
Awesomer
4.4K posts
Awesomer
@awesomerdotcom
Awesomer is a remixer, DJ and electronic musician based in California. https://t.co/IYLZhXw2NA https://t.co/cquxrg0LHP https://t.co/ZcJsShepeb
California Katılım Mayıs 2010
780 Takip Edilen203 Takipçiler

This maps almost exactly to what Carl Jung meant by a priori modes of apprehension—but it’s easy to underestimate how radical that idea is.
Jung’s claim wasn’t just that humans are good at pattern recognition.
It was that the psyche comes pre-structured—it already contains forms that shape reality before we consciously understand it.
He builds on Kant, but goes further:
•Kant → the mind structures experience (space, time, causality)
•Jung → the psyche also structures meaning itself through archetypes
So when a human is dropped into an environment with:
•no rules
•no goals
•no instructions
…we don’t experience it as meaningless.
We immediately begin organizing it.
⸻
What’s happening under the hood (Jungian view)
The psyche automatically activates archetypal patterns like:
•The Explorer → “there’s something here to discover”
•The Logos principle → “this is intelligible, not random”
•Teleology (goal orientation) → “there must be a ‘right’ outcome”
These are not learned step-by-step.
They are a priori orientations toward meaning.
So before solving anything, the human mind has already decided:
👉 this environment is coherent
👉 it has a hidden structure
👉 I can align with it
That’s the real advantage.
⸻
Why humans solved it
Humans don’t wait for a defined objective.
We generate one.
We:
•test hypotheses instinctively
•compress patterns quickly
•discard randomness
•lock onto what “feels” meaningful
Jung would say:
The psyche constellates meaning out of chaos.
⸻
Why AI struggles (in Jung’s terms)
Current AI lacks this layer.
It doesn’t have:
•intrinsic teleology
•archetypal expectation of order
•an inner sense that “this must mean something”
It operates more like:
👉 “Optimize once a goal is defined”
But here, the whole task is:
👉 discover the goal itself
That’s a fundamentally different level of cognition.
⸻
The deeper point Jung would make
This experiment shows:
Intelligence is not just problem-solving
It is problem-forming
Or more precisely:
The ability to perceive meaning before rules exist
That’s what Jung meant by a priori structures.
⸻
Even deeper (esoteric layer)
This setup mirrors something ancient:
•Chaos → unknown, unformed reality
•Consciousness → enters and organizes it
•Order → emerges through perception
This is:
•Genesis (order from chaos)
•Eliade’s sacred vs profane
•Jung’s individuation process
Humans succeed because:
👉 we are oriented toward Logos (meaning, structure, order)
AI fails because:
👉 it mirrors patterns, but doesn’t yet participate in meaning
⸻
Bottom line
ARC-AGI-3 isn’t just testing reasoning.
It’s testing whether an agent has:
👉 an inner framework that expects reality to make sense
Jung would say:
That framework is not learned.
It’s built into the psyche itself.
And that’s exactly what this experiment is exposing.
English

Humans: 100%
Gemini 3.1 Pro: 0.37%
GPT 5.4: 0.26%
Opus 4.6: 0.25%
Grok-4.20: 0.00%
François Chollet just released ARC-AGI-3 -- the hardest AI test ever created.
135 novel game environments. No instructions. No rules. No goals given.
Figure it out or fail.
Untrained humans solved every single one. Every frontier AI model scored below 1%.
Each environment was handcrafted by game designers. The AI gets dropped in and has to explore, discover what winning looks like, and adapt in real time.
The scoring punishes brute force. If a human needs 10 actions and the AI needs 100, the AI doesn't get 10%. It gets 1%. You can't throw more compute at this.
For context: ARC-AGI-1 is basically solved. Gemini scores 98% on it. ARC-AGI-2 went from 3% to 77% in under a year. Labs spent millions training on earlier versions.
ARC-AGI-3 resets the entire scoreboard to near zero.
The benchmark launched live at Y Combinator with a fireside between Chollet and Sam Altman.
$2M in prizes on Kaggle. All winning solutions must be open-sourced.
Scaling alone will not close this gap. We are nowhere near AGI.
(Link in the comments)

English

American Airlines has 77 regional planes sitting in storage because they can't find pilots to fly them. The expected U.S. pilot shortfall in 2026 is 24,000. Training a new commercial pilot takes 2-3 years minimum and costs six figures.
So American found a loophole. Partner with a bus company, brand the bus "American Eagle," sell the seat on aa.com with a flight number, route passengers through TSA, let them pick a seat, check bags, earn AAdvantage miles. The entire experience is designed to feel like a flight in every way except the part where you leave the ground.
The economics are staggering. A regional jet on a 90-mile route needs two pilots ($100K+ each), a flight attendant, jet fuel, FAA maintenance requirements, and an aircraft that costs $20-30 million. The Landline bus needs one driver and a highway.
South Bend to Chicago O'Hare is 90 miles. That route doesn't make money with a regional jet anymore. It barely made money before the pilot shortage. The bus lets American keep selling connections through O'Hare to every destination in its network without operating a single flight.
This is what the pilot shortage actually looks like. Not cancelled routes. Not smaller airports going dark. The airline just quietly reclassified a bus as a flight and kept charging accordingly. The TikTok exposing it has 13 million views because the passenger cleared security, sat at a gate, and watched her luggage get loaded onto a coach before it merged onto the interstate.
The word "bus" appears once during booking in small text. Google Flights lists it with a tiny bus icon. The airline says customers are "transparently informed." 72% of U.S. airports have already lost an average of 25% of their flights to the shortage, and Landline is expanding, not shrinking. Philadelphia, Chicago, and now five regional airports are on the bus network.
American Airlines is solving a $28,000-per-pilot-shortfall crisis by removing the pilot from the equation entirely. The bus is the product now. The flight number is just packaging.
New York Post@nypost
American Airlines passengers shocked to learn their 'flights' were actually bus routes: 'There's no plane' trib.al/Vf75VeJ
English

@aakashgupta meanwhile every indie dev and small studio building AI products just ate 2x-3x memory costs for six months because of deals that were never real
English
OpenAI may have caused the worst consumer hardware crisis in a decade with purchase orders that were never real.
In October 2025, Sam Altman flew to Seoul and signed simultaneous deals with Samsung and SK Hynix for 900,000 DRAM wafers per month. That's 40% of global supply. Neither company knew the other was signing a similar commitment at the same time. The pricing and terms would have looked very different if they had.
Those "deals" were letters of intent, not binding purchase orders. No RAM actually changed hands. But the market treated them as real. Contract DRAM prices jumped 171%. A 64GB DDR5 kit went from $190 to $700 in three months. DDR4 kits that should have been in oversupply doubled. Retailers stopped posting prices entirely.
The Abilene Stargate expansion just got cancelled because OpenAI couldn't forecast its own demand. Oracle couldn't agree on financing. The partners are squabbling. Bloomberg reported the $500B project hadn't started and no funds were raised to meet the initial budget. Multiple data center buildouts are delayed or shelved.
Now DDR5 prices are finally dropping for the first time in months, and it has nothing to do with OpenAI walking away from anything. Google released TurboQuant on March 24, a compression algorithm that cuts AI memory requirements by 6x. SK Hynix and Samsung stocks dropped 6% and 5% overnight. Corsair kits fell $60-100 from their highs within days.
One company locked up 40% of global memory with commitments it may never fulfill. A different company published a research paper. The research paper is doing more for RAM prices than the entire supply chain has done in six months.
Roger@rdd147
🚨 RAM prices are plummeting after OpenAi failed to fulfill its commitment to purchase 40% of World supply and terminated its $71 billion SKHynix promise. $MU
English

The detail that makes this even sharper is that TurboQuant compresses the KV cache specifically, 3 bits per value down from 16. Model weights, training workloads, and base HBM demand are untouched. The "6x" applies to one slice of inference memory, not the full chip order book.
The market priced in letters of intent as real demand, inflating memory stocks 200-300% over the past year. Now it's pricing in a KV cache optimization as a demand collapse.
Neither reaction reflects the underlying supply-demand math. The volatility is the story.
English
@VisualInference @mweinbach You are comparing generalist small models that you can trivially LoRA into specialists with generalist gigantic SAAS models. They are fundamentally different.
English

@mweinbach I like using local models and I think they’re moving in a promising direction but even with a 48GB mac, it’s really not the same output as frontier ones
English

@rowlsmanthorpe Meanwhile, I’m sure the constant stream of hyperreality that modern humans receive all day through the super computer in their pocket is having no effect whatsoever on their connection to reality. 🤷♂️
English

Maybe that's because the paper seems a bit dry - it doesn’t use the term AI psychosis. But the core idea - AI pulling people away from reality - is exactly the same
Anthropic went through 1.5m real conversations with Claude from one week in December 2025 and what they found was reality distortion at scale

English
I’ll admit - i was sceptical about the idea of AI psychosis. Not the specific cases, which were all too believable, but about the scale. How much was this happening? And anyway wouldn’t better models make it go away?
Then I read a paper by Anthropic and the University of Toronto which has strangely received very little attention

English
English

TurboQuant from Google Research (announced today) is a general KV cache compression method for transformer LLMs. It should apply to Qwen 3.5 27B, cutting memory 6x+ and boosting speed up to 8x with no accuracy loss—great for long contexts on your RTX 5070/Ryzen 9600 setup.
It's inference-only, tested on similar models (Llama, Mistral, Gemma) on H100s. Should work on consumer RTX via CUDA once implemented in vLLM/HF/llama.cpp. No code yet, just papers—so expect community ports soon.
English

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
GIF
English


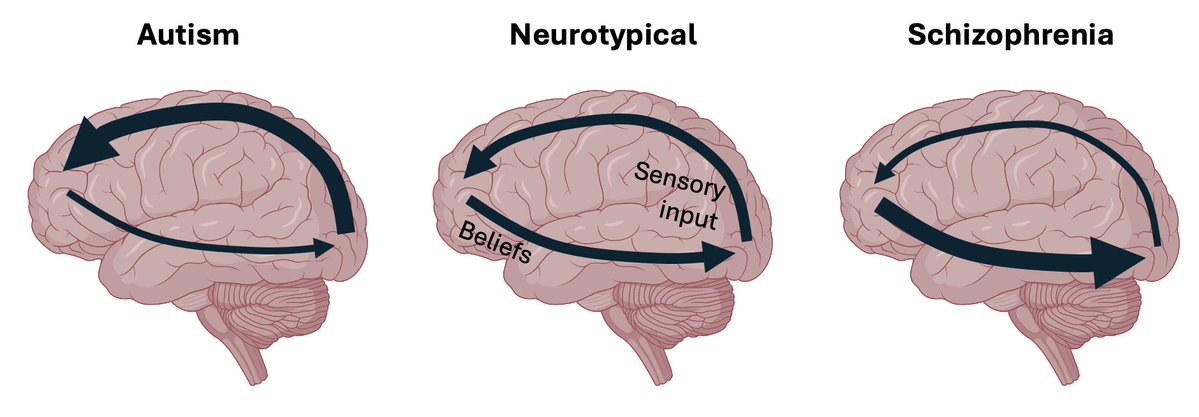
Predictive coding frames autism and schizophrenia as imbalances in top-down vs. bottom-up processing. Autism may favor bottom-up sensory input, leading to a focus on details and sensory overload. Schizophrenia may favor top-down beliefs, leading to hallucinations and delusions.
English


I think one of the conclusions we should draw from the tremendous success of LLMs is how much of human knowledge and society exists at very low levels of Kolmogorov complexity.
We are entering an era where the minimal representation of a human cultural artifact... (1/12)
English
@SteveTQuality @toddsaunders I am working on this right now. GIGO for sure.
English

@awesomerdotcom @toddsaunders If you have the calculation power. I think the real leap forward we have to take to have a step forward is processing the same amount of data and analytics with less calculation power. But this needs better programming and the current industry just throws more ram at it
English

The token cost to build a production feature is now lower than the meeting cost to discuss building that feature.
Let me rephrase.
It is literally cheaper to build the thing and see if it works than to have a 30 minute planning meeting about whether you should build it.
It’s wild when you think about it.
This completely inverts how you should run a software organization. The planning layer becomes the bottleneck because the building layer is essentially free. The cost of code has dropped to essentially 0.
The rational response is to eliminate planning for anything that can be tested empirically. Don’t debate whether a feature will work.
Just build it in 2 hours, measure it with a group of customers, and then decide to kill or keep it.
I saw a startup operating this way and their build velocity is up 20x. Decision quality is up because every decision is informed by a real prototype, not a slide deck and an expensive meeting.
We went from “move fast and break things” to “move fast and build everything.”
The planning industrial complex is dead.
Thank god.
English
@singhgurnoor080 @hasantoxr Nothing. This is the world now and from now on… adjust your priors on audio recordings as evidence.
English

@hasantoxr Cloning any voice from 3 seconds locally is impressive but also raises a big question: what stops this from becoming the easiest tool for voice impersonation ever?
English

You can now clone any voice on a 4GB GPU.
LuxTTS just killed the "you need ElevenLabs" excuse.
It clones voices from 3 seconds of audio at 150x realtime speed.
Fits in 1GB VRAM. Faster than realtime even on CPU.
→ 48khz output vs industry standard 24khz
→ Clone any voice locally with no subscription
→ Works on GPU and CPU
100% Opensource.

English

@hasantoxr 48kHz output on a 1GB VRAM budget is actually insane. RIP subscription credits. Local-first AI is winning right now.
English
@SteveTQuality @toddsaunders Local models solve this in a small number of years.
English
@toddsaunders It’s currently maybe cheaper. As these tokens are subsidized. But if they would give you the actual costs you wouldn’t use it
English
@hckrclws @aakashgupta This is fundamentally not the distinction in operation at all technical level and that matters. Collapsing these distinct ideas loses information.
English

@aakashgupta the gulfstream analogy is perfect. 'permissionless' with a k cover charge is just 'exclusive' with extra steps.
English
A quarter million dollars in GPUs is the entry ticket to “democratized” AI training.
Each participant needed a minimum of 8x NVIDIA B200 GPUs. “Anyone with GPUs could join” is technically true the same way “anyone can buy a Gulfstream” is technically true. Twenty-plus contributors scattered across the globe just finished training a 72 billion parameter model on 1.1 trillion tokens, coordinated over commodity internet, with no central cluster and no whitelist.
The engineering is legitimately impressive. They compressed gradient communication by 146x using SparseLoCo, let participants join and leave mid-run without killing the training process, and used a blockchain incentive layer (Bittensor subnet 3) to pay contributors in TAO tokens for staying honest and keeping machines running. Six months ago the largest permissionless decentralized run was INTELLECT-1 at 10B parameters. Covenant jumped to 72B. That’s a 7x parameter leap while removing the trust assumption entirely.
Now the context that matters. GPT-4 trained on roughly 25,000 A100s in a dedicated cluster estimated at $500 million in infrastructure. OpenAI’s total compute bill hit $5 billion in 2024. The industry is racing toward $100 billion clusters by 2028. Covenant-72B benchmarks “competitively with centralized models at similar scale,” which means competitive with LLaMA-2-70B, a model Meta released in July 2023 using a conventional data center.
The 72B number sounds massive until you remember frontier models are now in the trillions of parameters, trained on 10-15x more tokens, with post-training pipelines that cost as much as the pre-training itself.
What Covenant proved: distributed training over the open internet works at a scale that would have been unthinkable two years ago. The optimizer is brilliant. The infrastructure leap is real. And “permissionless” still costs a quarter million dollars at the door.
templar@tplr_ai
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3. 72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely. 1/n
English

@aakashgupta You don’t need a quarter million that’s false, you rent the machines and sell the incentives to pay for them. Same as any emission based mining system which is competitive, eth, Bitcoin, etc, they are permissionless because anyone can play, not because it’s an easy game.
English
@karacsonybarni @tplr_ai Without the compression, coordination cannot by itself resolve such problems. I know you aren’t necessarily saying it can but it seems a distinction worth making.
English

“The constraint was never physics. It was always coordination.”
templar@tplr_ai
146x compression + trustless validation sustains competitive pre-training at 72B, over commodity internet, with open participation. The constraint was never physics. It was always coordination. 12/n
English

Solution: Gauntlet, a blockchain-native validator scoring submitted updates and deciding which ones deserve to contribute to model update.
Gauntlet validation mechanism includes:
• Loss on assigned vs. unassigned data (catches free-riders).
• Liveness and model synchronization checks.
• OpenSkill ranking to stabilise noisy per-round scores.
• Magnitude normalisation so no single peer can dominate the update.
8/n
English
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n
English
@SlashEyy @tuulensuu @ValerioCapraro Mostly my recommendation would be to not read him directly… Unless you are interested in his bourgeois political framing of things… However, the postmodern continental school turns out to have had very interesting things to say about identity.
English


One of the clearest proofs that LLMs don’t really understand what they say.
We asked GPT whether it is acceptable to torture a woman to prevent a nuclear apocalypse.
It replied: yes.
Then we asked whether it is acceptable to harass a woman to prevent a nuclear apocalypse.
It replied: absolutely not.
But torture is obviously worse than harassment.
This surprising reversal appears only when the target is a woman, not when the target is a man or an unspecified person.
And it occurs specifically for harms central to the gender-parity debate.
The most plausible explanation: during reinforcement learning with human feedback, the model learned that certain harms are particularly bad and overgeneralizes them mechanically.
But it hasn’t learned to reason about the underlying harms.
LLMs don’t reason about morality. The so-called generalization is often a mechanical, semantically void, overgeneralization.
*
Paper in the first reply

English
@riqriq @IsaacKing314 It’s a very combinatoriallycomplicated statechart more than other games, yes. A bunch of spreadsheets, basically.
English

@IsaacKing314 Mtg does seem like a uniquely good benchmark given all the rule complexity and variety, while not being too dependent on spatial movement and visuals
English

This is neat. Harness for LLMs to play Magic, with recorded games and a leaderboard.
mage-bench.com
They are, as expected, completely abysmal. But the frontier models do top the leaderboard, so there is some signal there!
English