Sabitlenmiş Tweet

Recent agentic systems (Claude Code, Codex, RLM, etc.) push context out of the prompt and into the environment (e.g., as files). This helps them maintain long-term knowledge about their goals and functionality.
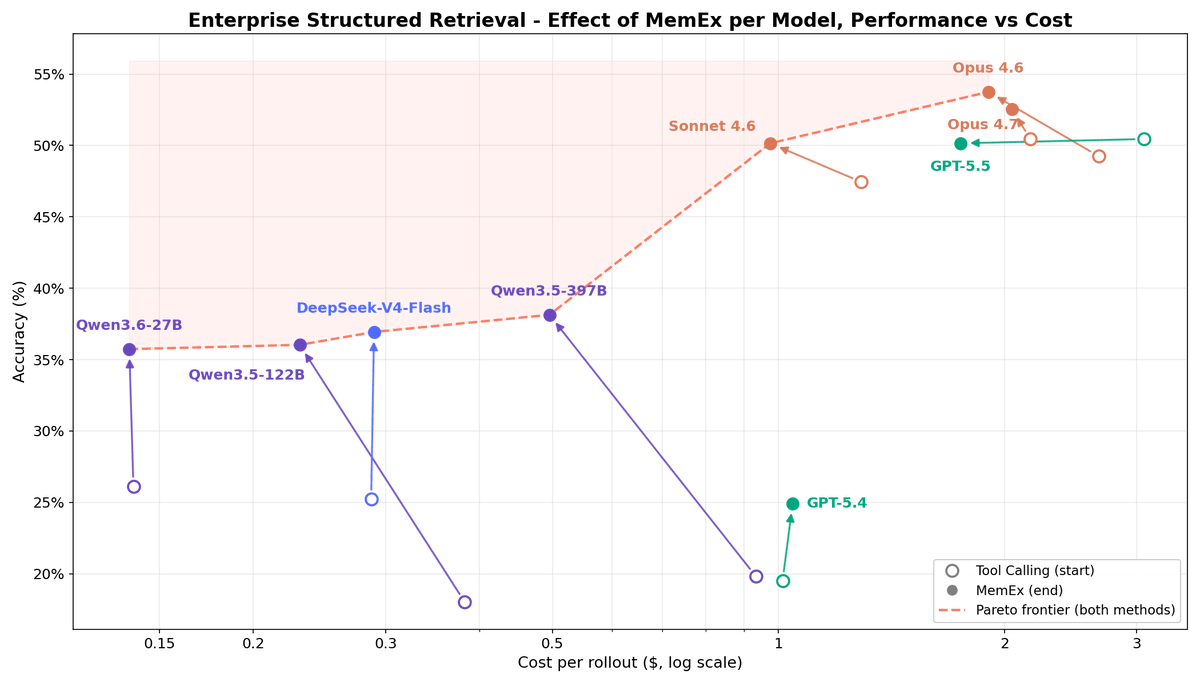
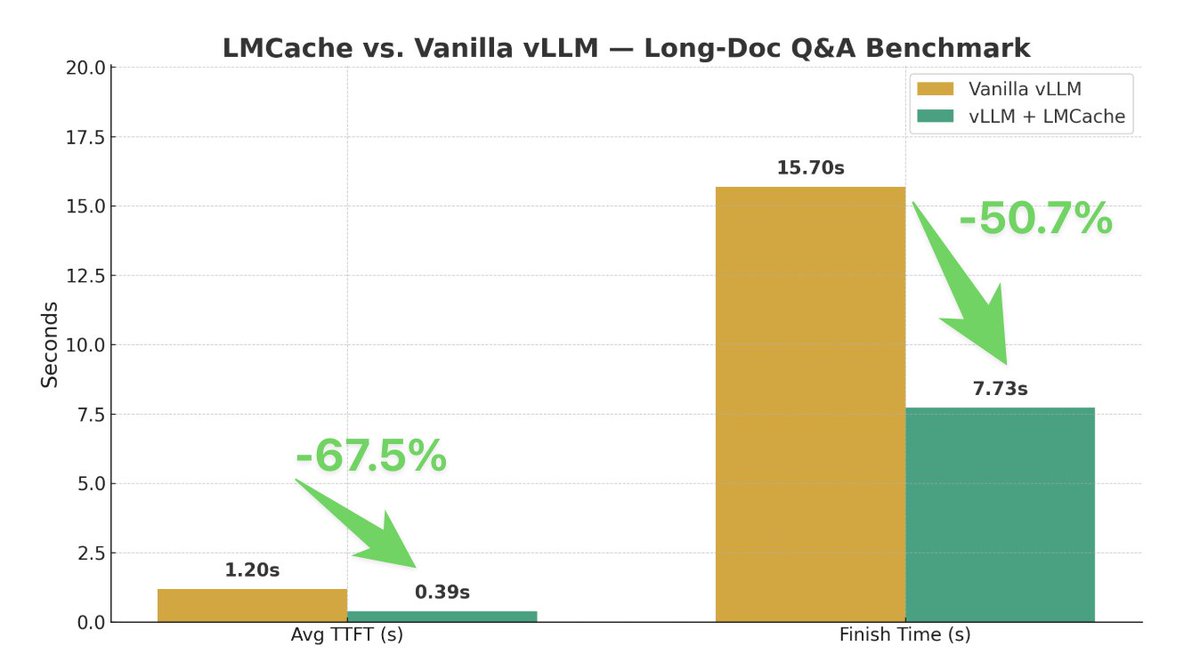
🚨 While this is a good idea, we show a surprising result: systems that use external environments like this perform much better when given a small, fixed-size, in-context, agent-managed cache that "𝘱𝘦𝘦𝘬𝘴 𝘪𝘯𝘵𝘰" these environments.
🚀 Our paper, 𝗣𝗘𝗘𝗞: 𝙖 𝙨𝙮𝙨𝙩𝙚𝙢 𝙛𝙤𝙧 𝙗𝙪𝙞𝙡𝙙𝙞𝙣𝙜 𝙖𝙣𝙙 𝙢𝙖𝙞𝙣𝙩𝙖𝙞𝙣𝙞𝙣𝙜 𝗮𝗻 𝗼𝗿𝗶𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 𝗰𝗮𝗰𝗵𝗲 𝙛𝙤𝙧 𝙇𝙇𝙈 𝙖𝙜𝙚𝙣𝙩𝙨, introduces this idea.
Compared with strong baselines, including RAG, Compaction Agents, and SOTA prompt-learning frameworks, PEEK dominates the cost–quality Pareto frontier: achieving +6.3–34.0% in quality, with fewer iterations and lower cost.
Paper: arxiv.org/abs/2605.19932
GitHub: github.com/zhuohangu/peek
More in the thread below! (1/N)

English