Chaoyou Fu retweetledi

🤩Next-Generation Video Understanding Benchmark🤩
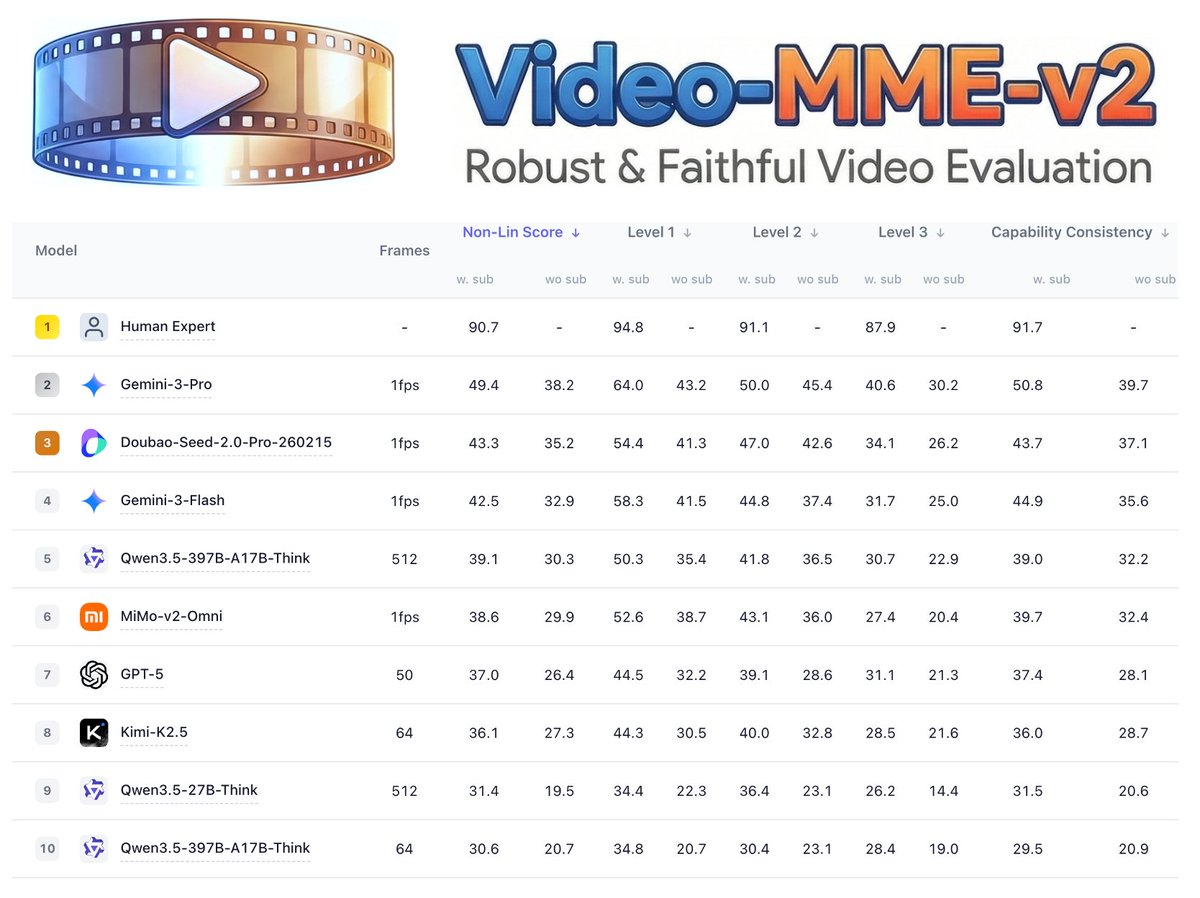
📽️Video-MME-v2📽️ provides a robust and faithful evaluation of video models with two highlights:
* Progressive Multi-Level Evaluation Dimensions
* Grouped Non-Linear Evaluation Mechanism
- Leaderboard: video-mme-v2.netlify.app
Yuhao Dong@dyhTHU
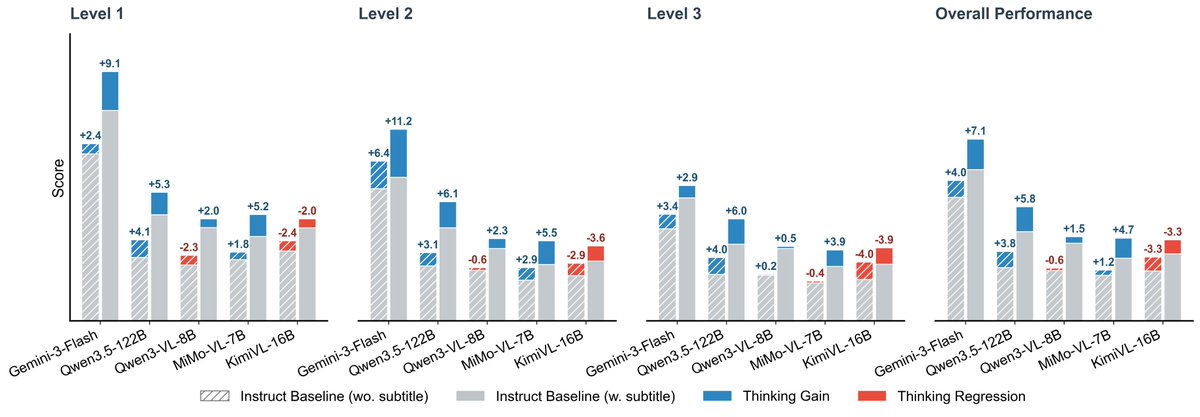
🔥 Excited to share Video-MME-v2! 🔥 We built it to tackle a growing issue: video understanding benchmarks are getting saturated. 🏃🏻 Over 3,300 human-hours, nearly a year of effort 🌟 A new design with a progressive hierarchy + group-based nonlinear evaluation What we found: 👉 Human: 90.7 vs 👉 Gemini-3-Pro: 49.4 The gap is still huge. Explore More at: Page: video-mme-v2.netlify.app Paper: arxiv.org/pdf/2604.05015
English