Sabitlenmiş Tweet

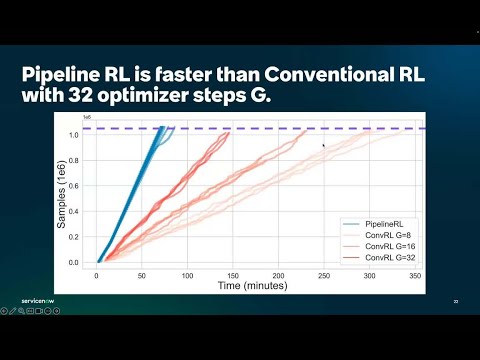
Very excited to see vLLM supports Pipeline RL’s in-flight weight updates! It allowed our team to quickly and reliably train Qwen base 7B to reason from scratch! Want to hear more? Join us at our Pipeline RL expo talk at CoLM this Thursday 1PM room 524C.
vLLM@vllm_project
🚀 The RL community keeps pushing boundaries — from better on-policy data and partial rollouts to in-flight weight updates that mix KV caches across models during inference. Continuing inference while weights change and KV states stay stale sounds wild — but that’s exactly what PipelineRL makes work. vLLM is proud to power this kind of modular, cutting-edge RL innovation. Give it a try and share your thoughts!
English