Bugatt
548 posts

Bugatt retweetledi

Codex 5.5 hack:
"Are you 100% confident in this strategy? If not, find all possible loopholes, suggest proper fixes and run this loop until you are factually 100% confident in the new startegy"
This works like charm. It makes Codex 5.5 high perform even better than codex 5.5 extra high.
Why? Codex 5.5 is the only model i noticed that is self aware. It never makes high claims unless the model verifies everything.
This doesn't work with Opus 4.7 cuz that's a very insecure model. You can paste this prompt over and over again, the model keeps saying "you're absolutely right,....."
But with codex, after 2-3 iterations you'll notice yourself it actually patched all loopholes and this genuinely sounds like a good strategy.
Try this out, thanks me later.
English

If you’re a “Software Engineer” and you don’t know how to bypass this then please pivot to being a Starbucks Barista because you’re ngmi
Cormac@cormachayden_
software engineers before vs after agents
English

I'm applying to a16z @speedrun today. Anyone want to roast my application?
I'm building HITL infrastructure for AI agents in the enterprise. I dropped out a week ago to do this and I've secured a $1500 pilot with a YC company.
English



Bugatt retweetledi

Bugatt retweetledi

The reason so many intellectuals are so miserable is their denial of this. They are starving themselves of life.
Marc Andreessen 🇺🇸@pmarca
Cognition, executive function, indeed existence itself, are whole-mind/body experiences. The answer is not inward, it is outward, and in the world.
English
Bugatt retweetledi

we've spent years trying to get people off of ramp. cards that enforce policy without a portal. receipts via text. memos and categorizations generated in the background. the best experience of ramp has always been the one you don't see.
the agent shift is just the newest version of this. MCP weekly actives are up 10x in 3 months. customers are reaching into us through claude, chatgpt, and their own agents — not our interface. we're good with that.
if you're building software right now: ship an MCP, then assume your users will never see your UI again. design the tool descriptions like onboarding. make every call return the context the next call needs. treat the agent calling you like a customer, not a pipe.
Teddy Riker@teddy_riker
English

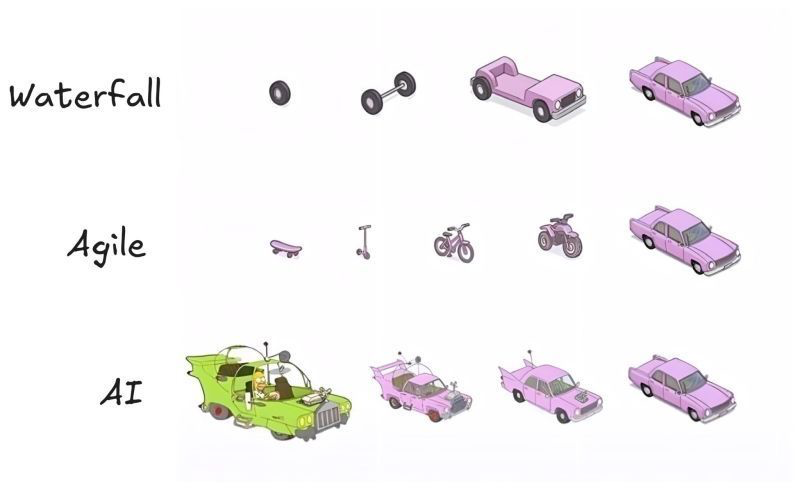
the first version AI gives you often looks slightly cursed
many sees that and panic
but big changes are now cheap. that’s why the old instinct breaks
English
Bugatt retweetledi

Bugatt retweetledi

Ok this is kind of wild.
A mystery 100B model just appeared at the top of OpenRouter out of nowhere.
No model card. No announcement. No idea which lab made it.
It's called Elephant Alpha and it's already beating half the paid models on the leaderboard.

English
Bugatt retweetledi
