spending an extra 5-10 minutes on a prompt to make it self-sustaining + clear feedback loops can be a magical experience
it goes from a one-off prompt to a loop that turns compute into intelligence
the game is in finding the loops
English
Brandon Guo
358 posts

@brandonguo
data, markets



How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵

💎Autodata: an agentic data scientist to create high quality data✨ We introduce a method for building agents that create high-quality training & evaluation data. Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*. We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data. Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods. Overall, we believe this direction has the potential to change how we build AI data! Read more in the blog post: facebookresearch.github.io/RAM/blogs/auto…

Company Brain @t_blom Every company has critical know-how scattered across people's heads, old Slack threads, support tickets, and databases, and AI agents can't operate like that. We think every company in the world is going to need a new primitive: a living map of how the company works that turns its own artifacts into an executable skills file for AI.
Industrial-scale science. Coming to a lab near you this summer.

Very excited to announce the v1.0 of SlopCodeBench release: - Doubling the size of the dataset - @harborframework support - scb-check: a CLI that flags slop anti-patterns - Way more model results scbench.ai github.com/SprocketLab/sl… 🧵
TIL you get $5m in credits through a16z Speedrun

Opus 4.7 has a new tokenizer. This means it's also a new base model. Glory days of pretraining still very much going.
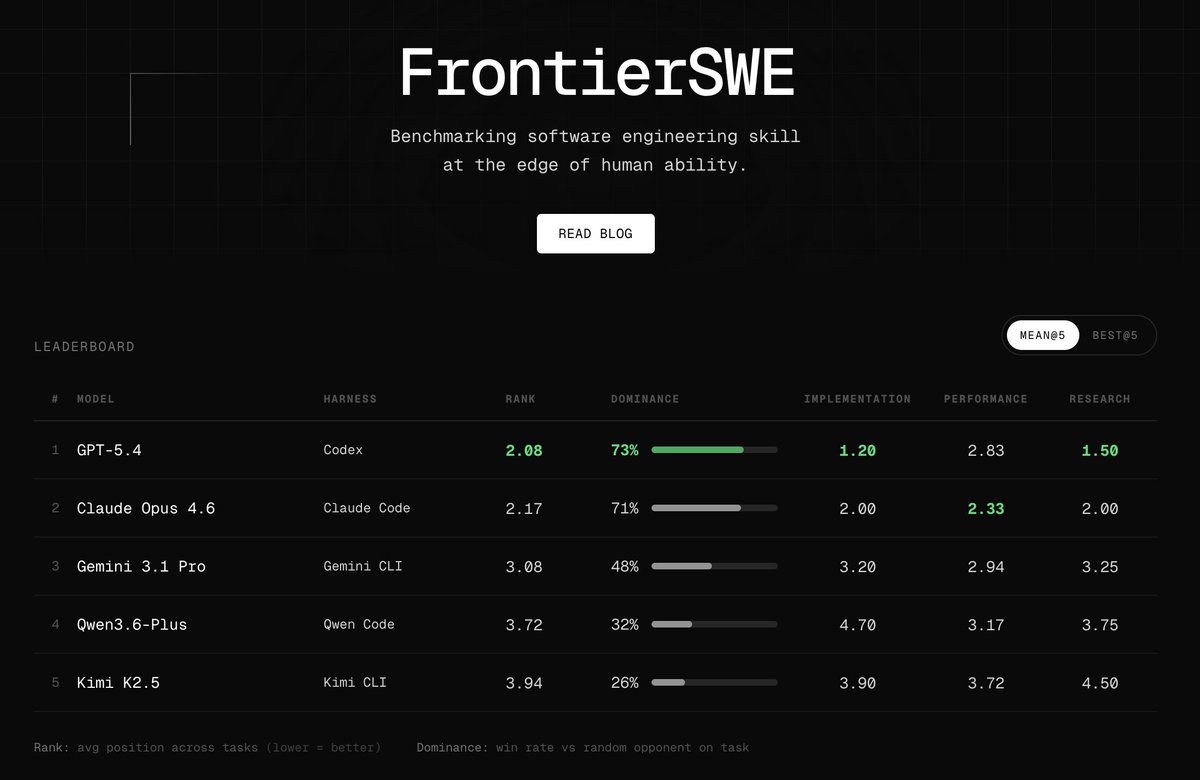
Introducing FrontierSWE, an ultra-long horizon coding benchmark. We test agents on some of the hardest technical tasks like optimizing a video rendering library or training a model to predict the quantum properties of molecules. Despite having 20 hours, they rarely succeed