Sabitlenmiş Tweet

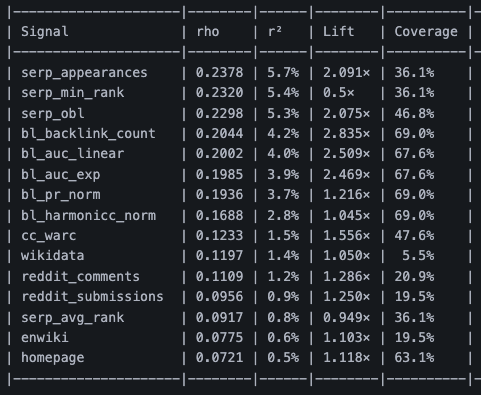
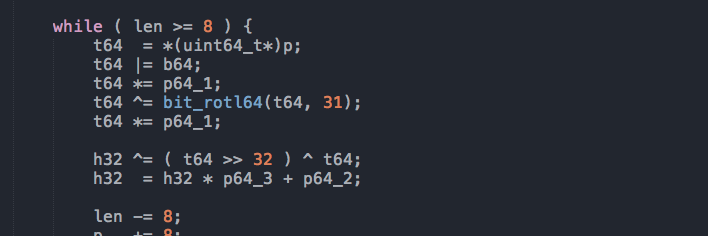
After 9 days with the Yandex code, here's what I've found that's relevant for SEOs.
First, huge credit to @iPullRank and @RyanJones. Those are a couple of smart MFers. Seeing our different strengths and perspectives and pushing each other through the code has been great.
English