Sabitlenmiş Tweet

Migration to Postgres Database from Oracle Using Apache-Spark. dbalearnings.wordpress.com/2025/01/26/mig…
English
bhavani-DBA
10.1K posts

Curious about checkpoints and WAL in PostgreSQL, and want to know more about how it works? 🐘 Shaun Thomas delved into the topic of "Checkpoints, Write Storms, and You" this PG Phriday. Give it a read to learn about - ➡️ how Postgres treats checkpoints, ➡️ how the configuration parameters affect these settings, ➡️ how to set them appropriately for optimal behavior, and ➡️ how to monitor for continued tuning. Check it out: 🔗 hubs.la/Q04bnVpj0 Questions? Drop them in the comments below 💬 #programming #postgres #postgresql #hacking #coding #engineering #dev #developer #opensource #sql #learntocode




What happens when you add server names, add more nodes to the cluster, or want to add specific connection restrictions when setting up a Patroni deployment? The routing layer handles that, using HAProxy. Shaun Thomas wraps up his 3 part series on "Using Patroni to Build a Highly Available Postgres Cluster" this PG Phriday with a walkthrough on adding HAProxy as the software or load-balancer layer that's compatible with HTTP checks. 📌 Follow along here: hubs.la/Q047JGgp0 Need to reference parts 1 & 2? 1️⃣ etcd: hubs.la/Q047JGdy0 2️⃣ Postgres & Patroni: hubs.la/Q047JyZS0 #opensource #postgresql #postgres #highavailability #patroni #foss #oss #tech #technology #programming #dataengineering #opensource

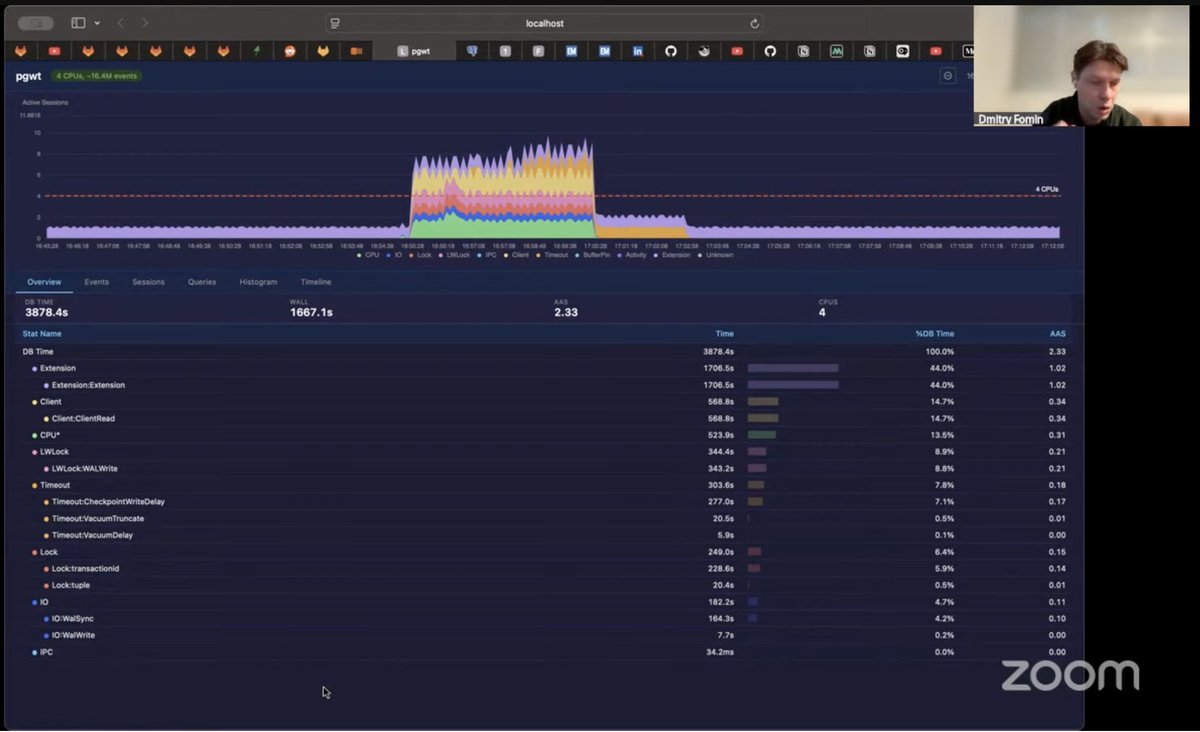
Postgres hacking session today youtube.com/watch?v=3Gtuc2… – LIVE now, join we have a great guest, Dmitry Fomin, who will show us some really cool new tool with wait event analysis (aka ASH) for heavily loaded systems




📣 PG Phridays | Part 2 Our walkthrough on building a highly available PostgreSQL cluster with Patroni continues. In this post, we move beyond the foundation and dive into configuring Postgres and Patroni together—covering how they work in tandem to manage replication, monitor cluster health, and automate failover. If you're building Postgres for resilience and uptime, this hands-on guide walks through the next critical step in creating a production-ready HA cluster. 🔗 Read Part 2: hubs.la/Q046JCVH0 #PostgreSQL #Postgres #HighAvailability #Patroni #PGPhridays #pgEdge @opensource #PostgreSQLProfessionals #PostgreSQLDBA