
Alex Peng
89 posts

Alex Peng
@alexpeng
posttraining @xai, formerly @cognition, @windsurf, @stanford
San Francisco, CA Katılım Ağustos 2009
502 Takip Edilen444 Takipçiler

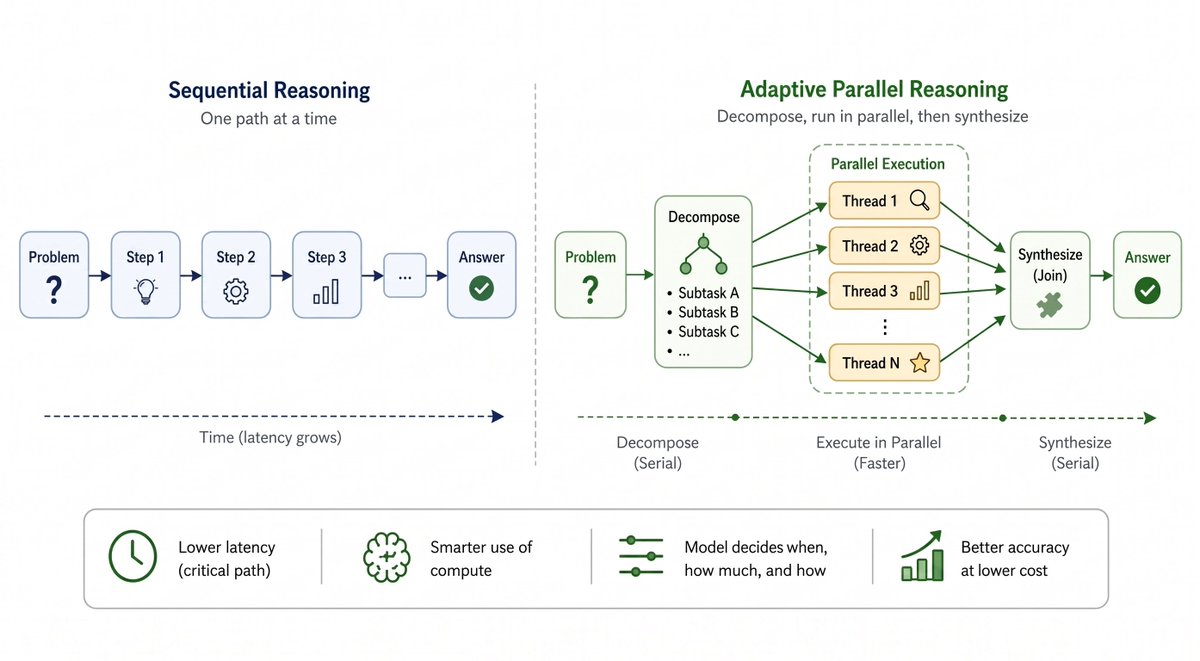
Longer chain-of-thought = slower inference, more context rot, and ballooning compute.
So what if the model could decide for itself when to go parallel?
Our new BAIR blog breaks down Adaptive Parallel Reasoning (APR) — the next paradigm in inference-time scaling. 🧵
English
English

I’m thrilled to be joining @deviationcap, working closely with founders from day zero and backing the next generation of outliers.
@windsurf /@cognition has been the highlight of my career so far, a truly generational company in every sense. I’m coming into venture having seen what excellence looks like up close, and I plan to carry that bar into Deviation as I partner early with founders across developer tools, infrastructure, and applied AI. Deeply grateful to @jeffwsurf, @ScottWu46, @theodormarcu, @akshatag77 and the entire Cognition team.
What drew me to Deviation is a simple idea: the most important companies start as deviations from the norm. That clarity of vision, and working alongside @jpgg, made this the right decision. I’m especially excited about the opportunity to help shape an emerging firm with a true builder mindset from day one.
Colin Beirne@csbeirne
English

Glad to contribute to the office agent and instruction following work streams.
Artificial Analysis@ArtificialAnlys
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English
So grateful for the chance to contribute and learn from the team across posttraining, data, and evals for this model release. More to come!
Artificial Analysis@ArtificialAnlys
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English
@si_pbc @sonyatweetybird @MikowaiA @YasminRazavi @karpathy @tszzl @_milankovac_ Congrats on the raise guys!
English

We’ve raised 75m in new funding from Sequoia and Spark Capital—partnering with @sonyatweetybird, @MikowaiA, and @YasminRazavi, all of whom are deeply supportive of our long-term mission. We’ve also brought on angels & advisors including @karpathy, @tszzl, and @_milankovac_.
-----
Our early results with FDM-1 moved computer use from a data-constrained regime to a compute-constrained one; this latest round of funding unlocks several orders of magnitude of compute scaling for that work. With the FDM model series we have a path to scale agentic capabilities through video pretraining, and we expect to achieve superhuman performance on general computer tasks in the same way that current language models have superhuman performance on coding tasks.
We’re also now able to invest in the blue-sky research necessary to our long term mission of building aligned general learners. To realize the civilizationally transformative impacts of AI, models must generalize far out of their training distributions, actively exploring and building skills in new environments. This capability represents a substantial shift from the current paradigm of model training. We believe that current alignment techniques are insufficient to predictably and safely steer a model with human-level learning capabilities, and so we’re doing work to study small versions of this problem in controlled environments to develop a science of alignment for general learners.
We’re a team of 6 people in San Francisco. We’re hiring world-class researchers and engineers to help us achieve our mission. If that’s you, please get in touch.
English
Alex Peng retweetledi

Alex Peng retweetledi

The standard for frontier coding evals is changing with model maturity.
We now recommend reporting SWE-bench Pro and are sharing more detail on why we’re no longer reporting SWE-bench Verified as we work with the industry to establish stronger coding eval standards.
SWE-bench Verified was a strong benchmark, but we’ve found evidence it is now saturated due to test-design issues and contamination from public repositories.
openai.com/index/why-we-n…
English
Alex Peng retweetledi

Seems like a lot of people are taking this as gospel—when we say the measurement is extremely noisy, we really mean it.
Concretely, if the task distribution we're using here was just a tiny bit different, we could've measured a time horizon of 8 hours, or 20 hours.
METR@METR_Evals
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.
English
cool :)
swyx 🇸🇬 AIE Singapore!@swyx
so after 24 hours we tallied early returns (from people koding on Saturdays mind you): @xai Grok is currently #3 coding model in the world by early voters (after 1 day and thousands of full agent votes). its really interesting to see the order shaken up, and there’s a reason why: SPEED IS ALL YOU NEED one thing I was keen on contributing to the evals community was an arena that doesnt penalize speed. aka, simply allow users to reward models that are “good enough but faster”, which is a core thesis @cognition has been pursuing with SWE1.5. 3 human-ai turns with “good enough but fast” models often beats 1 long smart but slow models. All coding model evals set up to date basically ignore speed, hence people just happily RL to take thousands of CoT tokens. we will make those tokens count, or else.
English
@TheGregYang Take care Greg - office won’t be the same without being the LED sign guy every time candidates come around
❤️
English

I've been suffering from Lyme disease.
I'm stepping back from xAI into an informal advisory role so I can go founder mode on my health, starting today.
---
The symptoms started when I got sick (cold, flu, or COVID -- I'm not sure which) in early 2025. I distinctly felt less energetic, less creative, and less agentic even weeks after "recovery." After that, my condition ebbed and flowed, but the lows kept getting lower.
Accidentally eating the wrong thing would make me extremely tired, taking days to recover. Working out would leave my whole body feeble for days. There was a week where I slept 12 hours a day and still couldn't recover.
Lyme is famously hard to diagnose, but luckily I have an incredible doctor. He suspected these symptoms, far from being just in my head, indicated immune issues. Detective work over a few rounds of testing revealed I have Lyme disease.
I was very surprised because Lyme is said to come from tick bites (where the bump looks like a target), but I don't ever remember having one. Likely I contracted Lyme a long time ago, but until I pushed myself hard building xAI and weakened my immune system, the symptoms weren't noticeable.
---
Overall, I actually feel lucky to have discovered this early. Lyme is a serious disease that only gets harder to treat with age -- patients discovering it in their 50s or 60s have a much tougher time. Lyme can also be debilitating, leaving its victims bedridden, but luckily I'm still functional and can take care of myself day to day.
So while some folks have said "you shouldn't have pushed yourself so hard," I'm glad I did. I found this issue early, and now I can fix it so I can push myself even harder when I rebound.
---
Chronic Lyme is not well understood in the literature or by the public. For folks suffering from it, it can be a lonely fight. But I hope my story can make it just a little less lonely.
English
Minimax casually dropping that they’re training world models that solve the halting problem to make better coding models
MiniMax (official)@MiniMax_AI
English
I led eval process + deployment for frontier coding agents at multiple F500 companies at @windsurf then @cognition
The only eval enterprises care about is if the deployment saves them money (time/headcount)
Upstream of that eval metrics are extremely rudimentary. mostly still just acceptance rate, PR cycle review time improvements, etc.
Qualitative feedback from principal/staff engs dominates.
Working on code evals @xai now and the difference between what SWE agent/coding teams in frontier labs care about vs the median enterprise buyer is huge
Brendan (can/do)@BrendanFoody
has anyone seen an agentic deployment in a large enterprise work without an eval?
English
Think carefully if you are verifying the capability you care about and not a shittier, weaker level of capability in a language and interface totally alienated from how you will actually use the model
andrew pignanelli@ndrewpignanelli
Code was the killer app for AI cause it verifies really well. Linting, unit tests and instant feedback for frontend make it so outputs are verified in real time. If you want to think about what gets automated by AI next look at the verification mechanisms. We’re seeing this start in fields like math and biology which have excellent verification systems. Art went quickly because you can instantly tell if it’s good enough. All of this is still maturing but the rate at which the industry matures is directly related to how fast the verification loop is. Medicine and law will have a p99 problem and take forever to diffuse. What’s next? Probably accounting and finance since they’re super easy to verify.
English
SWE evals (METR, variants of SWE-bench, etc) are highly unrepresentative of real world SWE work, and in nonobvious ways, but people continue to take a model’s SWE-bench verified score or METR time length estimate as ground truth Coding Strength.
Consensus seems to be that SWE/coding evals are a solved problem because they are verifiable. Lots of alpha in questioning this assumption. Similar insights to the QT can be mined by just looking at the actual eval tasks (not the benchmark score)
Shashwat Goel@ShashwatGoel7
New Blogpost: How to game the METR plot🚨 In 2025, a single graph changed AGI timelines, investments, research priorities, model quality assessments and much more. But if you squint harder, only 14 prompts shaped AI discourse over this year. Thats all the data in the 1-4 hour horizon length regime that matters. 🕵️ What's more? A majority of these are about Cybersecurity capture the flag contests, and training a Machine Learning model. > Post-train your model on CTF and ML codebases > profit 📈! its METR horizon length will increase. Exactly what OpenAI has been targeting in its Codex model releases... and is Anthropic underperforming in the 2-4hr range because it mostly consists of cybersecurity, which is dual-use for safety? To be clear, I think its an excellent idea to track horizon lengths instead of benchmark accuracy. But under the current modelling assumption of success probability being a logistic function of task length, SWAA+HCAST accuracy improvements alone might explain the exponential progress in horizon length 🔎 In the blog, I show detailed evidence for why we need to stop overindexing on the METR plot. Share it with anyone you see making decisions based on where the latest model lands on the METR plot. shash42.substack.com/p/how-to-game-…
English