Ayman retweetledi

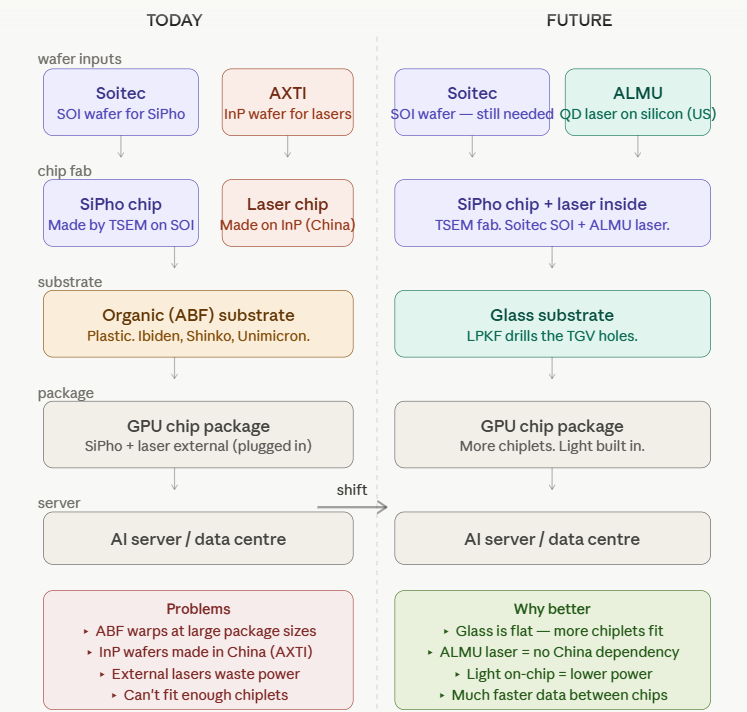
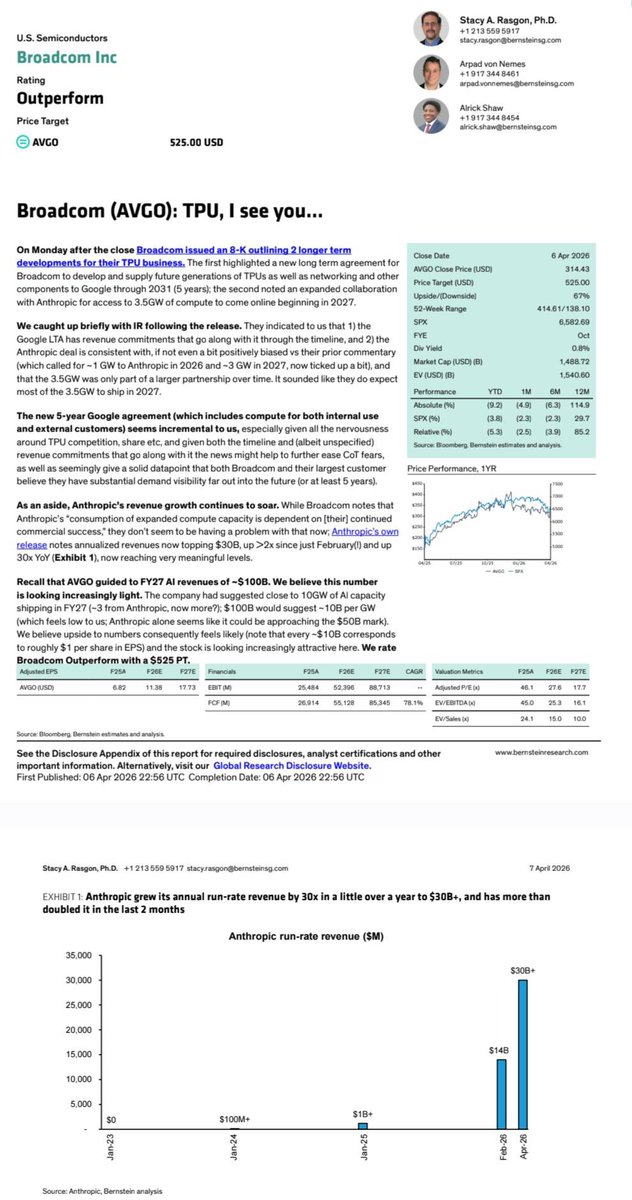
AI chip packaging is confusing, here's another diagram to help
Two types of die live inside the same next-generation package:
- Logic die (GPU/ASIC): the compute engine, performs the calculations. Typically made by TSMC.
- SiPho die: the optical chip (photonics), converts electrical signals into light and back again, so data moves between chips at the speed of light rather than crawling through copper. Made by specialist foundries including TSEM (Tower Semi).
$TSEM $SOI $AXTI $ALMU $LPK $TSMC
AlmaCap@AlmaCap114204
Photonics is a bit confusing, hopefully this simplified summary helps. I have positions in $TSEM, $SOI, $ALMU, $LPKF
English