Barlas Oğuz retweetledi

🧠 How can we equip LLMs with memory that allows them to continually learn new things?
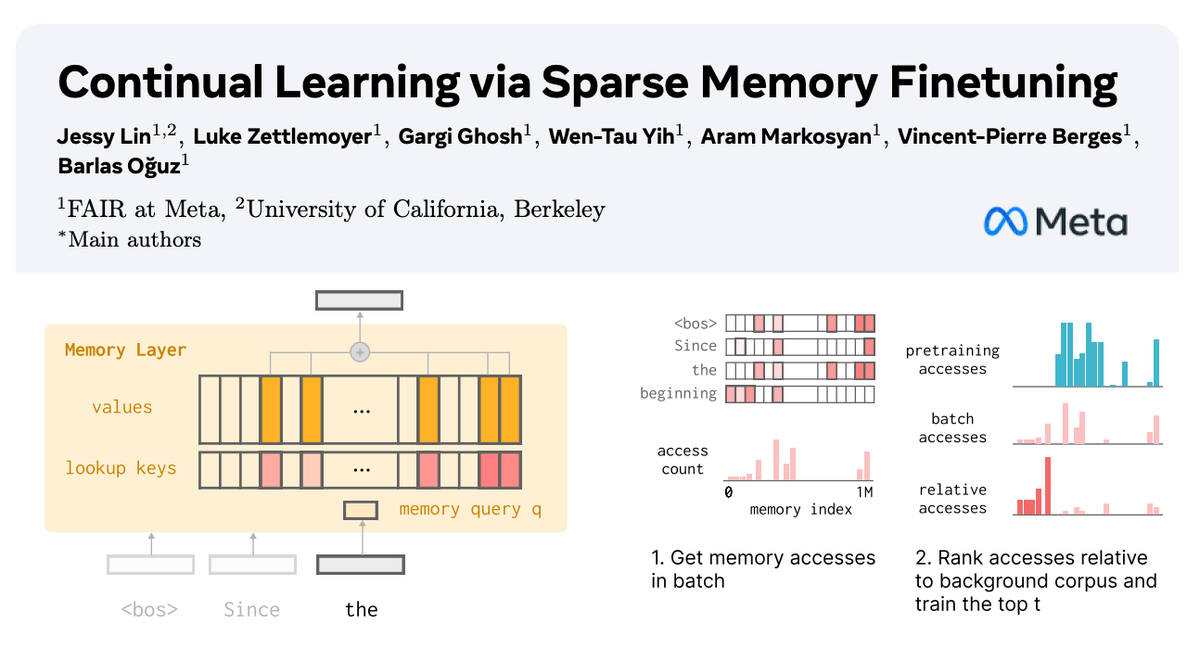
In our new paper with @AIatMeta, we show how sparsely finetuning memory layers enables targeted updates for continual learning, w/ minimal interference with existing knowledge.
While full finetuning and LoRA see drastic drops in held-out task performance (📉-89% FT, -71% LoRA on fact learning tasks), memory layers learn the same amount with far less forgetting (-11%).
🧵:
English