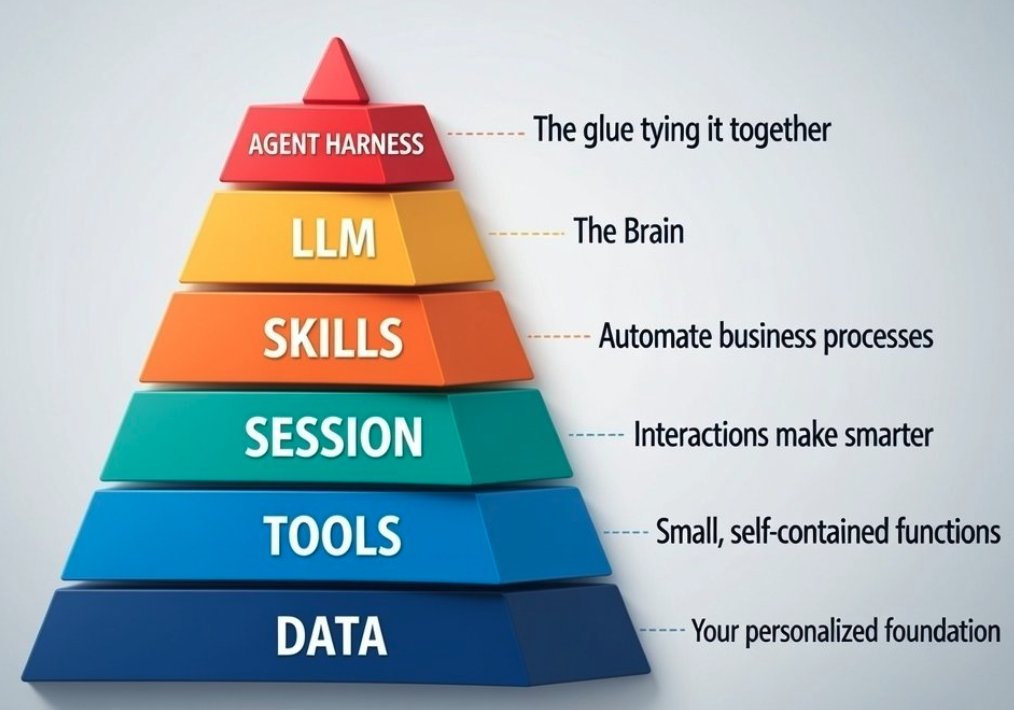
Corey Ganim@coreyganim
My predictions for AI in 2026:
1. Second brain as a service becomes hugely profitable. Companies will pay to build internal knowledge bases trained on their data.
2. Owned audiences (email, SMS, direct mail, SEO rankings) become 100x more valuable as AI spam explodes.
3. Building audience on social → converting to owned channels is the most valuable marketing skill you can learn in 2026.
4. AI content will hit 8/10 quality on basic input. Only 10/10 stands out. Taste and context are your moat.
5. Relationships become even more valuable, especially with people who have large owned audiences. Borrow their trust. 10x overnight.
6. Companies hire employees whose entire job is staying on top of AI trends to help CEOs pivot daily. Eventually these become AI agents.
7. Most powerful AI models reserved for big corporations and governments. Average users never get access.
8. Cost of AI inference scaling rapidly. My system went from $20/month to $500-1K/month in 6 months. Will 10X next year.
9. Niche communities become massive business ecosystems. 80% fail. 20% become multi-unit powerhouses.
10. Proprietary data is the single most valuable moat: customer contact data, search trends, pain points. License it. Sell it. Build competitive advantage.
11. OpenAI building accessible agent layer. When it ships, agentic era begins for everyday people.
12. Claude Code continues to be the highest-leverage skill, period.
13. AGI is closer than we think (if not already here). ASI will be 1000x more earth-shattering then even the most bullish expectations.