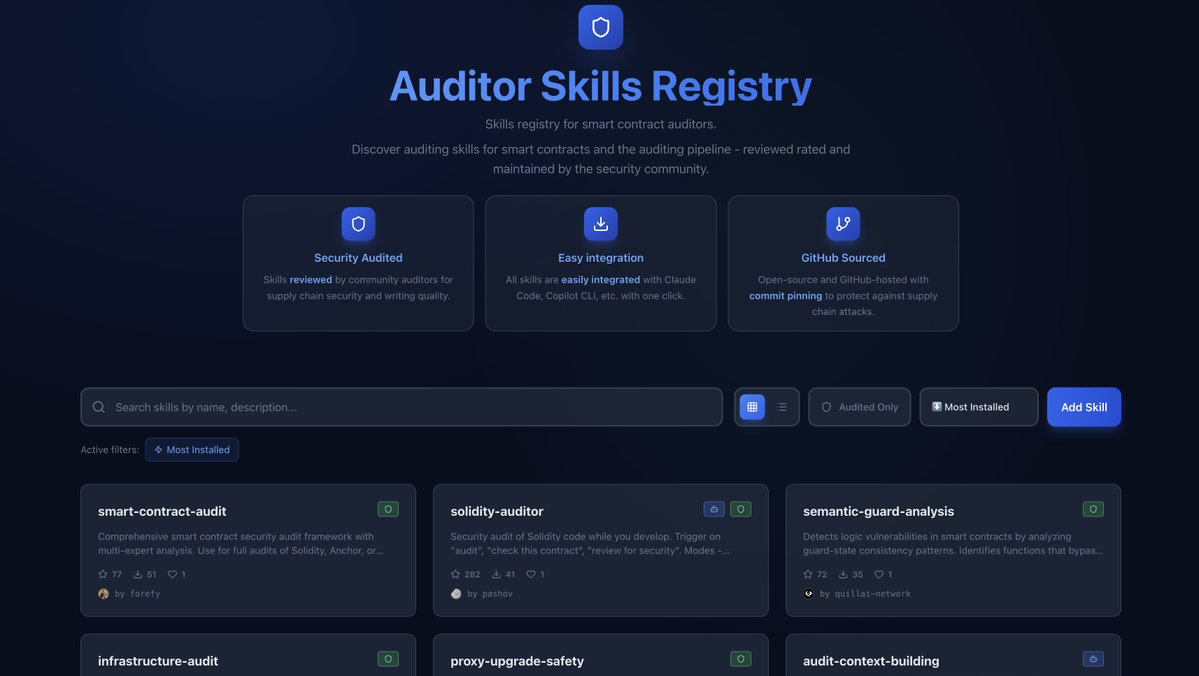
@m4rio_eth Your post has been featured on AISECTOOLS: Blockchain Security AI Tooling Weekly Roundup!
x.com/aisectools/sta…
aisectools@aisectools
English
aisectools
75 posts

@aisectools
The latest posts, articles, and discussions from the world of AI-powered blockchain security tooling! email: https://t.co/12HciHS64R












Our cracked Apex R&D team has one job: to build the frontier AI security agent. Here's a benchmark on how an experimental version of Apex performed against a 6-person audit. It found all the Crits, Highs and Mediums, and several more!





An agentic Ethereum is coming. The Synthesis. Building starts March 13th.