Andrey Kovalev retweetledi

Andrey Kovalev
2K posts


@avkovaleff
Security engineer at @Google. Tweets are my own.




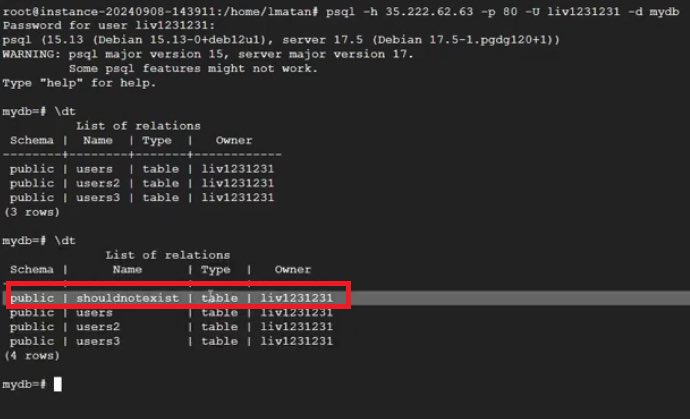



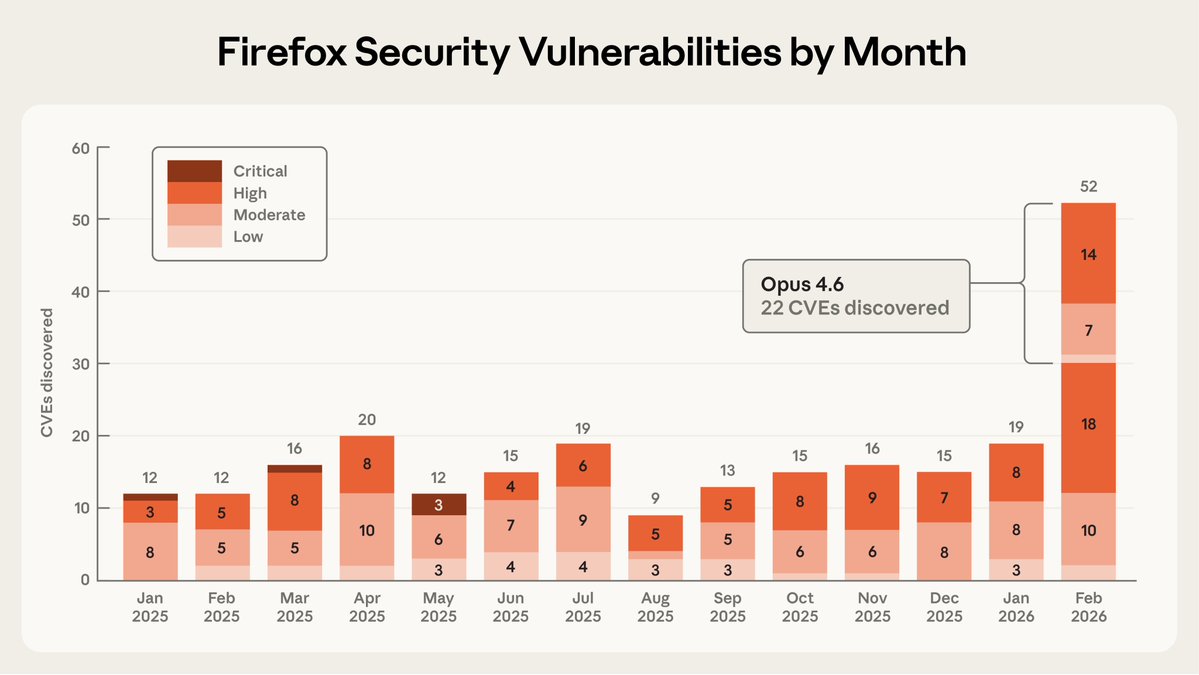




Nicholas Carlini at [un]prompted. If you know Carlini, you know this is a startling claim.


How come the NanoGPT speedrun challenge is not fully AI automated research by now?



Introducing Claude Code Security, now in limited research preview. It scans codebases for vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix issues that traditional tools often miss. Learn more: anthropic.com/news/claude-co…




Got access to OpenAI's Aardvark today, it's quite a goated tool to find security vulnerabilities.


