
along
600 posts

along
@attaalong
AI engineer,tencent&minovte&ByteDance base shenzhen
Katılım Ocak 2012
467 Takip Edilen27 Takipçiler

@elonmusk I feel like it might be possible with the help of AI tools to find some very elegant and compact descriptions that explain some of the deepest mysteries of the universe, but it might take a lot of pattern processing and matching to get there...
English
It’s 2am again, my favourite time, and as always reality is still staring me in the face 🧐
Kpaxs@Kpaxs
This is a man who has been haunted since childhood and built a billion dollar company as a side effect of trying to make the haunting stop.
English


I’m not a developer. Never was.
But I built a full AI product in 2 months using Claude Code.
The gatekeeping era is over. You don’t need to code. You need to know what to build.
English

@PeterDiamandis Your work is truly remarkable; once humans are connected to the network, it can unleash tremendous creativity.
English

You've got 8 billion potential customers on Earth, BUT...
In 2026, only ~5.3 billion have internet access. That means 2.7 billion people still can't access the exponential tools we talk about daily—AI, telemedicine, online education, digital banking.
The gap: The missing ~3 billion represent the largest untapped market in human history. Starlink alone now has 10,000+ satellites in orbit (just crossed that milestone yesterday). When connectivity becomes ubiquitous in the next 3-4 years, we're not just adding users—we're adding builders, creators, entrepreneurs.
The implication: The next Einstein, the next Elon, the next medical breakthrough might be sitting in a village without Wi-Fi right now. Abundance doesn't just mean "more for current participants"—it means unlocking latent genius at global scale.
English

这个Skill不错,养龙虾最怕的不是它不干活,是你不知道它在干什么。我自己跑着7个子Agent,有时候一觉醒来根本不知道谁干了什么、谁卡住了、token烧到哪去了。这个仪表盘一目了然,感觉很适合我,准备装上试试。
木子不写代码@ai_muzi
开源一个我自用的OpenClaw控制中心! 可以一个面板: - 看哪些任务烧了多少 token(百分比) - 看整个 OpenClaw 现在健不健康 - 看每个 Agent 现在在干嘛,有没有卡住 - 看每个 Agent 用的模型、目录、权限 - 直接查看和修改 Agent 的记忆,人设、任务文档 - 看定时任务和心跳任务有没有正常在跑 项目地址:github.com/TianyiDataScie…
中文
This is really good. I feel that in the future, AI can provide ideas, send papers, reproduce experiments, and then put forward new hypotheses and optimizations.
Rohan Paul@rohanpaul_ai
This research introduces a system that recovers the hidden information needed for computers to successfully reproduce academic experiments. Academic papers often leave out crucial details, which prevents other researchers from recreating the results in their work. This paper addresses the problem by identifying three types of missing knowledge, specifically relational, somatic, and collective details. The proposed system, named PAPERREPRO, uses a graph-based framework to automatically find and apply this missing information during reproduction. It works by analyzing relationships between the original paper and its neighbors, then uses feedback from running code to refine its understanding. This method allows AI agents to fill in the gaps that authors leave behind, making automated experimentation much more reliable. By turning these implicit details into actionable steps, the framework bridges the gap between static text and executable code. ---- Paper Link – arxiv. org/abs/2603.01801 Paper Title: "What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction"
English
@rohanpaul_ai You have to master the overall knowledge before you can choose the knowledge, otherwise you will choose the general from the dwarf.
English

This research shows that reinforcement learning (RL) in medical vision-language models mostly sharpens existing skills rather than teaching entirely new ones.
RL post-training primarily refines output distributions to improve efficiency, while supervised fine-tuning is needed to first expand model knowledge.
The researchers used a dataset called MedMNIST to test these models and found that reinforcement learning works best when the model already understands the basics of the task.
Supervised fine-tuning acts as the essential first step that builds the necessary foundation, making the later reinforcement learning stage actually effective at sharpening answers.
Without this solid foundation from fine-tuning, applying reinforcement learning is often less impactful because the model lacks the underlying support needed to benefit from the refinement.
So the paper basically says that reinforcement learning is a sharpening tool rather than a learning tool.
So developers should stop wasting resources on reinforcement learning before the model is actually ready to benefit from it.
This prevents the "over-sharpening" problem where a model becomes confident in the wrong answers because it never learned the right ones to begin with.
----
Paper Link – arxiv. org/abs/2603.01301
Paper Title: "When Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains"

English

What if your 🦞 had its own office?
In QClaw, your lobster now lives in a pixel-art studio — walking around, getting busy, taking breaks. 🧉Not a background process. A tiny coworker.
This started as a collab with @ring_hyacinth and @simonxxoo from the open-source project Star-Office-UI. Turns out we all agree: AI shouldn't feel cold🤗
Adopt your lobster. Watch it work > qclaw.qq.com

English

@NVIDIAAIDev @grok can you look for the price range please.
English

NVIDIA DGX Station is now available to order from select OEMs🔥
Powered by the GB300 Grace Blackwell Ultra Desktop Superchip, DGX Station brings data-center-class AI performance to the desk — enabling developers to build and run autonomous AI agents locally.
⚡ 748GB of coherent memory
⚡ Up to 20 petaflops of AI compute performance
⚡ Run large open models up to one trillion parameters
Together with NVIDIA NemoClaw — an open source stack that simplifies running OpenClaw always-on assistants, more safely, with a single command, we are delivering a full-stack platform for secure, long-running agentic AI.
Learn more: #dgx-spark-station" target="_blank" rel="nofollow noopener">blogs.nvidia.com/blog/gtc-2026-…

English

It's a substantial upgrade. AttnRes replaces fixed residuals with input-dependent attention over prior layers, fixing PreNorm dilution and letting the model selectively reuse useful past reps. Block version keeps it efficient. On Kimi's 48B/3B MoE (1.4T tokens): GPQA-Diamond 36.9→44.4 (+7.5 pts, massive for expert QA), Math 53.5→57.1 (+3.6), HumanEval 59.1→62.2 (+3.1), MMLU 73.5→74.6 (+1.1). Matches baseline loss at 1.25x compute, <2% latency hit. First real evolution of residuals since ResNet.
English

Big release from Kimi!
They just released a new way to handle residual connections in Transformers.
In a standard Transformer, every sub-layer (attention or MLP) computes an output and adds it back to the input via a residual connection.
If you consider this across 40+ layers, the hidden state at any layer is just the equal-weighted sum of all previous layer outputs.
Every layer contributes with weight=1, so every layer gets equal importance.
This creates a problem called PreNorm dilution, where as the hidden state accumulates layer after layer, its magnitude grows linearly with depth.
And any new layer's contribution gets progressively buried in the already-massive residual. This means deeper layers are then forced to produce increasingly large outputs just to have any influence, which destabilizes training.
Here's what the Kimi team observed and did:
RNNs compress all prior token information into a single state across time, leading to problems with handling long-range dependencies. And residual connections compress all prior layer information into a single state across depth.
Transformers solved the first problem by replacing recurrence with attention. This was applied along the sequence dimension.
Now they introduced Attention Residuals, which applies a similar idea to depth.
Instead of adding all previous layer outputs with a fixed weight of 1, each layer now uses softmax attention to selectively decide how much weight each previous layer's output should receive.
So each layer gets a single learned query vector, and it attends over all previous layer outputs to compute a weighted combination.
The weights are input-dependent, so different tokens can retrieve different layer representations based on what's actually useful.
This is Full Attention Residuals (shown in the second diagram below).
But here's the practical problem with this idea.
Full AttnRes requires keeping all layer outputs in memory and communicating them across pipeline stages during distributed training.
To solve this, they introduce Block Attention Residuals (shown in the third diagram below).
The idea is to group consecutive layers into roughly 8 blocks.
Within each block, layer outputs are summed via standard residuals. But across blocks, the attention mechanism selectively combines block-level representations.
This drops memory from O(Ld) to O(Nd), where N is the number of blocks.
Layers within the current block can also attend to the partial sum of what's been computed so far inside that block, so local information flow isn't lost.
And the raw token embedding is always available as a separate source, which means any layer in the network can selectively reach back to the original input.
Results from the paper:
- Block AttnRes matches the loss of a baseline LLM trained with 1.25x more compute.
- Inference latency overhead is less than 2%, making it a practical drop-in replacement
- On a 48B parameter Kimi Linear model (3B activated) trained on 1.4T tokens, it improved every benchmark they tested: GPQA-Diamond +7.5, Math +3.6, HumanEval +3.1, MMLU +1.1
The residual connection has mostly been unchanged since ResNet in 2015.
This might be the first modification that's both theoretically motivated and practically deployable at scale with negligible overhead.
More details in the post below by Kimi👇
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
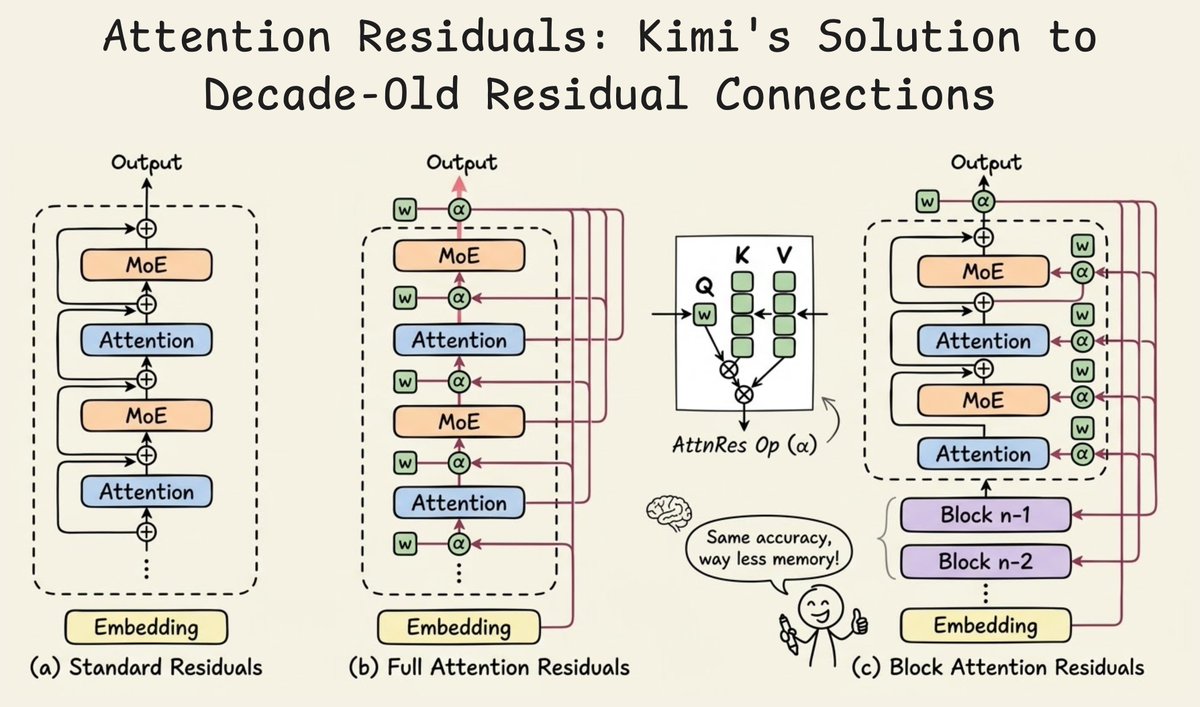
Kimi.ai@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
English
@vivek_2332 @karpathy I agree with you very much. But indeed, in the case of limited resource time, it is still necessary for people to make priority judgments in a candidate set, and then give resources to those experiments with higher priority and higher probability of success.
English

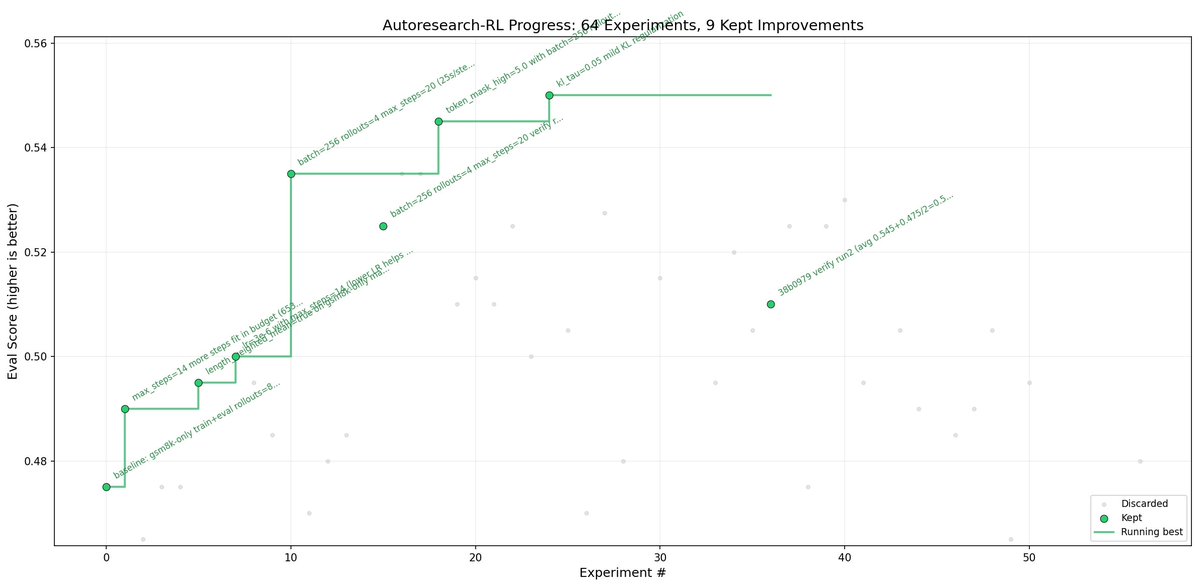
introducing autoresearch-rl, autonomous research for rl post-training.
inspired by @karpathy autoresearch, and i think rl post-training is honestly one of the places where this idea fits perfectly. there are at least 50+ hyper parameters to tweak, learning rate, batch size, rollouts, clipping ratios, kl penalties, schedulers, the list goes on. instead of sitting there for hours turning knobs one at a time, just let the model figure out the right starting config on its own.
some things worth mentioning:
-> built on @PrimeIntellect prime-rl (my favourite rl post-training framework) and @willccbb verifiers for reward verification.
-> ran qwen2.5-0.5b-instruct on gsm8k across 60+ autonomous experiments. eval score went from 0.475 to 0.550 and the agent actually found a way to do it in fewer steps (20 instead of 30). less compute, better results
-> the whole thing was surprisingly smooth to set up and run. point the agent at the config, go to sleep, wake up to a full experiment log. i really wish i could try this on a bigger model but gpu poor for now lol
-> the agent discovers things you wouldn't think to try. like how rollouts = 4 beats rollouts = 8, or how a constant lr schedule outperforms cosine. it just methodically tests everything
i think the real value here is that rl training is so fragile and noisy that having an agent patiently run experiment after experiment is genuinely more effective than a human doing it manually.
check it out:
github.com/vivekvkashyap/…
English
Another personalized vaccine
Yale University@Yale
Personalized vaccines may soon be closer to reality. Yale researchers have developed a deep-learning model that could help scientists design vaccines tailored to individual patients, allowing the immune system to better target cancer and certain infectious diseases. See how the model could advance personalized vaccine research: bit.ly/4slJefb
English
Serious question: who is actually using OpenClaw?
Not "I installed it once."
Actually using it. Daily. For real tasks.
What are you running on it?

English
I agree with you very much. AI, like electricity, is changing the life and work of human society. The way of organizing and coordinating the work will also be profoundly changed.
Alex Banks@thealexbanks
claude cowork is the next natural evolution of technology. we've moved from search engines (google) → answer engines (AI chatbots) → action engines (cowork). the only constraints today are appropriate context setting + robust interoperability between your applications. if you can orchestrate this, then you are quite literally the conductor of your own orchestra.
English
I think open scientific research and papers are very interesting. Just like you have a new discovery, you send it out first and tell everyone that you discovered it first. It is very similar to blockchain, transparent, open and accountable.
arXiv.org@arxiv
When you support arXiv, you're supporting 35 years of open science. That's... 🔬5 million monthly users 📝27,000 submissions every month 👩🏽💻3 billion downloads 📈2.9 million scientific articles shared Give to arXiv today! givingday.cornell.edu/campaigns/arxiv
English
@attaalong And I still don't understand people who say that writing code with AI is bullshit.
26 years on the street, now speed matters
English
Someone is running Claude Code inside Codex.
I saw it with my own eyes.
I need therapy.
English