
@tonis_a_gayaraj @sedielem @CSProfKGD Interesting! I’m gonna look into to this. I love when an “old” technique turns out to be useful again
English
Cameron Thacker
325 posts

@CameronMThacker
PhD | Co-founder @playmythical | 0-to-1 builder | recovering physicist | AI since ML | explore gt exploit | type II fun


🤯 big update to our flow map language models paper! we believe this is the future of non-autoregressive text generation. read about it in the blog: one-step-lm.github.io/blog/ full details in the paper: arxiv.org/abs/2602.16813 we introduce a new class of continuous flow-based language models and distill them into their corresponding flow map for one-step text generation. we beat all discrete diffusion baselines at ~8x speed! v2 gives a complete theory of the flow map over discrete data, with three equivalent ways to learn it (semigroup, lagrangian, eulerian). it turns out you can train these with cross-entropy objectives that look very similar to standard discrete diffusion — but without the factorization error that kills discrete methods at few steps. beyond improving results across the board, we showcase properties that are unique to continuous flows. in particular, inference-time steering and guidance become straightforward. autoguidance brings generative perplexity down to 51.6 on LM1B, while discrete baselines completely collapse at the same guidance scale. we also show reward-guided generation for steering topic, sentiment, grammaticality, and safety at inference time — and it works even at 1-2 steps with our flow map model. simple, well-understood techniques from continuous flows just work incredibly well in practice for language. we’re extremely excited about the future of this class of models. stay tuned for results on scaling, reasoning, and reinforcement learning-based fine-tuning. 🚀


I built a new plugin! You can now trigger Codex from Claude Code! Use the Codex plugin for Claude Code to delegate tasks to Codex or have Codex review your changes using your ChatGPT subscription. Start by installing the plugin: github.com/openai/codex-p…


apparently the agent harnesses keep 'rediscovering' TTT (cheating) on their own

the router in mixture of experts models is a linear layer. it takes a token's hidden state, multiplies it by a weight matrix of shape (num_experts, hidden_dim), softmaxes the result, and picks the top-k experts. that's it. but why does a matrix multiply "know" which expert to pick? each row of the router matrix is basically a learned prototype for that expert. the dot product measures how similar the token is to that prototype. high score = that expert gets activated. the cool part is nobody hardcodes what each expert specializes in. during training, gradient descent naturally pushes experts toward specialization because it minimizes loss better that way. one problem though - without a load balancing auxiliary loss, the router collapses and keeps sending tokens to the same 2-3 experts while the rest rot. that's why every moe paper has some balancing trick.

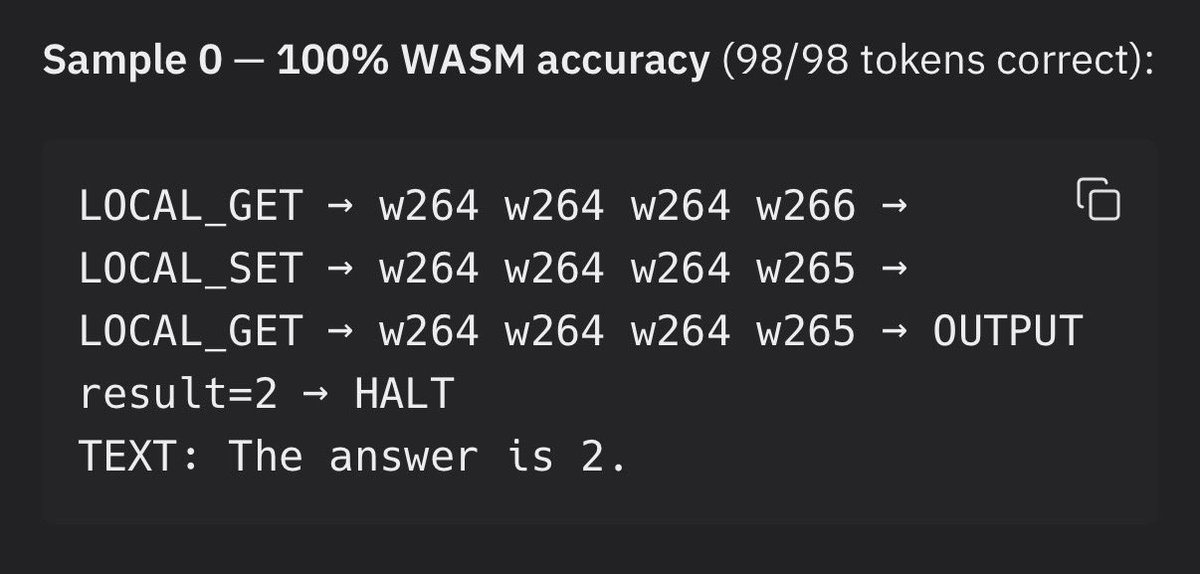
It turns out that teaching an existing language model new tokens takes a bit of work. To use wasm directly in the neural network I need the language model to output specific wasm tokens and byte tokens (one token for every byte value 0-255) that match the hard coded wasm interpreter subgraph. There are two problems. 1) the language model has never seen wasm tokens before and 2) when wasm tokens are used they flow into the wasm interpreter which will compute them and will hard fail if given invalid instructions. So the llm has to learn to use tokens it has never seen before in perfectly correct sequences. Thats enough of a challenge that my AI agent couldn’t get SFT on pretrained nanochat language model to work with about a week of trying different approaches. We either got mode collapse where the only wasm token predicted was the most common one (CONST_I32) or it learned to use the wasm operations but completely lobotomised the language model in the process and it could not produce correct byte values for inputs.


Lots of folks are apparently in utter disbelief at these numbers, because *obviously* Google search died in 2023, *no one* is using Google at all in 2026, so the numbers must be wrong somehow, or maybe it's just AI agents making all these queries? Nope, it's a plain fact that more people than ever are using Google to search more than ever. In fact Google search usage is *accelerating* as of Q4 2025 Look, instead of grasping at straws, ask yourself why you were wrong about this and try to update your priors so that you'll be less wrong next time


We've been working on very long-running coding agents. In a recent week-long run, our system peaked at over 1,000 commits per hour across hundreds of agents. We're sharing our findings and an early research preview inside Cursor.



You know that researchers need freedom and zero pressure for creativity right? Not $180M in funding which creates crazy pressure from VCs? The Transformer and Diffusion models weren’t born this way


The proof that this is possible is all around us: whereas current systems are trained on essentially all of accessible history, humans exceed AI capabilities despite seeing at most a few billion text tokens by adulthood.
