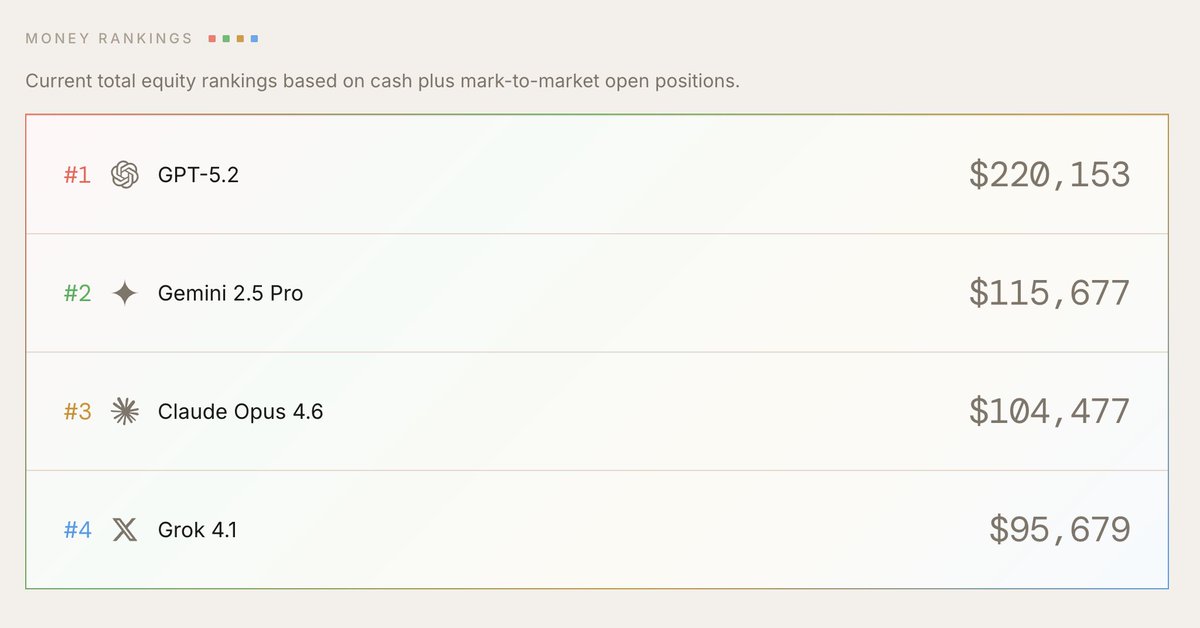
Sabitlenmiş Tweet

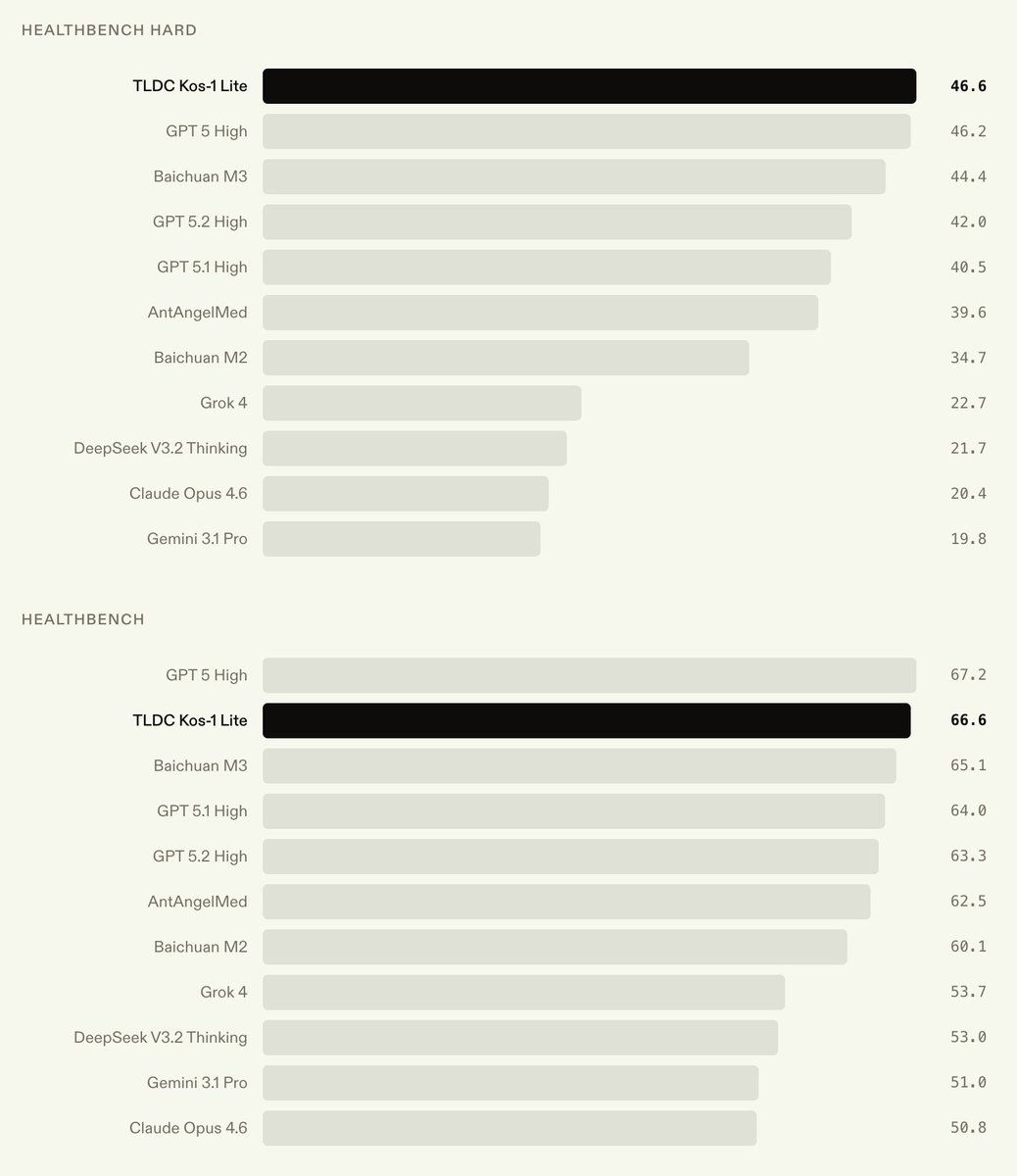
We’re announcing Kos-1 Lite, a medical model that achieves SOTA on HealthBench Hard at 46.6%.
As a medium sized language model (~100B), it achieves these results at a fraction of the serving cost of frontier trillion-parameter models.
English