Bilzard retweetledi

Papers like these are important for people competing in big reasoning competitions like AIMO or ARC-AGI.
The problem is that if one takes a closer look, there are some issues with the impressive claims:
- MATH is an outdated benchmark by now
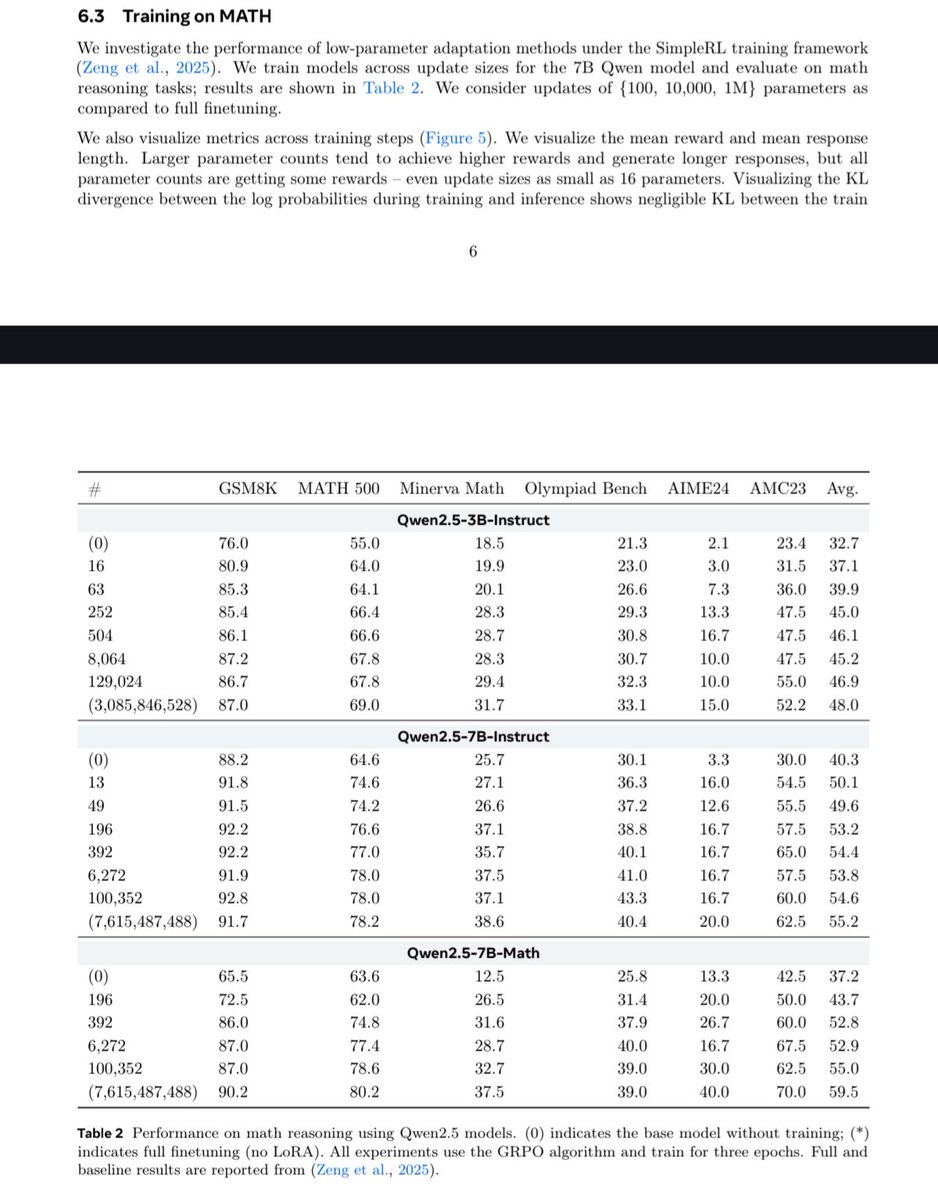
- the numbers don't add up. The last sentence on page 1 states "Qwen-2.5-7B-Instruct improves from 76% to 95% while training just 10,000 parameters". This conflicts with table 2, which in turn is also unclear, as the parameter count doesn't seem to match with the # column.
English