BuildLocalAI retweetledi

BuildLocalAI
8 posts


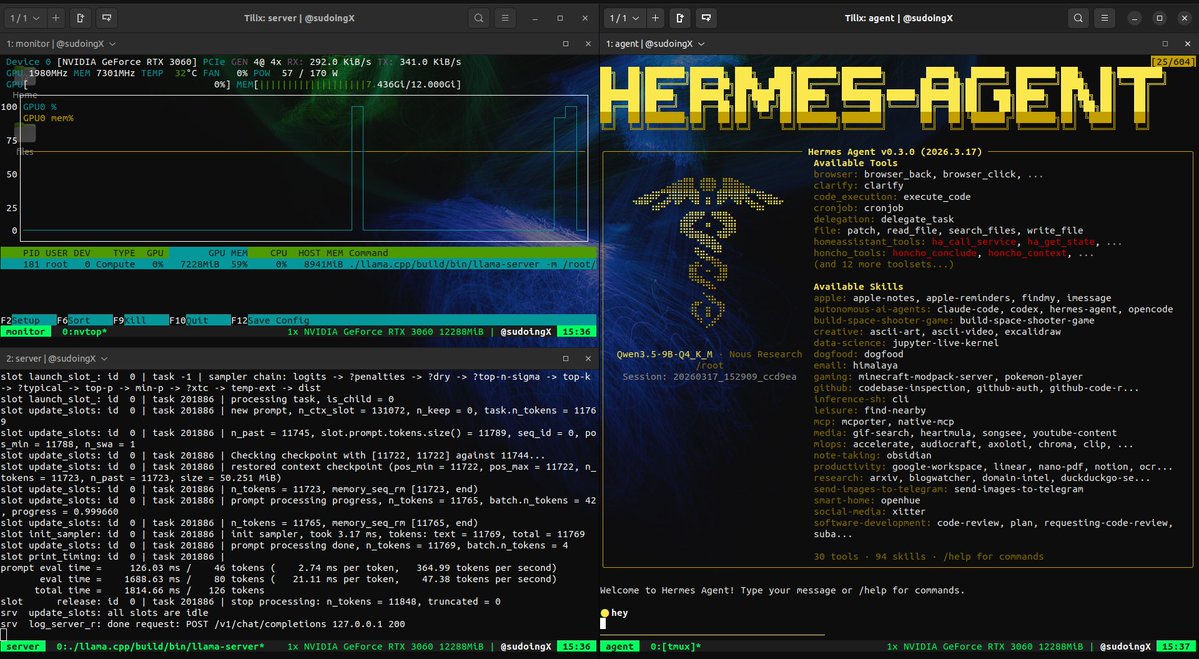

this is what 12 gigs of VRAM built in 2026. a 9 billion parameter model running on a 5 year old RTX 3060 wrote a full space shooter from a single prompt. blank screen on first try. i came back with a bug list and the same model on the same card fixed every issue across 11 files without touching a single line myself. enemies still looked wrong so i pushed another iteration and now the game has pixel art octopi, particle effects, screen shake, projectile physics and a combo system. all running locally on a card that was designed to play fortnite. three iterations. zero cloud. zero API calls. every token generated on hardware sitting under my desk. the model reads its own code, finds what's broken, patches it, validates syntax and restarts the server. i just describe what's wrong and it handles the rest. people are paying monthly subscriptions to type into a browser tab and wait for a server farm to respond. meanwhile a GPU you can find used on ebay is running a full autonomous hermes agent framework with 31 tools, 128K context window and thinking mode generating at 29 tokens per second nonstop. the game still needs work. level upgrades don't trigger and boss fights need tuning. but the fact that i'm iterating on gameplay balance instead of debugging whether the code runs at all tells you where this is headed. every iteration the game gets better on the same hardware. same 12 gigs. same 9 billion parameters. same RTX 3060 from 5 years ago your GPU is not a gaming card anymore. it's a local AI lab that never sends your data anywhere.




i run every model through octopus invaders. same prompt, same game spec if a model can build this autonomously on a single GPU it passes. if it can't it doesn't. qwen 3.5 9B Q4 on a RTX 3060. first attempt was blank screen built 2,699 lines across 11 files and nothing rendered. i wrote it off as a ceiling. then last night i came back with a precise bug list and the same model on the same card fixed every single one surgically. game came to life. enemies spawning, background rendering, collisions working. but bullets didn't fire and the enemies looked like colored squares instead of octopi. today i pushed again. listed 9 more bugs. the agent read every file, patched across 4 modules, validated syntax and restarted the server on its own. bullets fire. enemies look like actual pixel art. screen shake works. the game is playable and i genuinely enjoyed it. level upgrades still don't trigger and there's more to fix but i'm iterating on a single 12GB card running everything locally. every file, every prompt, every output stays on my machine. 29 tok/s generation, 417 tok/s prefill, 128K context window on a card that most people bought to play warzone. if you use AI in any part of your life and you have a computer with a GPU in it you should not be sleeping on this. the model weights are free. the hermes agent framework is free. your data never leaves your house. own your cognition.
