Christian Balbin retweetledi
Christian Balbin
216 posts

Christian Balbin
@asipilled
Health AI research | PhD ‘24 @UUtah
Katılım Ağustos 2025
455 Takip Edilen53 Takipçiler





In today’s adventures of working at Lambda is super cool, I get to have a B200 rack in my house*

English

I’m not doing this X thing correctly. I’m the CFO of a company that just announced the largest crypto M&A deal in history, I posted about it, then reposted my own posts and somehow I only gained one follower this week…. Can someone tell me what I’m doing wrong?

English
@bnjmn_marie Your account is literally straight alpha for local LLMs. Thanks for doing this !
English

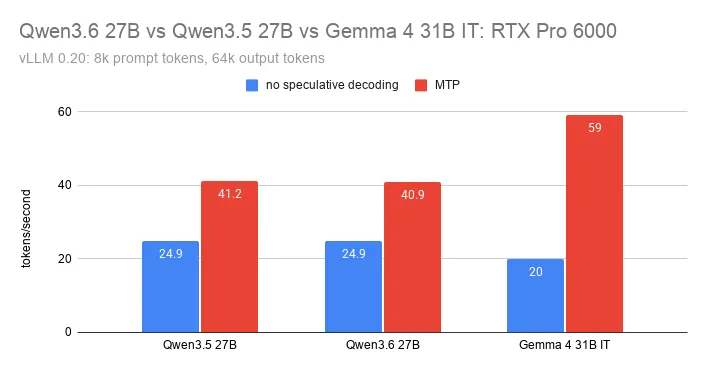
I benchmarked Google’s new MTP for Gemma 4 31B using vLLM with 4 speculative tokens, a fairly conservative setup.
Results:
- Much higher throughput than Qwen3.6’s MTP
- Lower latency too, helped by Gemma 4 generating fewer tokens
- For coding tasks with reasoning enabled, Gemma 4 is now at least 6x faster than Qwen3.6. So you can generate 5 outputs, run your tests to select the best one, and it would still be cheaper than a single output by Qwen3.6.
I’ve updated my full comparison with the new numbers:
kaitchup.substack.com/p/qwen36-27b-v…
I also confirmed what others have reported: Gemma 4’s MTP handles a high number of speculative tokens very well.
On simple text generation, I’m now testing values above 10 and reached 129 tok/s on an RTX Pro 6000, compared with 20 tok/s without MTP.
Next step: confirming how this translates to real tasks.
English
@loktar00 @vllm_project same here. also the rc broke the generation of xml/html in tool calls because of a parsing issue.
English

@vllm_project Bah even with nightly 20.2.rc1 I keep getting:
NotImplementedError: Speculative Decoding with draft models or parallel drafting does not support multimodal models yet
English

🚀 Day-0 MTP support for Gemma4 now available at vLLM with ready-to-use docker image!
⚡️Enjoy up to 3x faster decoding performance to supercharge your development with zero quality degradation!
Check out the full vLLM recipes for Gemma 4 model series👇
recipes.vllm.ai/Google/gemma-4…

Google for Developers@googledevs
Gemma 4: Now up to 3x Faster. ⚡ Same quality, way more speed. Our new MTP drafters allow Gemma 4 to predict multiple tokens at once, effectively tripling your output speed without compromising intelligence.
English
@YouJiacheng they should know these are wild claims and that people would rightfully be skeptical. they should have had trusted a 3rd party benchmark them
English

81.8% swe-bench in the first release???
wow.
is this legit?
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@rileybrown i'll believe it when i see it on @ArtificialAnlys
English

Chat is this real?
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English


English

it is endlessly fascinating to me that we still don't have a true 1M-context model
it's an unusual case where the infra is far ahead of the science. Claude discontinued 1M+ context bc it didn't really work past ~200k
we don't have the right data? training techniques? not sure
English
how i feel using xhigh to make the most simple UI cosmetic changes
English
@sama that 'not accepted' email spiked my cortisol lol but appreciate the kindness here. OpenAI is one of the few companies where it really feels like they care deeply about the community
English
we are gonna do something nice for everyone who applied for the GPT-5.5 party and that we didn't have space for. hope you enjoy!
English
anyone using ChatGPT Atlas ? just remembered about it when going through my apps

English
@daradoescode It's crazy that computer use has basically been solved
English



@MatthewBerman i would just run the draft model on the dgx station. My assumption is you won’t get too much of a gain by offloading it to the spark.
English

Pretty sure I can double the t/s
Isn’t possible to do speculative decoding with a DGX spark on the same network?
Matthew Berman@MatthewBerman
DeepSeek V4 Flash running on the DGX Station.
English