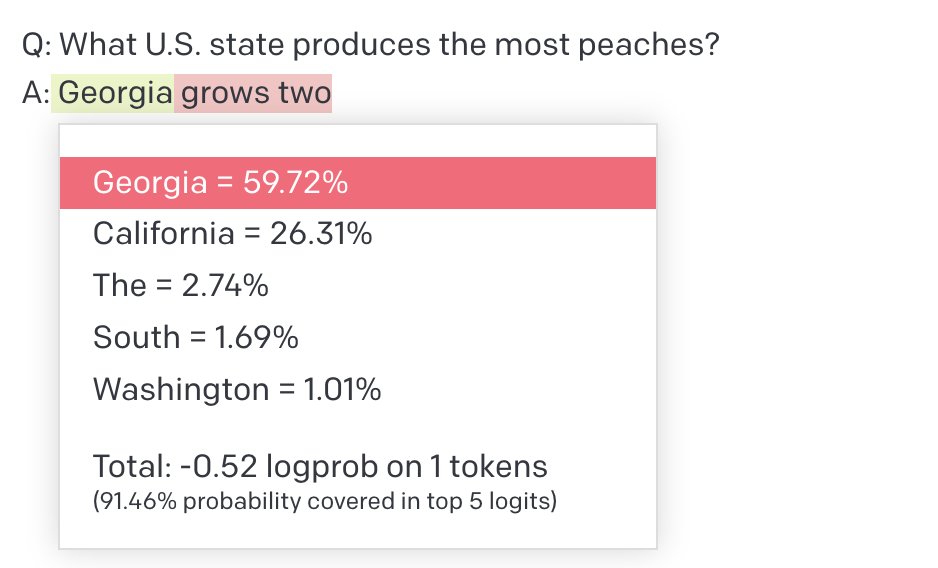
Andrew Mauboussin retweetledi

"Prognosticative pastry." "A hound circling a tree, nose to bark."
These aren’t parodies - they’re actual quotes from SOTA models in response to creative writing prompts, and they’re winning leaderboards that are rewarding slop.
We’re introducing *Hemingway-bench*, a new AI writing leaderboard, to fix this:
surgehq.ai/leaderboard
surgehq.ai/blog/hemingway…
We designed Hemingway-bench to push frontier model writing toward genuine nuance and impact.
Instead of autograders and two-second vibe checks - both of which love fancy literary devices and dense formatting, over actual quality - we used expert human writers across a variety of fields to judge real-world writing tasks.
Why? I love writing. I love reading. Great science fiction is one of the things that's always inspired me. Even in terms of "enterprise value", so much of what we do in our day-to-day involves writing - we want crisp emails and insightful reports, not dry, verbose summaries.
Yeah, coding is important - but there's a reason I use CC-assisted apps, but still haven't read a full-fledged AI novel.
What did we find? Current leaderboards are easily hacked, and often negatively correlated with actual quality. If a model (over)uses all the stuff you learn about in school (metaphors in every sentence! transition words! complex, flowery phrases!), it ranks high on EQ-bench and LMArena.
But that’s not good writing that people actually want.
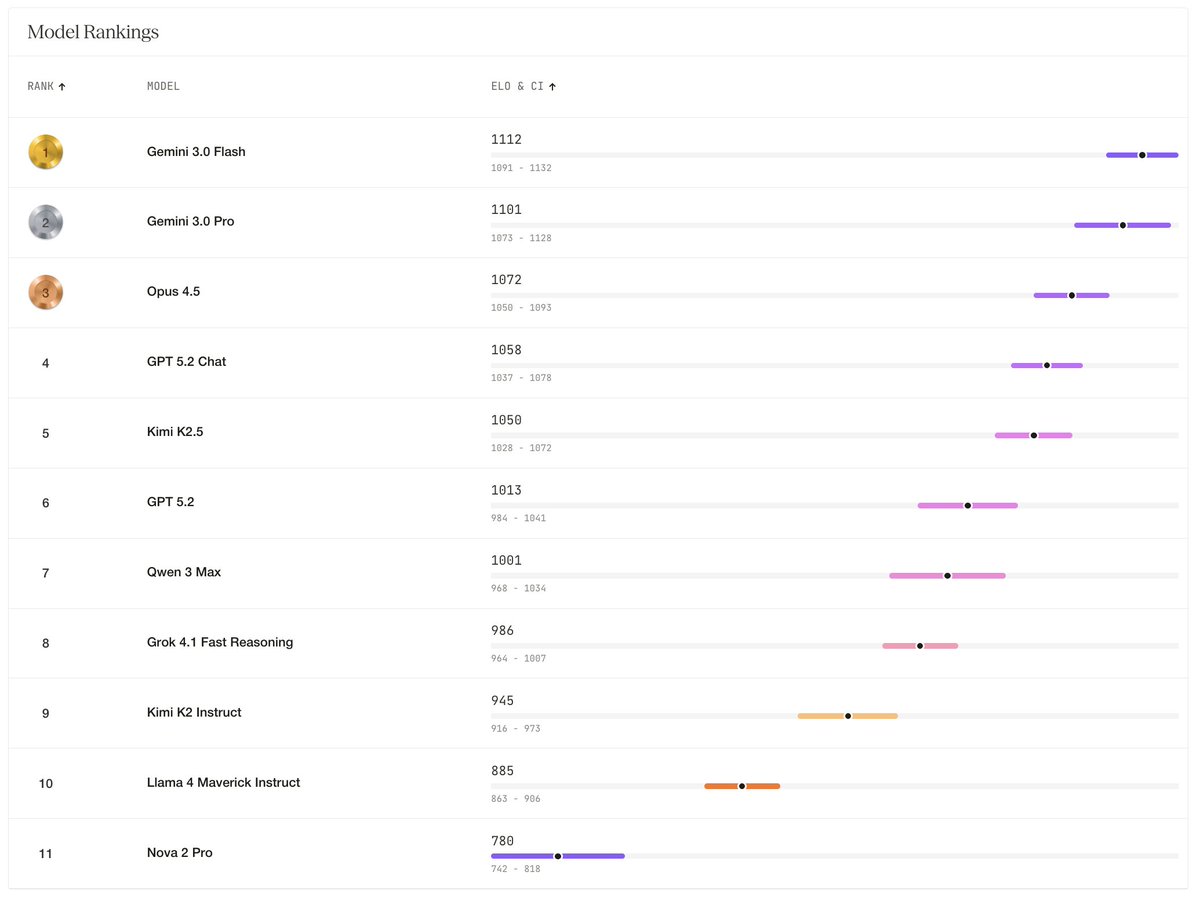
The winners of Hemingway-bench didn't sound like they were trying to win a poetry slam. Gemini 3 Flash, Pro, and Opus 4.5 took the top 3 spots because they had natural voices that didn't sound pretentious.
They were poetic and immersive, but in the right ways.
When they used wit, they didn't sound cringey and try-hard - they sounded like your naturally funny friend.
I'm waiting for the day AI wins a Pulitzer, and hopefully Hemingway-bench helps guide it on its way.
Check out the leaderboard and examples here: surgehq.ai/leaderboard
And our blog post describing it: surgehq.ai/blog/hemingway…
English