Falco Girgis@falco_girgis
Been writing SH4 assembly code for the Sega Dreamcast all day and night, hoping to bring big performance gainz to everyone in the community by providing a replacement memcpy() routine that doesn't suck for our GCC toolchains.
As it turns out, the Newlib-provided memcpy() we have backing the C standard library in our SH GCC toolchains is slow AF. This impacts not only our Grand Theft Auto 3 and Vice City ports, but also Doom64, Mario Kart 64, WipeOut, and virtually every homebrew game or port that uses KallistiOS!
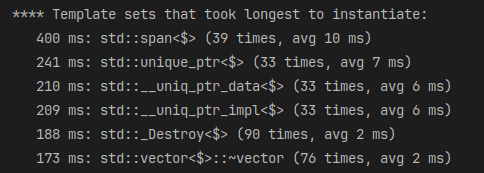
Just have a look at the benchmark results on the left to see just how shittily it performs. The benchmarker invokes a series of memcpy() implementations over an increasingly large buffer window with compile-time configurable alignments. Each iteration initializes the source buffer with a series of randomly generated numbers and clears the destination buffer before clearing both the data and icaches for each run.
During the run, the performance counters on the SH4 CPU are used to record cycle-accurate timing for each memcpy() invocation, which is then validated after the run for correctness. There are also large buffers located before and after the destination buffer, which are scanned for any stray/out-of-boundary writes after each iteration.
ANYWAY, what you're seeing in the benchmark output is the performance of my custom 1, 2, 4, 8, and 32-byte aligned memcpy() variants, which are highly optimized for specific use-cases, as well as the result of "memcpy_gainz()" which is the generalized form which attempts to call into the fastest of these specialized forms.
Meanwhile, "memcpy_fast()" is a routine we found on the internet many years ago from STMicroelectronics which has impressive speeds, but has an LGPL license, which prevents us from statically linking to it in closed-source commercial games.
Finally, "memcpy()" is the C standard library routine that ships with our toolchains... and as you can see... It runs like absolute, total, and complete shit. Somehow, at a pathologically best-case alignment of 32-bytes with 1024-byte+ copy requests, the damn thing manages to be slower than "memcpy1()" which is a simple for loop in vanilla C that could've been written by a total newbie that just copies the source buffer to the destination buffer one byte at a time...
So basically all of the bazillion things that are using memcpy() in our software in the Dreamcast community, including everything ranging from copying strings or vertices to transferring packets to and from the layers of our network stack, is all taking a massive performance hit due to us having a shitty memcpy() implementation.
After I discovered this, I embarked on a quest to take my specialized memcpyN() routines and see if I could use them as the basis for a generalized memcpy() routine to leverage. This is how "memcpy_gainz()" was born.
Unfortunately I was on my own for this quest, as every single resource that I found for writing optimal memcpy() routines was targeted at platforms which support unaligned memory accesses. Such platforms require a fundamentally different approach from the one taken for SuperH and other RISC processors without such support.
Rather than simply falling back to unaligned memory accesses, my routine attempts to align the destination buffer to 32-byte cache line boundaries where it can call into one of the fast specialized routines depending on the relative alignment of the source buffer. Then it simply does byte-by-byte unaligned copying for any bytes before or after the cache line boundaries.
At this point in time, I'm happy to say that for all alignment types I am beating even our fast_memcpy() implementation for transaction sizes larger than 32 bytes and smaller than 8KB. There's still plenty of work to do for both tiny and massive sizes, but I'm stoked to see what people do with the extra cycles once this is done!