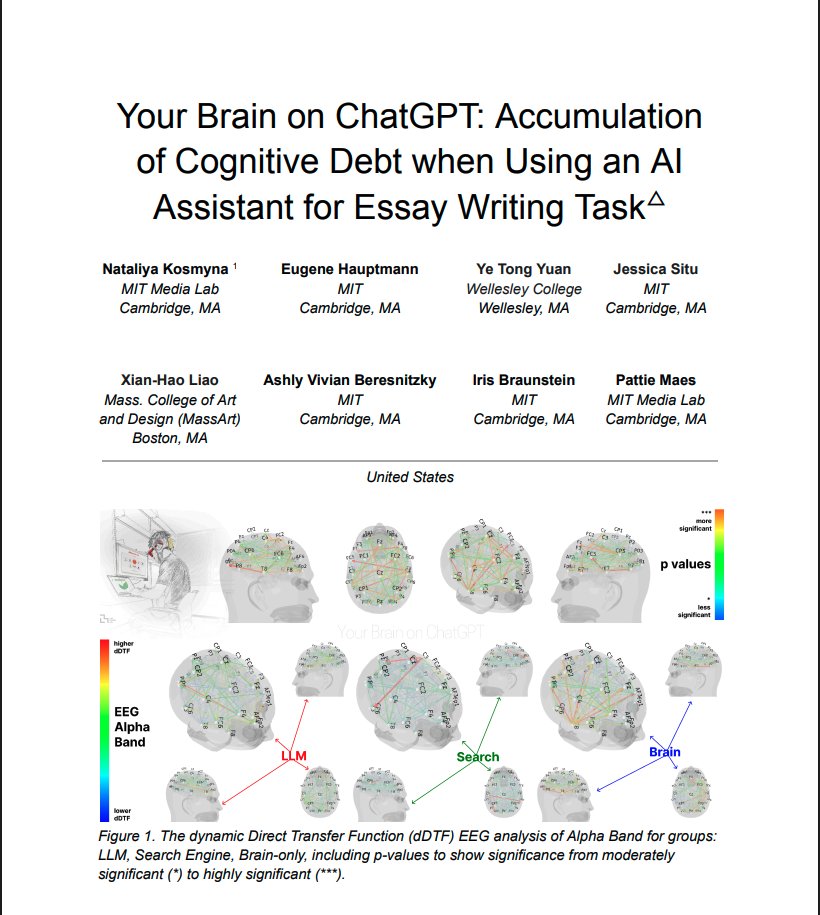
Ajeya retweetledi

We push Prefill/Decode disaggregation beyond a single cluster: cross-datacenter + heterogeneous hardware, unlocking the potential for significantly lower cost per token.
This was previously blocked by KV cache transfer overhead. The key enabler is our hybrid model (Kimi Linear), which reduces KV cache size and makes cross-DC PD practical.
Validated on a 20x scaled-up Kimi Linear model:
✅ 1.54× throughput
✅ 64% ↓ P90 TTFT
→ Directly translating into lower token cost.
More in Prefill-as-a-Service: arxiv.org/html/2604.1503…

English