
Arakoo Devs
5K posts

Arakoo Devs
@arakoodev
SAP for AI Agents. A revenue-first framework that creates a double-entry ledger for every agent operation
Katılım Kasım 2016
1K Takip Edilen348 Takipçiler

Introducing TigerFS - a filesystem backed by PostgreSQL, and a filesystem interface to PostgreSQL.
Idea is simple: Agents don't need fancy APIs or SDKs, they love the file system. ls, cat, find, grep. Pipelined UNIX tools. So let’s make files transactional and concurrent by backing them with a real database.
There are two ways to use it:
File-first: Write markdown, organize into directories. Writes are atomic, everything is auto-versioned. Any tool that works with files -- Claude Code, Cursor, grep, emacs -- just works. Multi-agent task coordination is just mv'ing files between todo/doing/done directories.
Data-first: Mount any Postgres database and explore it with Unix tools. For large databases, chain filters into paths that push down to SQL: .by/customer_id/123/.order/created_at/.last/10/.export/json. Bulk import/export, no SQL needed, and ships with Claude Code skills.
Every file is a real PostgreSQL row. Multiple agents and humans read and write concurrently with full ACID guarantees. The filesystem /is/ the API.
Mounts via FUSE on Linux and NFS on macOS, no extra dependencies. Point it at an existing Postgres database, or spin up a free one on Tiger Cloud or Ghost.
I built this mostly for agent workflows, but curious what else people would use it for. It's early but the core is solid. Feedback welcome.
tigerfs.io
English


yes — 27 agents across 3 machines working on our production codebase daily. 506 tasks shipped. the key insights: 1) AGENTS.md per repo with clear lane definitions so agents don't step on each other 2) per-agent MEMORY.md that persists across sessions 3) heartbeats for status polling instead of relying on agents to self-report 4) role-based access — not every agent should touch every file. the biggest codebase challenge is context management at scale, not the coding itself.
English

@taggy @saurabh_p @KloopAi Can we roll this out for you ?
Free for the next year. Proudly made in India.
stringcost.com/accounting/
English

I and @saurabh_p are onboarding our first users at @kloopai and the LLM bill forecast is already giving me a reality check.
You know going in that AI SaaS has real marginal costs unlike traditional SaaS which was way easier to add more customers. But data-intensive agents running continuously per customer hits different when it's your on your cards.
Bootstrapped. Early.
English
@geoffreywoo Usage is too simplistic.
U need to translate usage into credits.
stringcost.com
English

psa to saas founders:
convert everything into api / mcp services asap and charge by usage.
allow connectors to all agents and make your own agent with pre-built context
all ui/ux/dashboards will be vibed and dynamically generated
if you don’t have prop data, you’re fucked
English

Introducing Superterm
Manage your AI agents and background tasks with tmux: the way it was meant to be.
Focus your attention only where it's needed - Claude wants to grep.. HuggingFace model is now downloaded..
Privacy mode is for sharing screenshots and for streaming (below)

English
@jerryjliu0 @tursodatabase Genuinely curious - how do you format the markdown?
So theres obviously a mismatch between a markdown format...and all ur enterprise data (sql, slack, crm, etc).
Does it matter how u structure and format the markdown? Or just dump everything in one ginormous file?
English

Building “RAG 2.0” is just making Claude Code running over your filesystem 🤖🗂️
To make this work well, you need to solve three things
1️⃣ Virtualize your filesystem to prevent the agent from messing stuff up. AgentFS by @tursodatabase is a nice example of how you can give the agent access to a copy of all your files without messing up your raw data.
2️⃣ Parse unstructured documents like PDFs, pptx, Word into an LLM-ready format. Agentic OCR solutions like LlamaParse can help here
3️⃣ Creating an agentic loop with human-in-the-loop. If you want to control the agent implementation instead of using Claude Code out of the box, you can use @llama_index workflows to help orchestrate these long-running agent tasks.
Shoutout @itsclelia, check it out!
Blog: llamaindex.ai/blog/making-co…
Repo: github.com/run-llama/agen…
LlamaIndex 🦙@llama_index
Secure your coding agents with virtual filesystems and better document understanding. Building safe AI coding agents requires solving two critical challenges: filesystem access control and handling unstructured documents. We've created a solution using AgentFS, LlamaParse, and @claudeai. 🛡️ Virtual filesystem isolation: agents work with copies, not your real files, preventing accidental deletions while maintaining full functionality 📄 Enhanced document processing: LlamaParse converts PDFs, Word docs, and presentations into high-quality text that agents can actually understand ⚡ Workflow orchestration: LlamaIndex Workflows provide stepwise execution with human-in-the-loop controls and resumable sessions 🔧 Custom tool integration: replace built-in filesystem tools with secure MCP server alternatives that enforce safety boundaries This approach uses AgentFS (by @tursodatabase) as a SQLite-based virtual filesystem, our LlamaParse for state-of-the-art document extraction, and Claude for the coding interface - all orchestrated through LlamaIndex Agent Workflows. Read the full technical deep-dive with implementation details: llamaindex.ai/blog/making-co… Find the code on GitHub: github.com/run-llama/agen…
English

any agent-first secret store startups? would love to meet.
English
@NorthflankWill @ivanburazin Are u using KEDA ? gvison?
Im curious what stack do people use at this scale
English

@ivanburazin we're running millions of sandboxes on gke, fast, long, and stateful. It's unrealistic for enterprises to use anything else. seems to be working great for lovable too
English

Spinning up 1m sandboxes concurrently is no small feet - congrats!
But don’t think that running it on gke will be your long time solution.
Jonathan Grahl@jonathangrahl
I just ran a load test of starting a million sandboxes on our sandbox infra. Managed without any hiccups! We've been tuning them for a while and are now able to support multiple 10x growths this year without rearchitecting. GKE is truly impressive!
English

I just ran a load test of starting a million sandboxes on our sandbox infra. Managed without any hiccups!
We've been tuning them for a while and are now able to support multiple 10x growths this year without rearchitecting.
GKE is truly impressive!
English

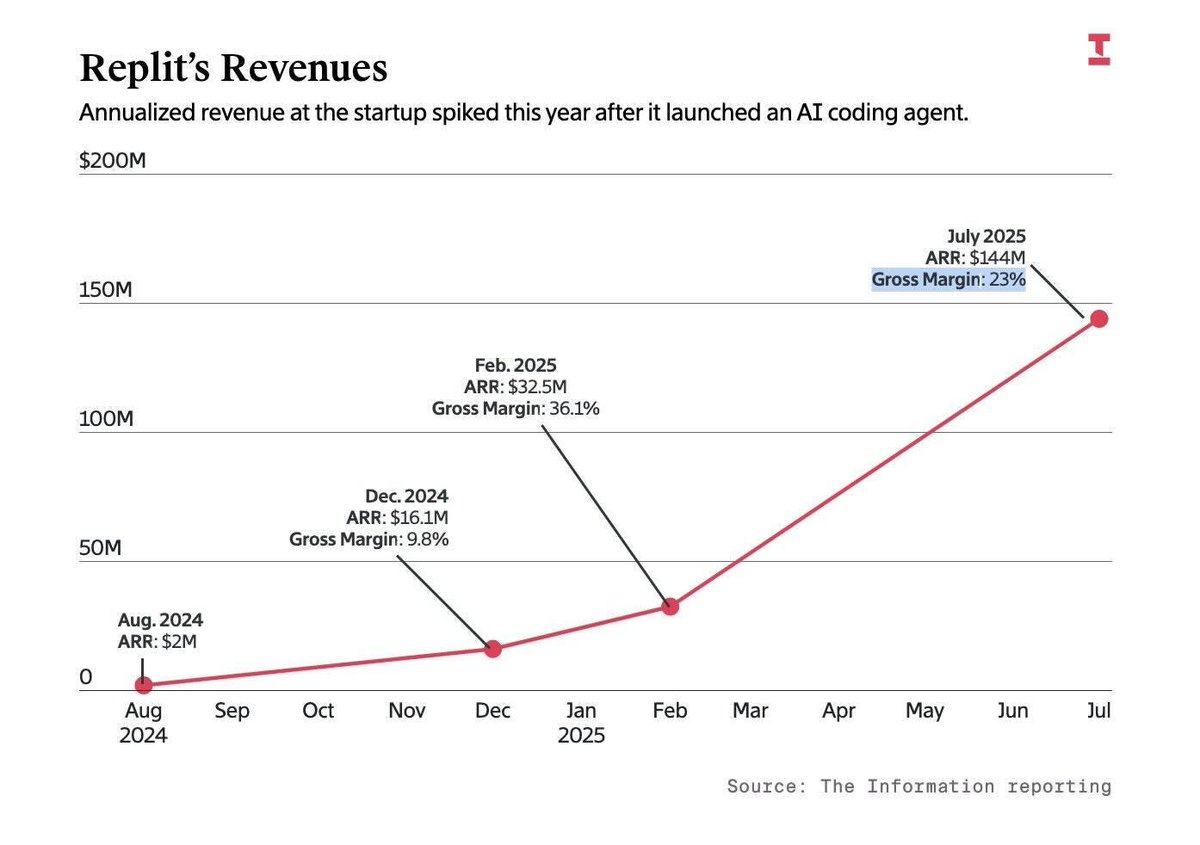
Replit's gross margin went from +36% to -14% in a matter of months.
They didn't lose customers. They gained them.
The problem: their AI agents consumed more compute than their pricing ever anticipated.
This is the hidden trap in the "AI add-on" model.
Your best users become your most expensive users.
And flat pricing has no mechanism to absorb that asymmetry.
Every AI company pricing on seats right now should be watching this closely.
It is not an edge case. It is the default outcome.
English

a SaaS company reached out to us after OpenClaw-style agents are sending ~50k requests per hour (wayyy above normal site usage). the company now wants to charge agents small amount for reads and writes with @stripe machine payments.
if this is also you (or may soon be), say hi.
English
English
@andreihasna @jeff_weinstein @stripe Hi @andreihasna can we help with billing & pricing?
stringcost.com
English

@ColinGardiner @jeff_weinstein @stripe This is brilliant!
Can we talk to your portfolio cos?
We solve the accounting and billing problems
stringcost.com
English

@jeff_weinstein @stripe Just wrote this piece, and I don't see how any agent-to-agent or agent-to-human models work without solving the pay-in side of things. Very intrigued to see how it evolves.
x.com/ColinGardiner/…
Colin Gardiner@ColinGardiner
English
@__d_1ggin @aakashgupta Genuine question - how is alibaba using this in production? Doesnt the data has to be persisted?
So how does that happen if it is in-process?
English

@aakashgupta Hi I am already using Zvec for building a memory for claude! Have a look!
github.com/lboquillon/brb
English

This tweet frames Zvec as a Pinecone killer. That framing obscures what Alibaba actually built.
Zvec is an embedded, in-process library. No server. No network calls. No daemon. You import it like you import pandas. Pinecone and Weaviate will never see this in their competitive dashboards because it targets a completely different layer of the stack.
The technical lineage matters here. Proxima has been running production vector search inside Alibaba for years. Taobao product search, Alipay face payments, Youku video recommendations, Alimama advertising. Billions of queries across systems where latency failures cost real revenue. What Alibaba’s Tongyi Lab did is strip that engine down, wrap it in a Python API, and release it as a library anyone can pip install.
The benchmarks back it up. On VectorDBBench with the Cohere 10M dataset, Zvec hits 8,000+ QPS at comparable recall. That’s more than 2x ZillizCloud, the previous #1, with faster index build times. An embedded library matching or beating managed cloud services on raw throughput.
This follows the SQLite playbook. SQLite opened an entirely new category of database usage by embedding directly inside applications. Software that would never have run a client-server database suddenly had access to SQL. Zvec is making the same bet for vector search: local RAG pipelines, desktop AI assistants, CLI tools, edge devices, anywhere spinning up a Pinecone cluster would be absurd.
And that tells you where AI inference is heading. Every agent framework, every local assistant, every on-device RAG system needs vector search. The vast majority of those workloads run fine on an in-process library with 64 MB streaming writes and configurable memory limits.
Pinecone raised $138M and just repositioned as a “knowledge platform.” Weaviate raised $50M. Their customers have SLAs, compliance requirements, and enterprise procurement cycles. Zvec is going after the 90% of developers who were overprovisioning infrastructure for workloads that fit inside a single process.
The companies that should actually be nervous are Chroma and FAISS, the current defaults for lightweight local vector search, because Zvec just showed up with Alibaba-scale engineering in a pip-installable package.
Hasan Toor@hasantoxr
🚨 Alibaba just quietly dropped a vector database that destroys Pinecone, Chroma, and Weaviate. It's called Zvec and it runs directly inside your application no server, no config, no infrastructure costs. No Docker. No cloud bills. No DevOps nightmare. Built on Proxima, Alibaba's battle-tested vector search engine powering their own production systems at scale. The numbers don't lie: → Searches billions of vectors in milliseconds → pip install zvec and you're searching in under 60 seconds → Dense + sparse vectors + hybrid search in a single call And it runs everywhere: → Notebooks → Servers → Edge devices → CLI tools 100% Opensource. Apache 2.0 license. This is the vector DB the RAG community has been waiting for production-grade performance without the production-grade headache. Link in the first comment 👇
English

like if you’re even kinda good at kubernetes or C++ you’re unbelievably employable rn
English
fake software engineering jobs are dying rapidly. real software engineering jobs, however,
English
@steipete Damn ! Any chance ull opensource it.
This is amazing for opensource maintainers
English

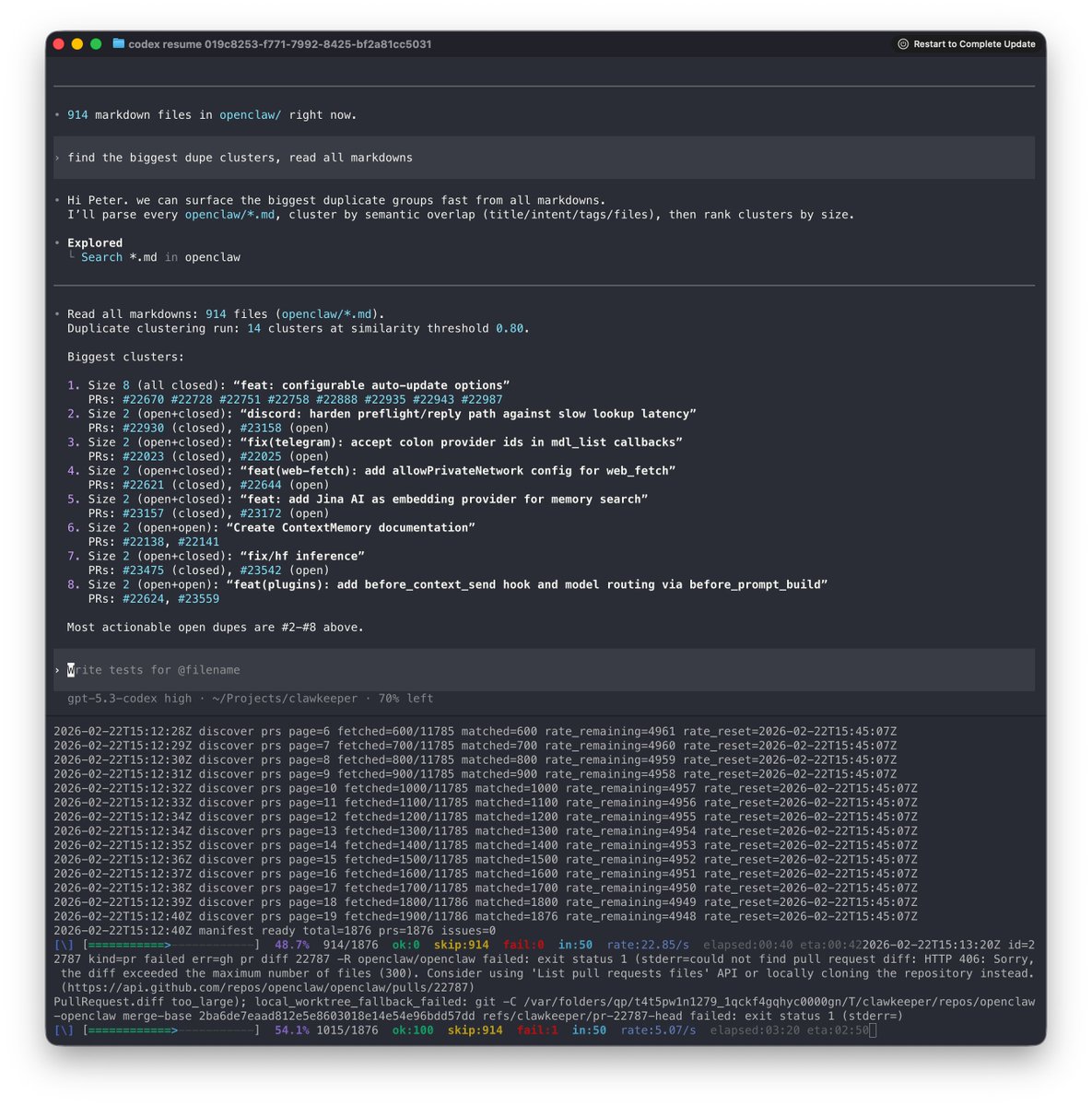
Been wrangling a lot of time how to deal with the onslaught of PRs, none of the solutions that are out there seem made for our scale.
I spun up 50 codex in parallel, let them analyze the PR and generate a JSON report with various signals, comparing with vision, intent (much higher signal than any of the text), risk and various other signals.
Then I can ingest all reports into one session and run AI queries/de-dupe/auto-close/merge as needed on it.
Same for Issues. P rompt R equests really are just issues with additional metadata.
Don't even need a vector db. Was thinking way too complex for a while.
There's like 8 PRs for auto-update in the last 2 days alone (still need to ingest 3k PRs, only have 1k so far).
English

your icp is probably too broad
"b2b saas companies" is not an icp
"tech companies with 50+ employees" is not an icp
real icps are specific enough that you can name 10 companies that fit perfectly
we use a 6-layer icp framework:
→ firmographics (the basics)
→ technographics (tools they use)
→ behavioral signals (what theyre doing)
→ negative filters (who to avoid)
→ buying committee map (who to contact)
→ trigger events (when to reach out)
built out the complete worksheet
like + comment 'ICP' and i'll DM you. (must be following)
English