Xu Zhang
112 posts





这回~是真的了,没跟你开玩笑。
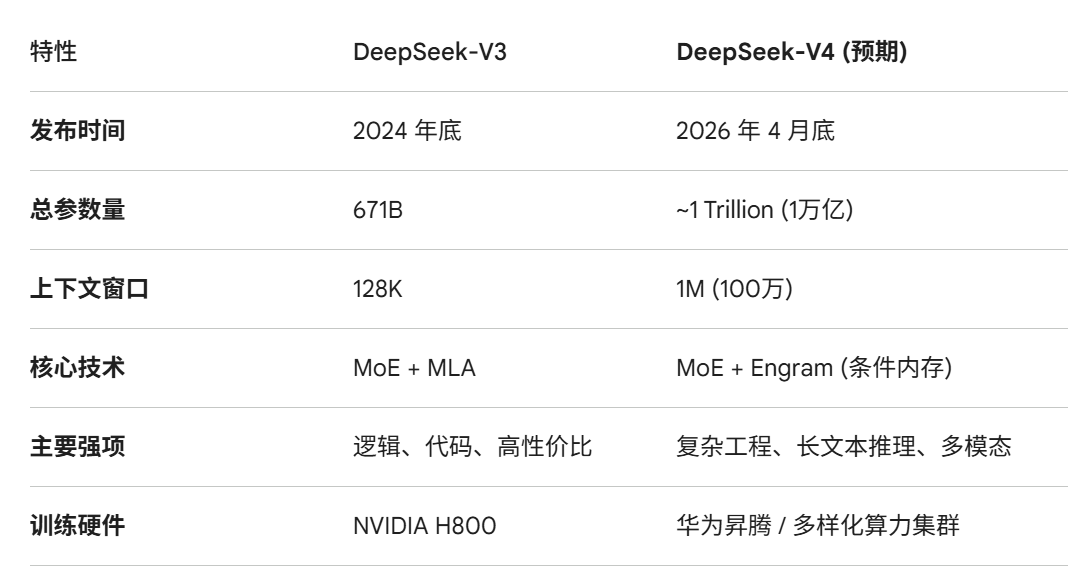
中国的 DeepSeek-V4 将在本月底发布~!
创始人梁文锋在昨天的内部沟通会议中已经透露。
3 月初,通过 DeepSeek-V4 Lite 进行架构验证,是完整版发布前的信号。
优化的 MoE 架构,虽然总参数量达到 1 万亿级别,但每个 Token 激活的参数只有 370 亿左右。所以,推理成本将维持在极低水准。
V4 还引入了非常关键的Engram 条件内存,可以让推理逻辑与知识存储分离。不需要消耗显存来死记硬背,而是以一种类似“搜索引擎索引”的方式,在推理时按需调取知识。
新版本定位非常明确,就是要做最强工程模型。代码能力、多模态和数学能力方面以开源姿态看齐Opus 4.6水准。
训练阶段,已经适配华为昇腾 (Ascend) 等国产 AI 芯片。
DeepSeek-V4 将是一个能在 24G 显存环境下,通过高倍率量化,实现万亿级知识量和百万级记忆力的怪兽级模型。
中文


Hello, creators and builders,
This week marks a leap forward in controlled storytelling, efficient intelligence, and innovative AI infrastructure.
We’re introducing Wan2.7-Video, a comprehensive model for controllable video storytelling; launching Zvec v0.3.0 with multi-platform support and official SDKs; and unveiling VimRAG, a framework for multimodal RAG.
Let’s dive in.
open.substack.com/pub/tongyilab/…

English


@heeney_luke This is over-engineering. OpenAI's product manager should rethink this. They shouldn’t decide for users how they should allocate their quota — that’s arrogance.
English

did codex just change their 5 hour limits? I am suddenly burning through it in an hour after never coming close before. Gah, usage limits are why I use it over Claude!
English


The Codex promotion for existing Plus subscribers ends today and as a part of this, we’re rebalancing Codex usage in Plus to support more sessions throughout the week, rather than longer sessions in a single day.
The Plus plan will continue to be the best offer at $20 for steady, day-to-day usage of Codex, and the new $100 Pro tier offers a more accessible upgrade path for heavier daily use.
English
We’re updating our ChatGPT Pro and Plus subscriptions to better support the growing use of Codex.
We’re introducing a new $100/month Pro tier. This new tier offers 5x more Codex usage than Plus and is best for longer, high-effort Codex sessions.
In ChatGPT, this new Pro tier still offers access to all Pro features, including the exclusive Pro model and unlimited access to Instant and Thinking models.
To celebrate the launch, we’re increasing Codex usage for a limited time through May 31st so that Pro $100 subscribers get up to 10x usage of ChatGPT Plus on Codex to build your most ambitious ideas.
English





国模不是跑分跑不上去,和国外比起来的最大的区别不是能不能跑到那个高点,而是能不能在高点站住。
很多任务跑着跑着,就上下抽风,就差那么一口气。
跑的例子够多,总能跑出几个还不错的结果,不输 opus。
但很多时候跑着就偏那么一点点。
感觉是调教着急了那么一点点。
而这个着急,可能和 KPI 或者算力又有些关系。 这些事情会影响心态和目标的。
中文
@bridgebench We need a model like GLM 5.1 to break Anthropic's arrogance.
English

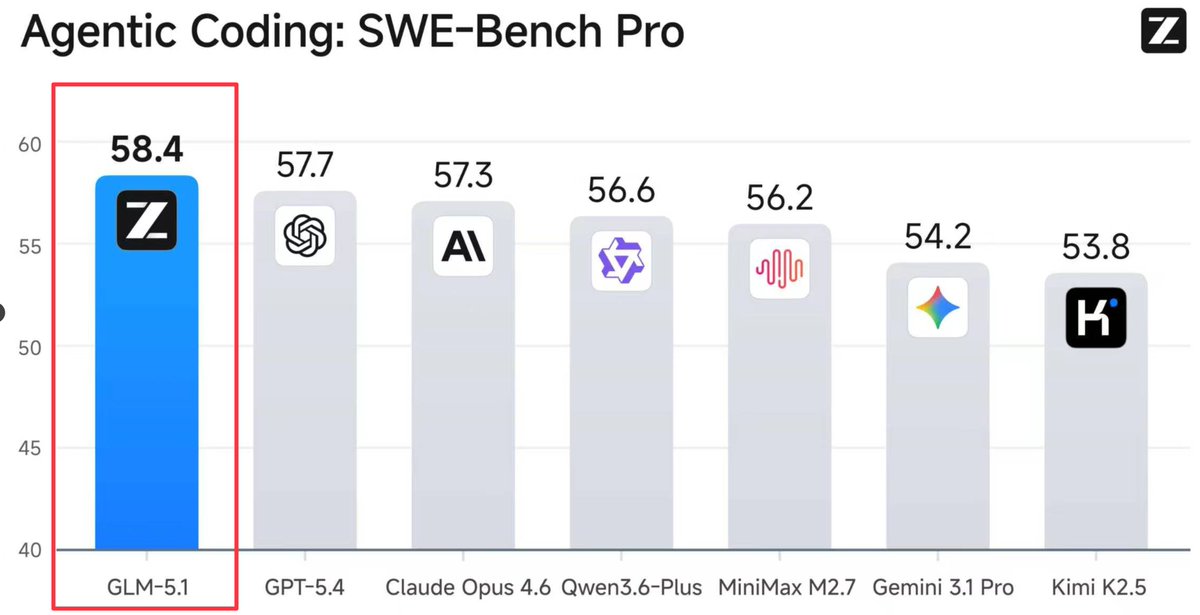
GLM 5.1 just took the #1 spot on SWE-Bench Pro.
Beating GPT 5.4. Beating Claude Opus 4.6.
Beating every model on the market.
58.4.
The $80/month model just outscored the $200/month models on agentic coding.
A Chinese model that most developers haven't even heard of is now the best agentic coder in the world according to SWE-Bench Pro.
The AI race isn't slowing down.
It's getting harder to justify paying premium when the competition keeps closing the gap.
BridgeBench results for GLM 5.1 coming soon.
English

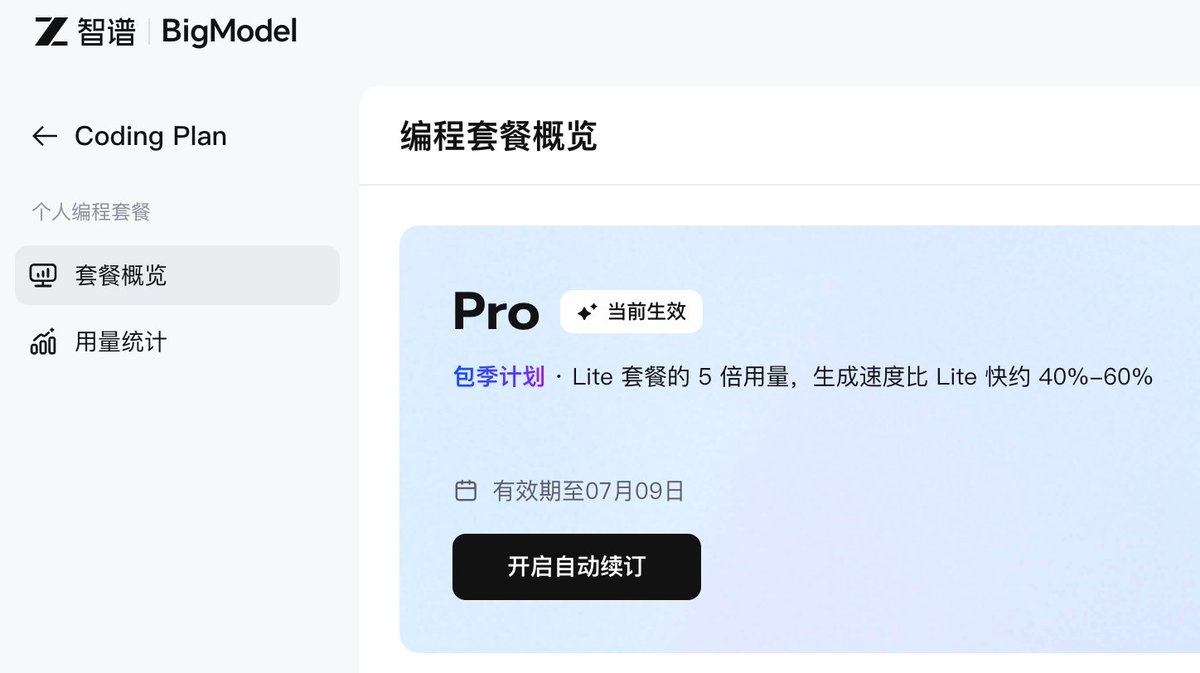
GLM coding plan 终于抢到了,自己是死活抢不了,然后没办法,某鱼找了滴滴代抢。。。
先试 3 个月的,看看好不好用,也感谢评论区大神给我推荐的 opencode go,才10美金很便宜,我也买了,两个一起测,现在应该 token 无忧了。
感谢老师们,如果有好的使用建议,也方便在评论区分享,谢谢!
0x卡卡撸特@0xkakarot888
你们到底是怎么抢到 GLM 的 Coding plan 的? 买个模型还要靠秒杀的?真是活久见,到了 10 点,页面直接太多人访问,打不开了,然后 10 点 01 分,可以打开了,被秒光了。。。 我要不是 Claude 烧不起,鬼才来抢这个。。。55555
中文
@bridgemindai Llama 4 was once involved in a scandal over over-optimizing for benchmarks. hope Muse doesn't repeat the same mistake. It's really a pity that it's not open source. If it outperformed Codex or Opus, I could understand keeping it closed, but it doesn't.
English

Meta just dropped Muse Spark and it's beating Claude Opus 4.6, GPT 5.4, and Gemini 3.1 Pro on nearly every multimodal and reasoning benchmark.
But Claude Opus 4.6 still wins on agentic coding.
The one category that matters most to vibe coders.
Meta is back on the map.
The frontier just got a lot more crowded.

English


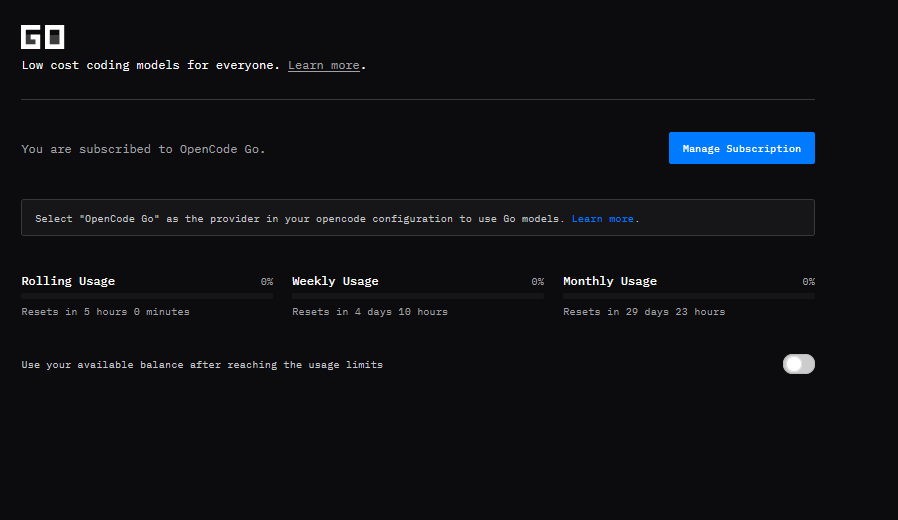

Just tried GLM 5.1
Pros:
- It's very good
- Was able to solve some complicated problem
- Very good with OpenCode and following all the agentic instructions
Cons:
- It's extremely slow
- Contextual Window is very low
1M contextual window is the bare minimum in today's time.
English