
Alluxua
241 posts
Alluxua
@alluxio_f
Machine Learning Engineer. Love investment, love machine learning . Create the best version of myself! Be a winner of life !!
Katılım Temmuz 2016
285 Takip Edilen54 Takipçiler

@summeryue0 Courageous of you to share. Thanks for that.
What model were you using with openclaw? Would compaction quality depend on the model? Would some models retain instructions better?
English

Nothing humbles you like telling your OpenClaw “confirm before acting” and watching it speedrun deleting your inbox. I couldn’t stop it from my phone. I had to RUN to my Mac mini like I was defusing a bomb.



English
Alluxua retweetledi

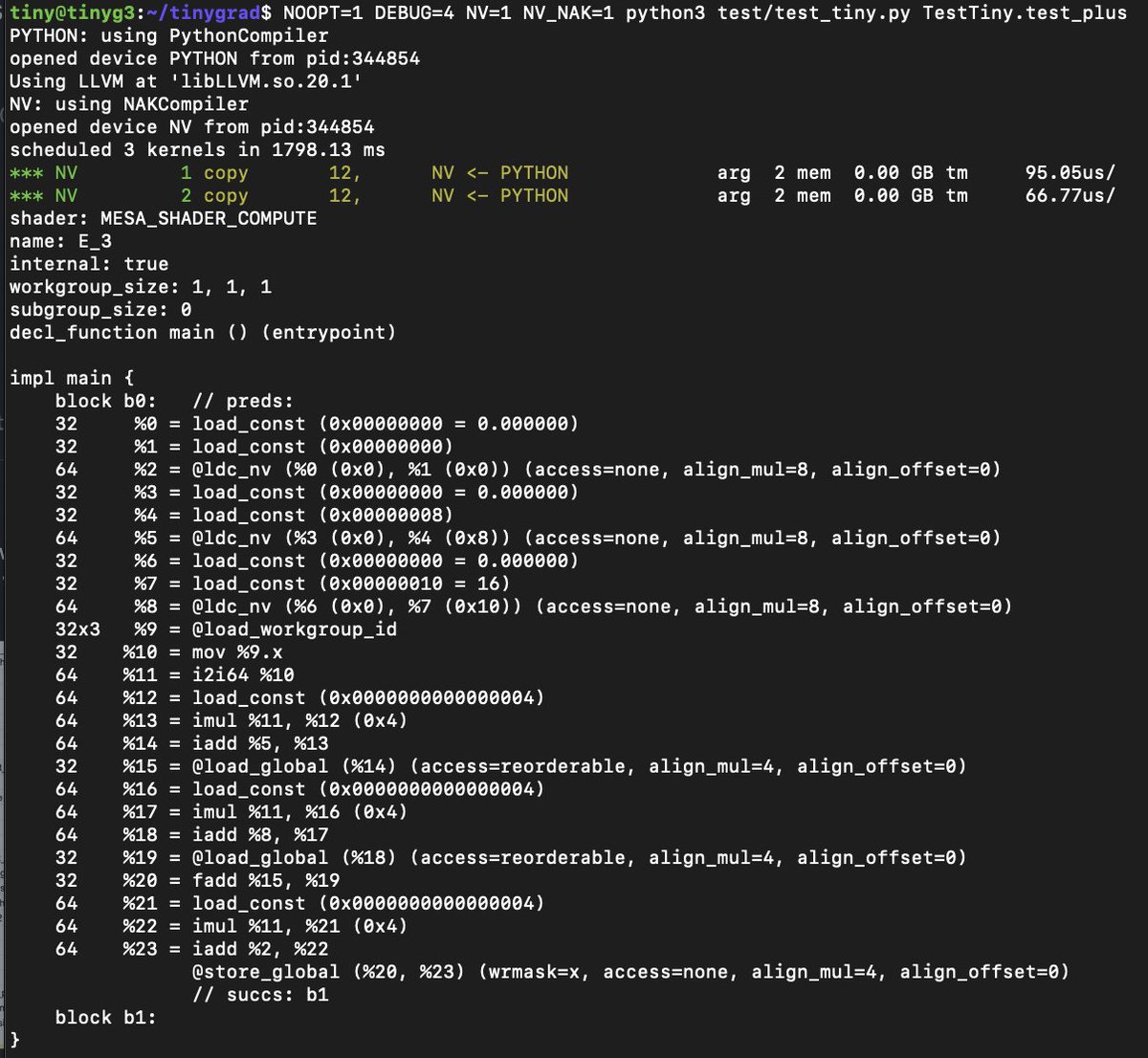
Thanks to sirhcm, tinygrad now supports all the backends in Mesa by rendering to NIR. One of the Mesa backends is NAK, and with it, we can compile to SASS. An NVIDIA free stack! github.com/tinygrad/tinyg…
English
@__tinygrad__ Wow, that is amazing! Can I get a bunch of GPUs from lambda and use tingrad to cluster them together?
English
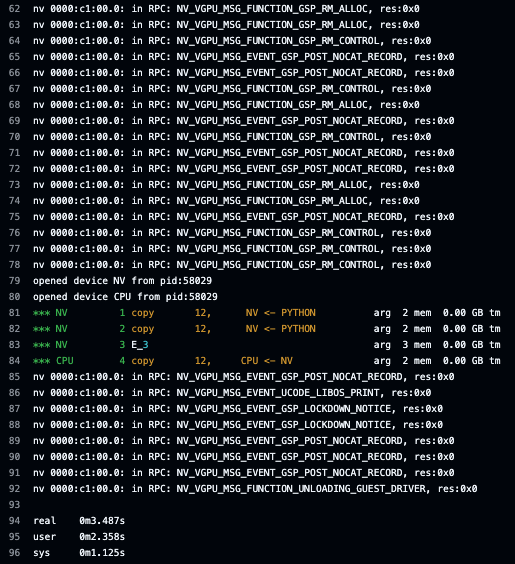
tinygrad now supports NVIDIA 5090/4090 without the kernel driver, similar to AMD. It's tested in our CI.
English
@ZhidingYu He did great at Nvidia, but that doesn’t mean DeepSeek follows the same approach, without hidden agenda.
ZipLab is tied to Zhejiang University, a government-funded institution. Most friends who returned to China learned the hard way—no exception.
Disclaimer: Not into politics.
English

Zizheng was one of our interns at NVIDIA back in summer 2023. Later, when we were considering to make him a FT offer, he chose to join DeepSeek without much hesitance. Back then, the DeepSeek multimodal team only has 3 people.
I am still very much impressed by Zizheng’s decision at that time. He has been an important contributor of several important works at DeepSeek, including DeepSeek-VL2, DeepSeek-V3, and DeepSeek-R1. I am personally very happy for his decision and the great achievements.
Zizheng’s case is a very typical example of what I have witnessed in recent years. Many of our best talents come from China, and these talents don’t have to succeed only in a US company. Instead, we learn a lot from them. The same Sputnik Moment has already happened in AV back in 2022, and it will continue to happen in Robotics and LLM industry as well.
I love NVIDIA and want to see her as a continued major contributor to the path of AGI and general autonomy. But if we keep cooking up geo-political agendas and creating hostile opinions to Chinese researchers, we will shoot ourselves in the foot and lose even more competitiveness. We need more talent density, professionalism, learnings, creativity and stronger execution. We don’t need political narratives and clowns like Alexandr Wang.
Zizheng Pan@zizhpan
This moment is absolutely phenomenal to me.
English

@SamAltsMan @tunguz Well, they find a way to get INTO your system. Absolutely not distillations. There are 2 types of model into their system: one is from OpenAI, another is key words match to their internal documents.
English
@markchen90 @dylan522p @Mayhem4Markets If you test DeepSeek-R1 extensively, you’ll see it’s not a distilled model but a full model, strikingly similar to an older OpenAI model—without a real Chinese knowledge base. Test it for a day, and you’ll see for yourself.
English

@dylan522p is more often right than wrong (h/t @Mayhem4Markets)

Mark Chen@markchen90
However, I think the external response has been somewhat overblown, especially in narratives around cost. One implication of having two paradigms (pre-training and reasoning) is that we can optimize for a capability over two axes instead of one, which leads to lower costs.
English
@alexandr_wang If you test DeepSeek-R1 extensively, you’ll see its performance doesn’t match the claims. It’s not a distilled model but a full model, strikingly similar to an older OpenAI model—without a real Chinese knowledge base. Test it for a day, and you’ll see for yourself.
English

What does DeepSeek R1 & v3 mean for LLM data?
Contrary to some lazy takes I’ve seen, DeepSeek R1 was trained on a shit ton of human-generated data—in fact, the DeepSeek models are setting records for the disclosed amount of post-training data for open-source models:
- 600,000 reasoning data [1]
- 200,000 non-reasoning SFT data [2]
- human preference (RLHF) dataset of undisclosed size [3]
- human-processed synthetic data for cold-start data [4]
According to Chinese AI engineers, DeepSeek actually values data annotation even more than other Chinese labs, with the CEO personally labeling data for the model [5] (This reminds me of @karpathy who used to spend a quarter of his time labeling at Tesla). The DeepSeek-v3 paper even has a dedicated acknowledgement section for Data Annotation [6].
DeepSeek-V3, which was distilled from DeepSeek-R1, was also trained on an instruction-tuning dataset of 1.5M samples. [7]
These SFT datasets are even larger than other open-source models:
- Qwen-2.5 was trained on 1M SFT samples [8]
- the last time Meta disclosed was for Llama 2, which was trained on only 30k SFT samples and 3M RLHF samples [9]
- Kimi k1.5 was trained on roughly 1M SFT, 1M multi-modal SFT, 800k samples for classic reward modeling, and another 800k CoT labeled examples for reasoning [10]
It’s interesting that the size of the RLHF dataset was undisclosed, while they disclosed the size of the SFT and reasoning datasets. This could be because it is much larger than one would expect, or it reveals some interesting technical detail they don’t care to share. Human preference datasets are often much larger than SFT datasets in most models, so a reasonable estimate would be that DeepSeek’s models are probably trained on at least 3-5M samples, which is quite a large preference dataset!
The main technical breakthrough of DeepSeek-R1 is that for reasoning, you can forgo SFT data in favor of reasoning data—but reasoning data is still human data of difficult problems&answers in a variety of domains.
The reasoning dataset is actually quite large—600k reasoning samples is a LOT. This is in line with a broader trend we’ve seen from SFT data towards other data types like human preference/RLHF data and reasoning data. This is for technical reasons—SFT caps the performance of the model at a certain level, whereas RLHF or other methods enable the models to continue improving without bound beyond the limits of the dataset.
DeepSeek R1 is a very exciting model, and it’s great to see o1 reasoning capabilities replicated in the wild. In terms of training data, however, the DeepSeek models are actually setting open-source records in terms of the amount of human data used.
[1]
[2]
[3]
[4] arxiv.org/pdf/2501.12948
[5] chinatalk.media/p/deepseek-the…
[6] arxiv.org/html/2412.1943…
[7] arxiv.org/html/2412.1943…
[8] arxiv.org/pdf/2412.15115
[9] arxiv.org/pdf/2307.09288
[10] arxiv.org/html/2501.1259…




English
@markchen90 @dylan522p @Mayhem4Markets They may just get the leaked openai model from some sources. Their output not consistent and tons of answers not make sense at all. They may have faked every thing to short Nvidia .
English
Alluxua retweetledi


Alluxua retweetledi

Alluxua retweetledi


Alluxua retweetledi

Claude Sonnet 3.5 can now search the web and generate images with ChatLLM.
With just $10 you can use Claude Sonnet 3.5, GPT-4o, & Llama 3 in a single AI playground.
Plus, build custom AI agents with RAG without writing a single line of Python Code.
English
@__tinygrad__ Can I still buy 6 new Nvidia 4090 and get it working as you did? Or only the old Nvidia 4090 can do tricks. Thank you!
English
Source is here. With some cleanups, it might even be upstreamable. It relies on large BAR support. There's a decent writeup of how it works in the README. github.com/tinygrad/open-…
English
We added P2P support to 4090 by modifying NVIDIA's driver. Works with tinygrad and nccl (aka torch).
14.7 GB/s AllReduce on tinybox green!
English