mason
16.2K posts

mason
@bencon9999
十多年开发经验 做过开发和产品 做过前端和Andoird 和后端,web3智能合约开发 擅长区块链和AI应用开发 分享踩坑经验 https://t.co/28aECLkwnj 公众号:Mason说科技 中转: https://t.co/RVcLLjpT4S #AI #blockchain #TCD
shanghai Katılım Ekim 2017
619 Takip Edilen171 Takipçiler




mason retweetledi

mason retweetledi

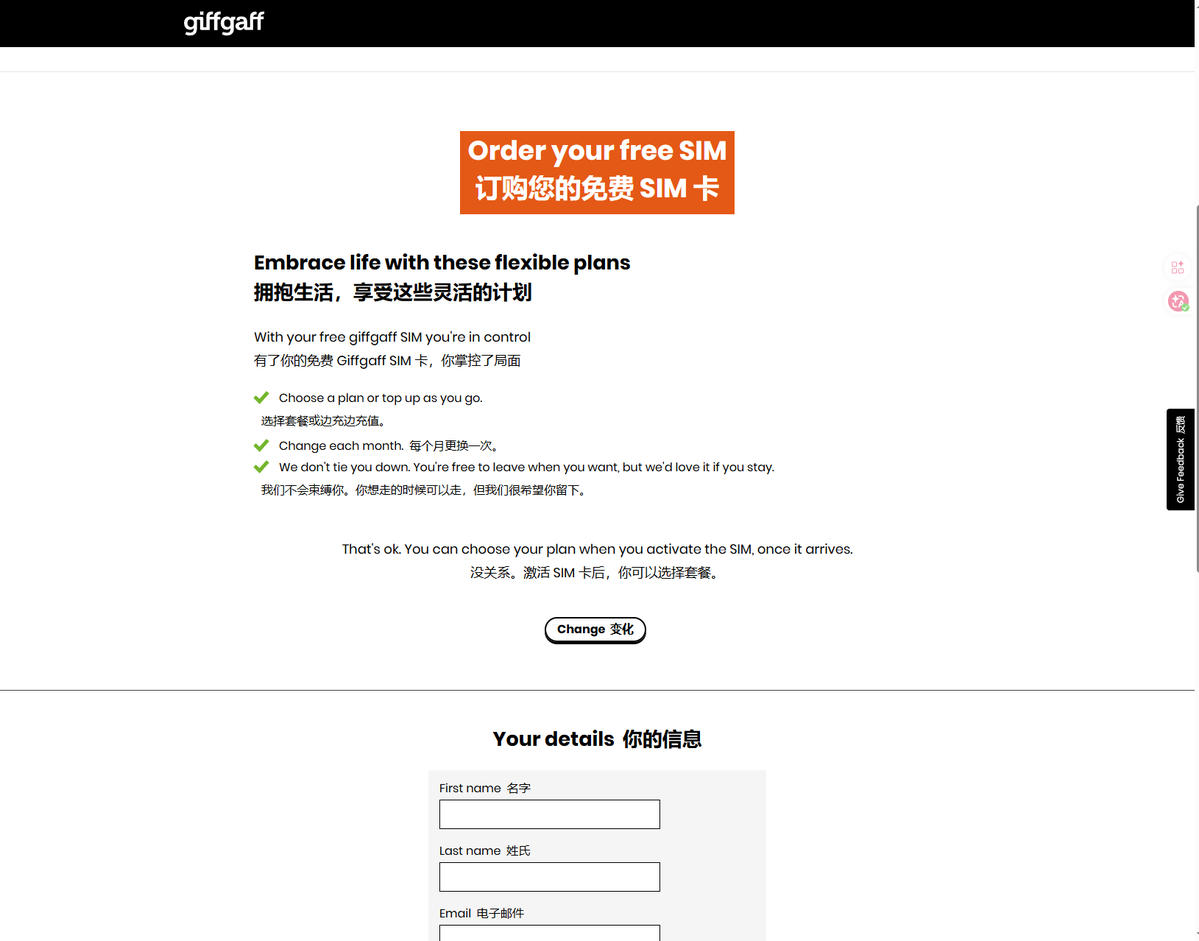
购买和激活仅需 120 元的英国短信卡 giffgaff,被全平台下架,目前闲鱼、淘宝、拼多多均无法搜到。
该卡,因为可以接收海外短信,且开卡成本较低,一度成为出海做 X、Tiktok、Youtube,注册海外 AI 账号的神器。


Minato-ku, Tokyo 🇯🇵 中文
mason retweetledi
闲鱼真的牛批。在英国短信卡 giffgaff,一夜之间被全平台下架后,大量名为 英国信封、44 信封 的商品,在各平台出现。
其中闲鱼商家这样表示,这是一封从英国漂洋过海的 + 44 小小信封,大多数人都知道它的收藏价值。
暗示是能接收境外短信的英国 gg 卡。


AB Kuai.Dong@_FORAB
购买和激活仅需 120 元的英国短信卡 giffgaff,被全平台下架,目前闲鱼、淘宝、拼多多均无法搜到。 该卡,因为可以接收海外短信,且开卡成本较低,一度成为出海做 X、Tiktok、Youtube,注册海外 AI 账号的神器。
Meguro-ku, Tokyo 🇯🇵 中文
mason retweetledi

🔥Grok真是尺度全开,除了人脸经不起放大。提示词如下,大家可以试一试:
Glossy Japanese beauty behind the railing, she is inside the veranda, she leans forward with the front facing at the position behind the railing and takes out the lingerie from the basket, spreads the lingerie to dry, no background music,
中文
mason retweetledi

发布一个新的 Skill:baoyu-youtube-transcript
输入 YouTube URL,直接抓取视频字幕,生成带章节、发言人和封面图的文档,不需要任何 API Key。
【怎么用】
选择这个 Skill,把 YouTube 链接丢进去就行。支持完整链接、短链接、嵌入链接、Shorts 链接,甚至直接输入视频 ID 都可以。
默认输出带时间戳的 Markdown 格式,也可以导出 SRT 字幕文件。支持多语言,可以指定优先语言,也可以翻译成其他语言。
第一次抓取后会自动缓存原始数据,之后换格式、换参数都不用重新请求,秒出结果。
【工作原理】
底层调用的是 YouTube 的 InnerTube API,这是 YouTube 内部用来获取字幕数据的接口,公开可用但没有官方文档。好处是不需要 Google API Key,不需要 OAuth 认证,脚本直接发请求就能拿到字幕数据。
拿到原始字幕后,脚本会做一次智能断句处理:按句末标点(句号、问号、感叹号等)切分,跨字幕片段合并成完整句子,时间戳按字符长度等比分配,对中日韩文字做了专门适配。这样输出的文本是自然的句子,不是 YouTube 那种碎片化的逐行字幕。
【章节分割】
如果视频描述里有章节时间戳(比如 "0:00 Introduction"),脚本会自动解析,按章节把字幕分段,生成带目录的 Markdown。没有章节信息的视频,就按段落分组输出。
【说话人识别】
这是最有意思的部分。YouTube 字幕本身不带说话人信息,所以识别说话人需要 AI 后处理。
流程是这样的:先用 --speakers 参数抓取原始字幕,脚本会把视频元数据(标题、频道名、简介)和 SRT 格式的原始字幕一起输出到一个 Markdown 文件里。然后启动一个 AI 子代理(用 Claude Sonnet,够用且省成本),按预设的 Prompt 模板处理这个文件。
AI 识别说话人的逻辑分三层优先级:首先从元数据推断,视频标题通常包含嘉宾名字,频道名就是主持人;其次从对话内容判断,比如自我介绍、互相称呼;都不行就用通用标签(Speaker 1、Host 之类),保持全文一致。如果后面对话中才出现名字,会回溯更新前面所有标签。
处理完的输出是带说话人标签的分段对话,长独白会被切成 2-4 句一段,每段末尾带时间范围。
【缓存机制】
第一次运行会缓存四样东西:视频元数据(meta.json)、原始字幕片段(transcript-raw.json)、断句后的字幕(transcript-sentences.json)、视频封面图(cover.jpg)。之后不管切换格式还是重新生成,都直接用缓存,不再请求网络。加 --refresh 参数可以强制刷新。
安装命令:
$ npx skills add jimliu/baoyu-skills --skill baoyu-youtube-transcript
项目地址:github.com/jimliu/baoyu-s…
宝玉@dotey
New Agent skill: baoyu-youtube-transcript 🎬 Extract YouTube transcripts directly — no API key needed. ✦ Multi-language support ✦ Chapter segmentation ✦ AI speaker identification ✦ SRT & Markdown output ✦ Smart caching for instant re-formatting Just select the skill and paste a YouTube URL and go. Install: $ npx skills add github.com/jimliu/baoyu-s… --skill baoyu-youtube-transcript
中文

mason retweetledi

Anthropic 发了一篇论文,用随机对照实验证明了一件事:
你用 AI 学新东西,大概率什么都没学会。
52 名专业开发者,任务是学习一个从没用过的 Python 库。
一半有 AI 辅助,一半没有。
结果:
• 有 AI 那组,测试得分低 17%(Cohen's d = 0.738,p = 0.01)
• 完成任务速度——没有显著差异
既没学会,也没更快。白用了。
───
但这不是"别用 AI"的故事。
研究者把所有人的录屏逐帧分析,发现了 6 种使用模式,结果天差地别:
❌ 低分模式(测试得分 24–39%):
① 全权委托:让 AI 写代码,直接粘贴,完事。得分 39%,速度最快(19.5 分钟),但啥没学到
② 渐进式依赖:开始还自己想,后来越来越懒,全交给 AI。得分 35%
③ 反复让 AI 调试:遇到报错就把错误扔给 AI,让它改。问了最多次,耗时最长(31 分钟),得分最低 24%
✅ 高分模式(测试得分 65–86%):
④ 生成后追问:让 AI 生成代码,然后追问"为什么这样写"。得分 65%
⑤ 要代码 + 要解释:一条 prompt 同时要代码和原理解释。得分 68%
⑥ 只问概念:从不让 AI 写代码,只问"这个概念是什么意思",自己动手。得分 86%,速度第二快
───
为什么会这样?
无 AI 那组遇到的报错中位数是 3 个,有 AI 那组只有 1 个。
那些 RuntimeWarning、TypeError 看起来很烦,但恰恰是它们逼你真正搞懂了一个库。
你绕过了 bug,你也绕过了理解。
───
论文里有一句参与者事后的反馈让我印象很深:
"我觉得我变懒了。用了 AI 之后,我没有像平时那样仔细看文档和示例。"
这不是个人意志力问题,这是 AI 改变了你学习路径这件事的必然结果。
───
一个可以马上用的原则:
学新东西时,把 AI 当老师,不要当外包。
问它"为什么",不要只让它"帮你做"。
遇到报错,先自己想 5 分钟,再去问。
论文全文:arxiv.org/abs/2601.20245
中文
mason retweetledi

mason retweetledi

清华团队把他们内部跑了一年多的 AI 教学系统开源了,叫 OpenMAIC。简单讲一句话:它不是一个“AI 工具”,而是一个“AI 老师系统”。
你丢一篇复杂的技术文档进去,它能在十秒内帮你拆成一个适合小白的互动课堂,带讲解、提问、练习,一步一步带你学,甚至还有点像在上网课 + 做项目的结合体。
以前我们是“用 AI 干活”,现在开始出现“AI 教 AI、AI 教人”的能力了。
如果把 OpenMAIC 做成 Skill 或 MCP Server,让龙虾随时调用,那基本就是:Agent 不会?自己去上课。不会写代码?现场生成一节课边学边写。这其实已经不是工具升级了,而是学习方式的重构。
它在做的事情,本质是在解决“知识传递效率”的问题。人类一直靠老师 + 课堂去传递知识,但这个模式在信息爆炸时代已经有点跟不上了。
而 OpenMAIC 这种多智能体课堂,本质是把“老师、助教、同学、小测、项目”全都自动化了。
甚至可以做到每个人一套节奏,每个人一套讲法。这个东西一旦跑通,教育这件事的边界会被彻底打开。
以后卖的可能不只是工具,而是“结果 + 学习能力”。比如你卖一个 AI 产品,不只是帮用户完成任务,还能顺带教会用户怎么做这件事。
甚至用户都不用看教程,直接边用边学。这个转变其实很大。

GIF
GIF
GIF
中文
mason retweetledi



我靠,就在刚刚,小米官宣了,前几天Openrouter上的匿名模型终于揭晓了,搞半天全猜错了,没想到是小米MiMo,牛逼。。。
我看了下,小米这次一口气放了3个MiMo新模型,那个很猛的匿名模型Hunter Alpha真身原来是MiMo-V2-Pro,万亿参数+百万级上下文,这基本上是国内头一个做到这个规格的吧。
我去看了下AA榜单,全球第八,中国第二,真的可以说国内第一梯队了。。。
而且这次主打Agent场景优化,我简单上手试了试,工具调用成功率确实还不错,跟Claude、Gemini那几个也能掰掰手腕。
主要是现在API还免费,我觉得这个可以当作龙虾的天选模型了==

中文
mason retweetledi


mason retweetledi


mason retweetledi

