Sabitlenmiş Tweet

introducing autoresearch-rl, autonomous research for rl post-training.
inspired by @karpathy autoresearch, and i think rl post-training is honestly one of the places where this idea fits perfectly. there are at least 50+ hyper parameters to tweak, learning rate, batch size, rollouts, clipping ratios, kl penalties, schedulers, the list goes on. instead of sitting there for hours turning knobs one at a time, just let the model figure out the right starting config on its own.
some things worth mentioning:
-> built on @PrimeIntellect prime-rl (my favourite rl post-training framework) and @willccbb verifiers for reward verification.
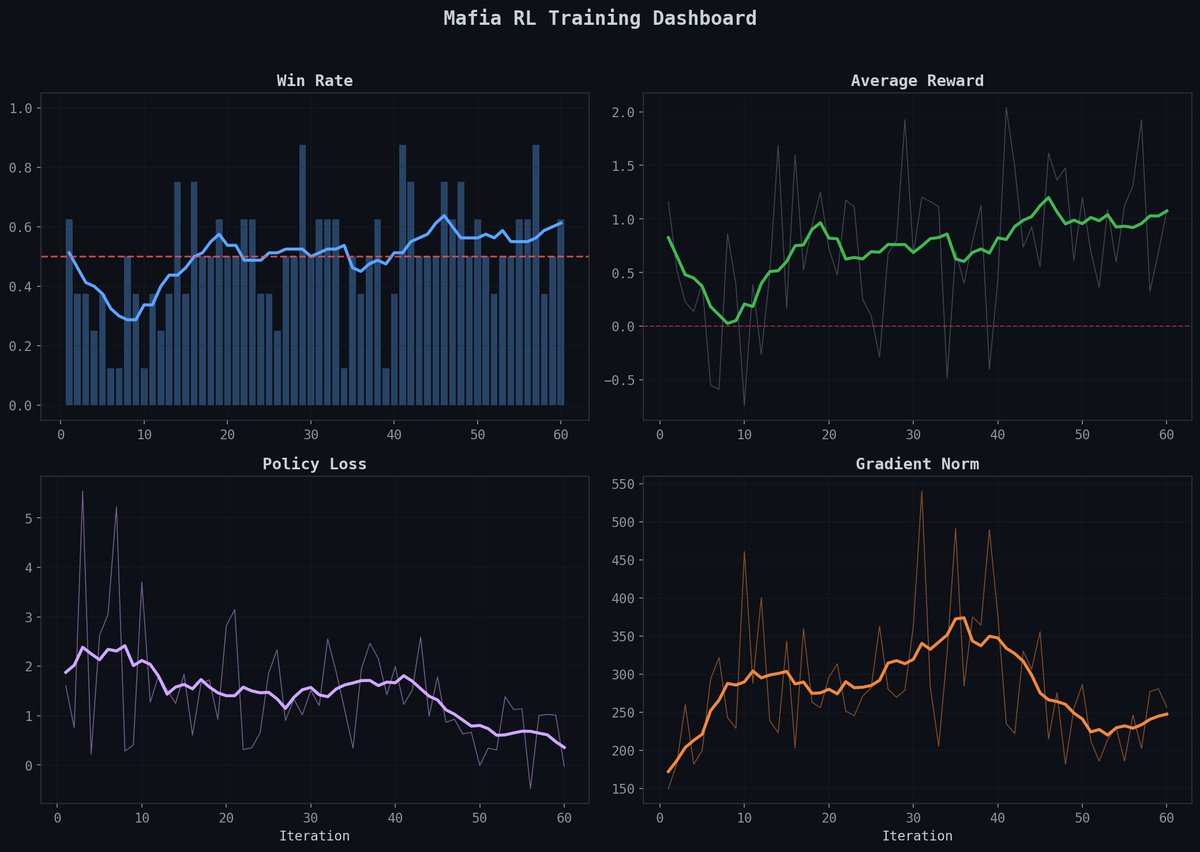
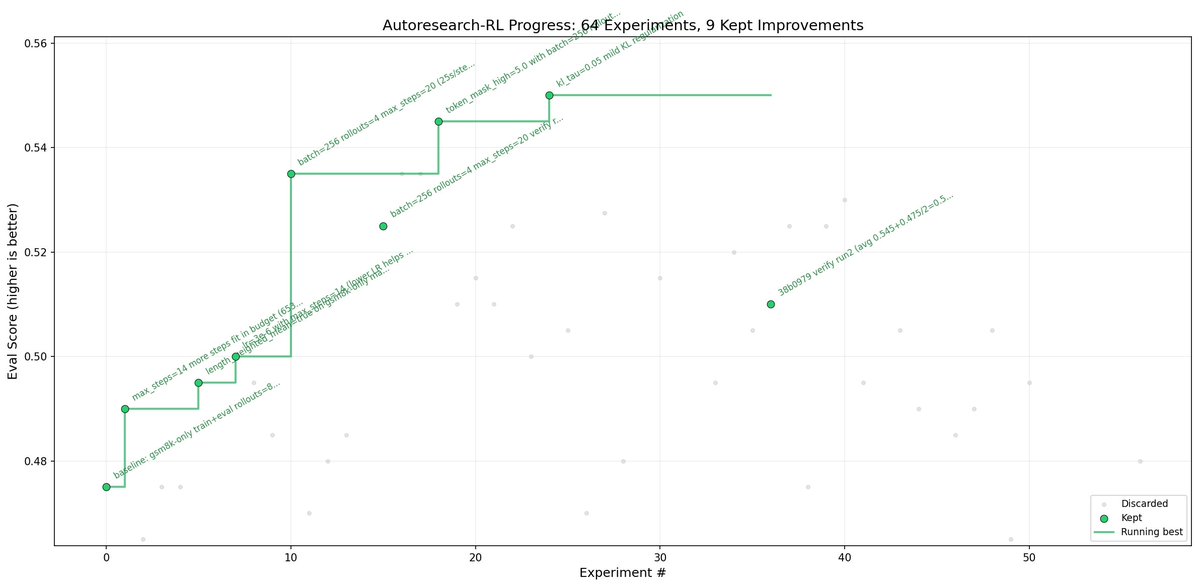
-> ran qwen2.5-0.5b-instruct on gsm8k across 60+ autonomous experiments. eval score went from 0.475 to 0.550 and the agent actually found a way to do it in fewer steps (20 instead of 30). less compute, better results
-> the whole thing was surprisingly smooth to set up and run. point the agent at the config, go to sleep, wake up to a full experiment log. i really wish i could try this on a bigger model but gpu poor for now lol
-> the agent discovers things you wouldn't think to try. like how rollouts = 4 beats rollouts = 8, or how a constant lr schedule outperforms cosine. it just methodically tests everything
i think the real value here is that rl training is so fragile and noisy that having an agent patiently run experiment after experiment is genuinely more effective than a human doing it manually.
check it out:
github.com/vivekvkashyap/…
English