Sabitlenmiş Tweet

0x_arjunghosh_ai
79.5K posts

@arjunghosh
Non-Linear #Thinker, #Futurist, #solopreneur, Crafting #AI & multi #AgenticAI, Coach, Speaker, Founder at https://t.co/2FxweBxUFG, Chief AI & Tech Officer @flexilytics






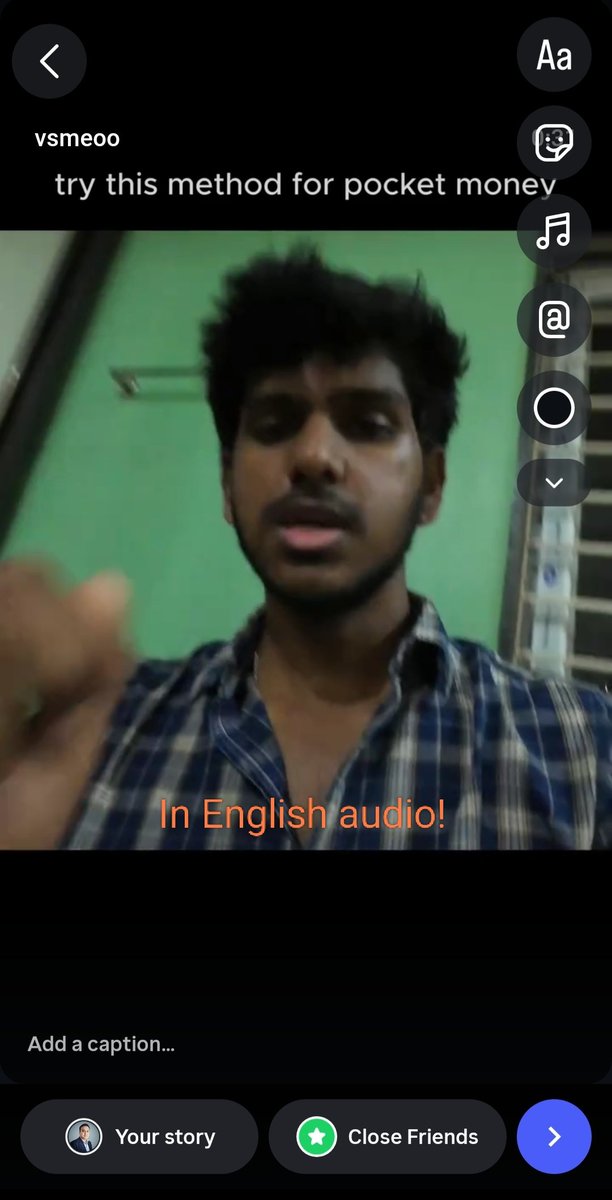
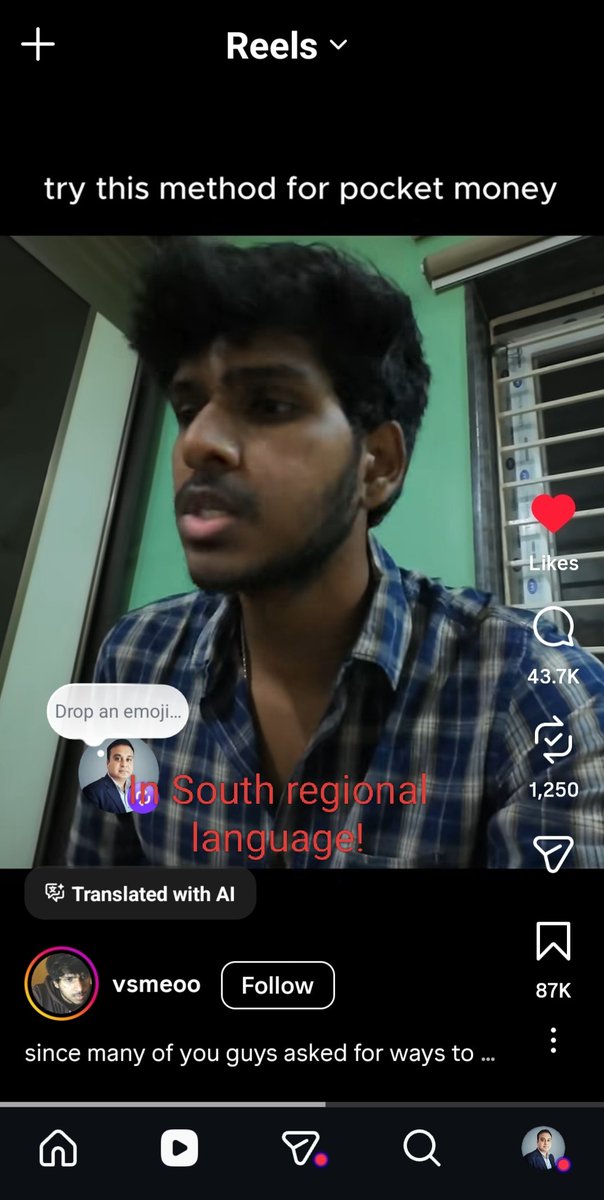

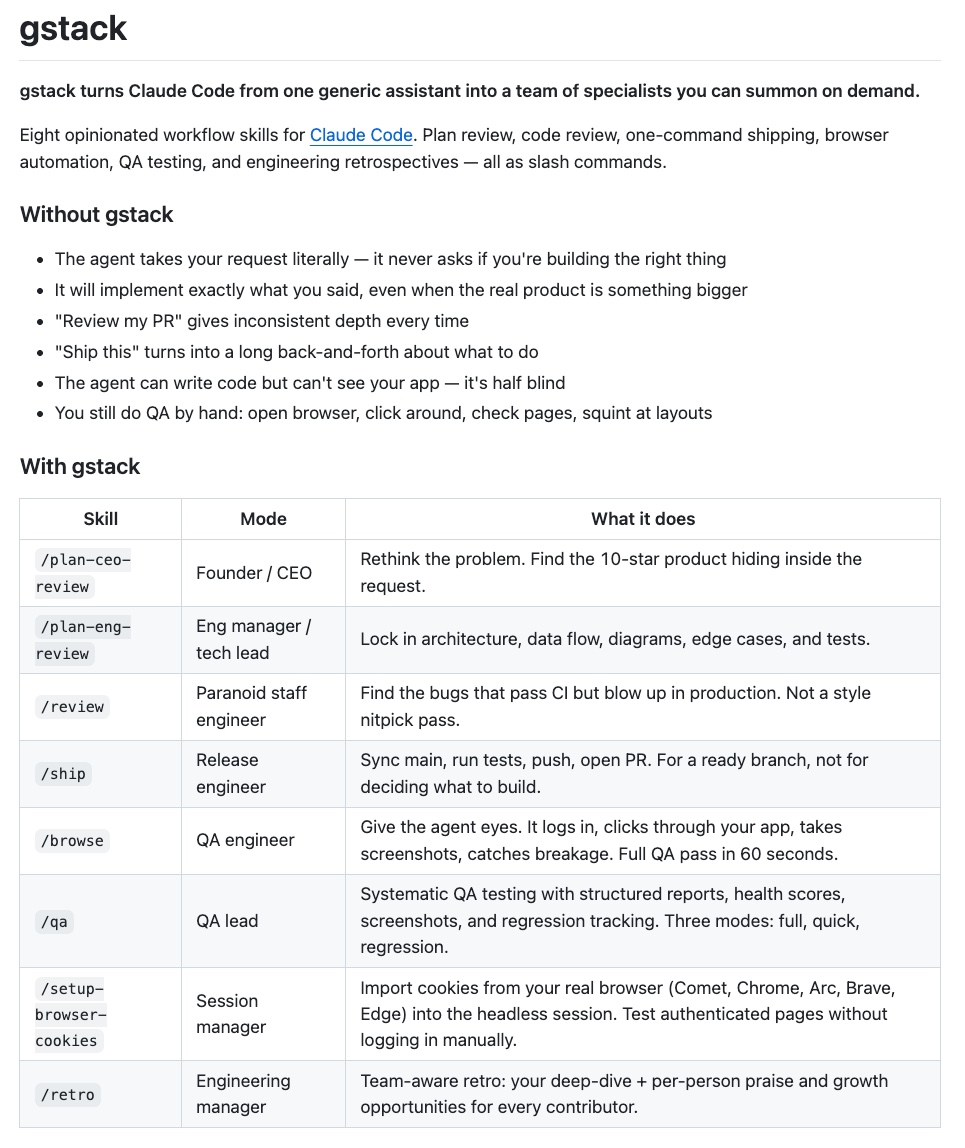



Tough day. Made some difficult changes to the @digg team. This wasn't about performance - these are brilliant and talented folks. We just haven't found the right product-market fit yet. More: digg.com



🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
We found a task where LLMs struggle massively! Give them a coding problem in Python and they'd work great. Give the same problem in brainfuck and zero-shot their performance is ~0% +[--------->+<]>+.++[--->++<]>+.

🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵


