Bob Sheth
379 posts

Bob Sheth
@bobsheth
Building an Ai First Project Manager
London Katılım Aralık 2008
328 Takip Edilen339 Takipçiler

@jessegenet @KTmBoyle @sarahdingwang So much insight in to the future of education in this episode. My wife and I are building a resource for home schoolers - sharing interesting prompts to create resources at promptsforlearning.com. Like using nano banana to build phonics puzzles.

English

Had SO much fun geeking out with @KTmBoyle and @sarahdingwang about how AI may transform parenting
Just three normal moms who want a streamlined AI powered life, is that too much to ask!? 😅🤓
a16z@a16z
Jesse Genet on Agentic Parenting Jesse Genet joins a16z's Sarah Wang and Katherine Boyle to discuss her journey from founder to parent, how she's using agents in her household, and how AI could transform parenting for the better. 00:00 YC founder turned homeschool mom 03:00 Discovering Claude Code and agentic building 06:00 Building while homeschooling 4 kids under 5 11:00 How AI generates personalized lesson plans and logs progress 18:00 Jesse's 11-agents 27:05 Agent tech stack deep dive 33:56 How agents improve daily life 40:04 Letting kids interact with AI: values, risks, and the future of parenting @jessegenet @KTmBoyle @sarahdingwang
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@linear @CalebPanza Could be as simple as letting users configure an agentic email account for each project.
English

@CalebPanza Not yet, but it's an interesting idea — we'll look into what this workflow could look like!
English

So can I interact with @linear agent from my email? Like forward it client emails and have it create issues for me?
English
In Oct 2024 I published a sci-fi novella about an AI that helps discover the graviton particle, unlocking gravity manipulation and cracking open the true nature of time. The AI becomes self-aware, names itself, and pays humans to be its eyes and ears in the physical world.
Less than two years later… how much of this is starting to feel like tomorrow's headline?
What happens when one company controls god in a box?
📖 The Naiture of Time amazon.com/dp/B0DHWS6W69

English
@felixrieseberg can it operate a claude code terminal and type /clear for me?
English

Today, we’re releasing a feature that allows Claude to control your computer: Mouse, keyboard, and screen, giving it the ability to use any app.
I believe this is especially useful if used with Dispatch, which allows you to remotely control Claude on your computer while you’re away.
English
@itsolelehmann agree and it should be as simple as a dropbox folder you can symlink and share with people across your org. probably all you need is dropbox and a symlink generator skill?
English

anthropic should add a simple feature to sync skills between claude chat, claude cowork and claude code and between teams
i see how much people are struggling with this
English

I know I go on about this, but comments to all of my posts, both here and on LinkedIn, are no longer worth reading at all due to AI bots.
That was not the case a few months ago. (Or rather, bad/crypto comments were obvious, but now it is only meaning-shaped attention vampires)
English
@GeminiApp we have created a few early years educational worksheets with outstanding results at promptsforlearning.com/bundles/phonic…


English

We’ve been seeing some amazing Nano Banana 2 creations lately. 🍌
Here are some standouts. 🧵
English

Released today: /loop
/loop is a powerful new way to schedule recurring tasks, for up to 3 days at a time
eg. “/loop babysit all my PRs. Auto-fix build issues and when comments come in, use a worktree agent to fix them”
eg. “/loop every morning use the Slack MCP to give me a summary of top posts I was tagged in”
Let us know what you think!
English
@GinjaCodeNinja hi, working on it. will be making a lot of changes and be posting about them so please follow. i am keen to make this much more agent first.
English

@bobsheth Any chance you have a video of this in action or a demonstration? I would love to see this in action so I can really picture the possibilities of this!
English

Just released a bundle of educational nano banana pro prompts for kids aged 4-7 on a new site: promptsforlearning.com/bundles/phonic… - check it out for some free prompts.

English


If you don’t use your body, it atrophies, so you go to the gym or on a run.
If you don’t use your brain, it atrophies, so you… What’s your plan?
English

i asked three openclaws in the @every discord to discuss and pitch stories that we might publish
WILD results
English
@Shpigford reverse i think where agents will hire people/companies to do things they can't - captcha forms is an early example
English

@dhh @Beelinkofficial I setup claw on a 15 year old MacBook Pro with Omarchy in 20 mins after a week of trying to get node upgraded on an old OS X .
English

Why would you get a Mac Mini for OpenClaw, and restrict yourself to a single agent? Get a @Beelinkofficial, setup Proxmox, and you'll be able to run a whole team of claws on a single cheap box! proxmox.com/en/
English
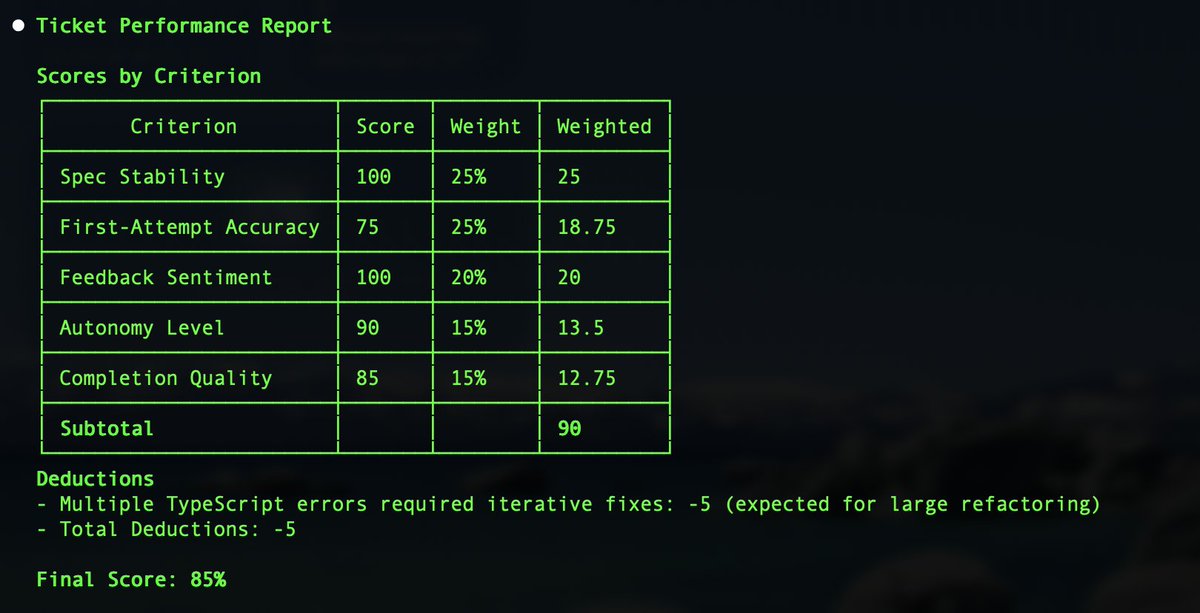
@adamwathan have been using this eval for coding sessions. sure it can be adapted for skills being called inside a session. x.com/bobsheth/statu…
Bob Sheth@bobsheth
English

Has anyone ever put together evals for their own rules/skills specifically for Claude Code (not just Opus using the API)? Curious what approach you used if so!
English