더 쓰니 | THE SSUNI 🫂@seongmoolee
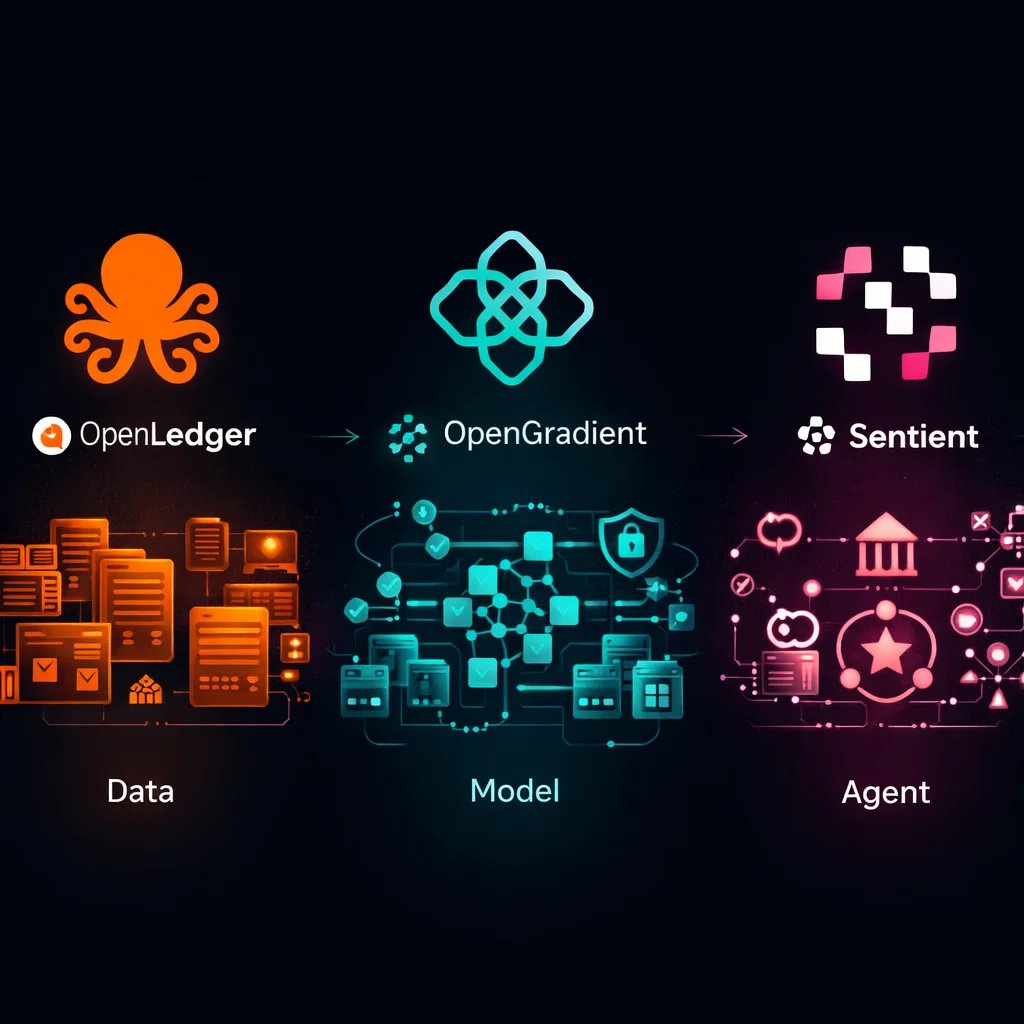
데이터가 모델이 되고 모델이 에이전트가 되는 길목에서 생기는 'AI 자산화'의 실제 절차
@OpenledgerHQ , @OpenGradient , @SentientAGI 은 각각 데이터의 출처와 정산, 모델의 호스팅과 검증 가능한 추론 그리고 커뮤니티 소유와 표준이라는 서로 다른 역할을 전면에 내세우는 프로젝트로 알려져 있다. 이 셋을 함께 놓고 보면 한쪽에서는 파일과 기록이 남고 다른 쪽에서는 모델이 배포되고 실행되며 또 다른 쪽에서는 그 결과물의 소유와 수익 분배 규칙을 다루는 식으로 데이터에서 시작해 모델을 거쳐 에이전트까지 이어지는 단계들이 어떤 형태로든 '자산'처럼 취급되기 쉬운 구조가 드러난다. 다만 2025년 12월 기준으로 이 세 프로젝트를 하나의 공식 파이프라인으로 묶어 설명하는 단일 통합 문서가 존재하지 않는 것으로 정리되어 있고 프로토콜 간 공식 통합이 이미 제공된 상태라고 말할 근거도 제시되어 있지 않다.
OpenLedger는 EVM 호환 AI 블록체인으로 소개되며 특정 도메인의 데이터 저장소로서 Datanet이라는 개념을 중심에 둔다. 기여자는 .md, .pdf, .txt, .docx 같은 파일을 업로드하고 시스템이 이를 LLM으로 파싱해 행 단위로 정리한 뒤 블록체인에 기록하는 흐름이 설명되어 있다. Datanet을 만드는 쪽은 이름, 요약, 설명, 태그 같은 메타데이터를 입력하고 파일을 올린 다음 파싱된 행을 검토한 뒤 지갑 트랜잭션으로 발행하는데 이 과정에서 파일 크기 기반으로 OPEN 수수료가 든다고 안내되어 있다. 공개형 Datanet은 커뮤니티 기여를 받을 수 있고 소유자가 승인 또는 거절을 하면 그 결정이 온체인 버전으로 반영되며 파일 업로드나 행 수정이 있을 때마다 V1에서 V2로 넘어가듯 새 버전이 만들어진다고 한다. 각 버전의 데이터 행은 그 버전 안에서는 변경되지 않는 방식으로 설명되고 무결성과 출처 추적은 Datanet Registry에 저장되는 해시와 머클 루트 같은 암호학적 값에 의존하며 원문 데이터 자체는 오프체인에 저장된다는 점도 함께 제시되어 있다.
OpenLedger가 '자산화'라는 말을 실감나게 만드는 지점은 라이선스와 정산이 단순한 문서 약속이 아니라 워크플로와 계약 로직에 걸려 있다는 설명에서 잘 드러난다. Datanet 등록 시 기계 판독 가능한 라이선스를 붙일 수 있고 비상업, 저작자 표시, 동일조건변경허락, 변경금지 같은 선택지가 정리되어 있으며 예를 들어 비상업 데이터는 상업적 학습 작업에서 차단하는 식의 제어가 스마트 컨트랙트로 구현된다고 서술되어 있다. 데이터 접근 권한도 소유자 승인 기반으로 작동한다고 하고 위반이나 분쟁 상황에서는 온체인 기록이 해시, 타임스탬프, 지갑 주소 같은 증거로 쓰일 수 있다는 식으로 설명되어 있다. 여기서 핵심 장치로 제시되는 것이 Proof of Attribution 즉 PoA인데 데이터 제출 기록, 영향도 점수화, 학습 로그, 비례 보상, 품질 집행 같은 구성 요소가 암호학적 기록과 결합된 파이프라인으로 설명된다. 또한 RAG 환경에서 생성 결과가 어떤 데이터 소스를 가져왔는지 추적하고 사용 패턴에 따라 보상을 분배하는 방식까지 언급되어 있다. 모델, 어댑터, 데이터, 에이전트 각각을 레지스트리로 다루고 학습에 사용된 Datanet과 구성 해시를 모델 레지스트리에 연결하거나 LoRA 같은 어댑터 파라미터를 어댑터 레지스트리에 남기거나 에이전트 ID와 컨트랙트 주소를 에이전트 레지스트리에 기록하는 구조도 함께 제시되어 있다.
이렇게 기록이 쌓이면 "누가 무엇을 제공했고 그 결과가 어디서 얼마나 쓰였는가"를 돈과 연결하고 싶은 유혹이 자연스럽게 생긴다. OpenLedger 쪽 문서에서는 실제로 OPEN 토큰 기반 마이크로페이먼트로 추론, API 호출, 채팅 같은 사용 단위를 과금하는 메커니즘이 제시되어 있고 PoA와 스마트 컨트랙트를 통해 데이터 기여자, 큐레이터나 검증자, 모델 제작자, 에이전트 제작자 사이의 분배가 자동으로 이뤄진다고 설명되어 있다. 발행, 학습, 배포 과정에서 드는 OPEN 수수료가 보상 풀로 쓰인다는 언급도 포함되어 있다. 동시에 한계도 분명히 적혀 있는데 원문 데이터가 오프체인에 있고 온체인에는 해시와 머클 루트만 남으므로 외부에서 데이터를 가져와 검증하는 과정이 필요하다는 점, 데이터 품질 통제가 LLM 파싱과 승인 절차 그리고 사후 슬래싱에 의존한다는 점, 대량 추론에서 어트리뷰션 로깅이 확장성 문제를 겪을 수 있다는 점이 함께 제시되어 있다. 메인넷이 2025년 9월에 출시되었다는 시점 정보와 2025년 하반기에 문서가 갱신되었다는 설명도 포함되어 있다.
모델 단계로 넘어가면 OpenGradient가 다른 무대를 만든다. OpenGradient는 Walrus 기반 분산 스토리지 위에 AI 모델을 올리고 레지스트리로 관리하는 구조로 소개되며 2025년 12월 19일 기준 테스트넷에서 1,000개 이상의 '검증 가능한' 모델이 호스팅되어 있다고 정리되어 있다. 모델은 리포지토리 형태로 구성되고 릴리스와 파일을 포함하며 웹 프런트엔드나 파이썬 SDK로 접근할 수 있다고 한다. 여기서 눈에 띄는 점은 모델 파일의 버전 해시가 원장에 커밋되어 재현성을 보장한다는 설명과 ONNX 포맷이 프레임워크 간 호환을 위해 권장된다는 점이다.
OpenGradient가 특히 강조하는 것은 '추론이 제대로 실행되었는지'를 검증하는 방식의 선택지다. 문서에서는 네 가지 모드를 제시하는데 ZKML은 영지식 증명으로 즉시 암호학적 검증을 제공하는 대신 지연이 1000배에서 10000배까지 커질 수 있다고 적혀 있고 TEE는 하드웨어 어테스테이션으로 2배에서 3배 정도의 오버헤드를, ZK-CRV는 확률적 샘플링 기반의 도전응답으로 1배에서 2배 수준의 오버헤드를, Vanilla는 별도 검증 없이 일반 계산으로 동작한다고 정리되어 있다. 또한 실행마다 입력, 프롬프트, 출력 같은 트레이스를 온체인으로 남겨 감사 가능성을 제공한다는 설명, 멤풀에서 병렬로 실행을 준비하는 PIPE라는 메커니즘으로 처리량을 높인다는 설명이 함께 제시되어 있다. EVM에서 네이티브로 모델을 호출할 수 있도록 프리컴파일을 제공한다는 언급과 Base Sepolia 테스트넷 체인 ID 84532에서의 통합이 언급되며 2025년 12월 기준 메인넷 배포는 미정이라고 정리되어 있다. 에이전트 관점에서는 OpenAI 스타일의 툴 콜링 인터페이스, LangChain이나 Swarm 같은 프레임워크 연동, MemSync라는 지속 메모리 시스템, 실행 추적을 보여주는 Agent Explorer 같은 요소가 소개되어 있다. 반대로 학습이나 파인튜닝에 대한 명시적 문서가 부족하고 플랫폼이 주로 호스팅과 추론에 초점을 둔다는 '공백'도 같이 언급되어 있다.
Sentient는 모델을 단순히 배포 가능한 파일이 아니라 소유와 거버넌스, 수익 분배가 붙는 '공동체의 자산'으로 다루는 방식에 초점을 맞춘 것으로 소개된다. Sentient는 오픈소스 AI 연구 조직으로 포지셔닝되어 있고 GRID라는 지능 네트워크, Sentient Chat이라는 사용자 인터페이스, OML이라는 소유 표준 그리고 Dobby나 ROMA 같은 모델 이름이 함께 제시되어 있다. 2024년 7월 8,500만 달러 시드 투자 언급과 함께 2025년 12월 기준 토큰 생성 이벤트 이전 단계이며 향후 $SENT 토큰을 계획하고 있다는 설명이 포함되어 있다. 거버넌스는 개별 모델을 다루는 ArtifactDAO와 프로토콜 레벨을 다루는 SentientDAO의 이중 구조로 정리되어 있고 수익 공유와 모델 진화에 대한 투표 권한 같은 권리 구조가 온체인 계약을 통해 다뤄진다고 설명되어 있다. EigenLayer 협업으로 2025년 2월에 Judge Dobby라는 분쟁 자동 판정 모델이 개발되었다는 언급, 제안이 헌장과의 정합성을 평가받는 과정에 CHANCERY 벤치마크가 쓰인다는 언급도 함께 나온다.
Sentient에서 '자산화'의 표준으로 제시되는 것은 OML, 즉 Open, Monetizable, Loyal이라는 성질을 묶은 프레임워크다. 오픈은 모델 가중치가 다운로드 가능하다는 뜻으로, 수익화 가능은 사용 추적과 수익 API로 보상을 연결한다는 뜻으로, 충성은 모델 가중치에 암호학적 지문을 심어 출처와 가치를 집행한다는 뜻으로 설명되어 있다. 이 지문은 TEE나 온체인 메커니즘과 연결되어 접근 통제와 출처 추적에 쓰인다고 제시되고 OML 관련 내용이 NeurIPS 2025 워크숍에서 발표되었다는 언급도 포함되어 있다. GRID는 에이전트, 데이터, 도구, 컴퓨트를 묶어주는 디렉터리 또는 API 성격의 네트워크로 설명되며 110개 이상의 파트너가 있다는 숫자도 제시되어 있다. Sentient Chat은 GRID로 들어가는 관문으로 소개되고, 2025년 11월 베타 기준 29만 사용자와 월간 활성 사용자 5만이라는 수치가 언급되어 있으며 질의 처리 과정에서 어떤 모델이나 에이전트가 사용되었는지 실시간으로 보여준다는 설명이 포함되어 있다. Sybil 방어로 'Billions ZK selfie proof' 같은 1인 1계정 검증을 언급하고 봇 트래픽이나 조작을 줄이기 위한 행동 분석과 감사, 지문 검출, 슬래싱 같은 요소도 함께 소개되어 있다. 2025년 11월에 채팅 사용자와 커뮤니티 역할, 연구자 등을 대상으로 한 과거 에어드롭이 있었다는 설명과 2,200만 쿼리 처리 같은 수치도 자료에 포함되어 있다.
이제 이 셋을 '데이터에서 모델로 모델에서 에이전트로' 이어지는 파이프라인처럼 바라볼 때 가장 눈에 띄는 것은 각 단계가 무엇을 남기고 무엇을 실행하는지의 역할 분담이다. OpenLedger는 Datanet과 레지스트리를 통해 데이터 버전과 기여자, 라이선스, 학습 참조 같은 흔적을 남기는 쪽에 가깝고 OpenGradient는 모델 파일의 버전과 실행 로그 그리고 실행이 정직했음을 보여주는 검증 수단을 제공하는 쪽에 가깝고 Sentient는 그 모델이 공동체 안에서 어떻게 소유되고 어떤 규칙으로 수익을 나누며 어떤 표준으로 '정품임'을 주장할지를 다루는 쪽에 가깝다. 자료에는 예시 흐름으로 OpenLedger에서 데이터셋을 등록하고 학습 로그를 남기고 학습 결과물을 어댑터 레지스트리에 기록한 뒤 모델을 ONNX로 내보내 OpenGradient 모델 허브에 업로드해 CID와 버전 해시를 받으며 Sentient의 GRID 레지스트리에 올려 OML 지문과 거버넌스 파라미터, 수익화 규칙을 붙이는 순서가 제시되어 있다. 에이전트 단계에서는 Sentient의 오케스트레이션 레이어가 작업을 분해하고 라우팅하며 에이전트가 OpenGradient의 추론을 호출하고 그 호출 기록이 트랜잭션 해시 같은 형태로 남아 출처 추적과 정산의 실마리가 된다는 식의 서술도 포함되어 있다.
이 흐름이 실제 운영에서 제일 먼저 부딪히는 문제로 자료가 지적하는 것은 '서로 다른 체인과 거버넌스의 경계'다. OpenLedger는 EVM 환경으로 정리되어 있고 OpenGradient는 별도의 L1로 구분되어 있으며 Sentient는 거버넌스 레이어와 표준 그리고 GRID 네트워크를 중심으로 설명된다. 정산이 실제로 한 줄로 이어지려면 체인 간 메시징이 필요하다는 점이 자료에 명시되어 있고 OpenLedger는 LayerZero 통합이 언급되지만 OpenGradient 쪽 브리지 메커니즘은 2025년 12월 기준 문서화되지 않았다고 정리되어 있다. 토큰 체계도 OpenLedger의 $OPEN 과 Sentient의 향후 $SENT 처럼 분절되어 소개되어 있어 사용자가 여러 지갑과 여러 결제 단위를 오가야 한다는 운영 부담이 UX 관점의 마찰로 서술되어 있다.
성능과 신뢰의 맞바꿈도 이 파이프라인을 '자산화'라는 말에서 '서비스'라는 말로 옮겨갈 때 가장 민감한 지점으로 드러난다. OpenGradient의 검증 모드에서 ZKML은 강한 검증을 제공하는 대신 지연이 매우 크다고 정리되어 있고 TEE와 ZK-CRV는 상대적으로 낮은 오버헤드를 가진다고 제시되어 있다. 자료에는 오프체인에서의 빠른 추론과 온체인 정산을 결합하는 하이브리드 구조가 언급되며 원장에 남겨야 하는 것은 출처와 정산에 필요한 최소한의 증거로 좁혀지고, 계산 자체는 GPU 클러스터 같은 오프체인 자원에서 수행될 수 있다는 설명이 포함되어 있다. 동시에 OpenLedger의 원문 데이터 오프체인 저장 구조, 대량 추론에서의 어트리뷰션 로깅 부담, 데이터 품질이 사전 검증보다는 승인과 사후 슬래싱에 기댄다는 점이 한계로 정리되어 있어 "무결성은 증명할 수 있지만 품질은 별도의 사회적 절차와 결합된다"는 느낌을 준다.
그럼에도 이 조합이 Web2와 구별되는 지점은 자료가 비교 항목으로 제시한 요소에서 분명해진다. 중앙화 플랫폼에서는 데이터 출처와 학습 데이터가 불투명하거나 수익 분배가 계약과 플랫폼 정책에 의해 좌우되기 쉽고 기여자가 다운스트림 수익에 직접 연결되지 않는 경우가 많다고 정리되어 있다. 반면 여기서는 Datanet의 해시와 머클 루트, 학습 로그, 모델 버전 해시, 실행 트레이스, OML 지문 같은 암호학적 흔적이 누적되어 누가 무엇을 제공했고 무엇이 어떤 방식으로 쓰였는지 확인 가능한 형태로 남는다고 설명된다. 자동 정산은 스마트 컨트랙트가 담당한다는 점이 반복해서 강조되고 추론이 검증 모드로 실행될 수 있다는 점도 신뢰의 근거로 제시된다. 한편 지갑, 가스, 멀티 토큰, 마이크로페이먼트 같은 요소가 일반 사용자에게는 진입 장벽이 될 수 있고 투명한 어트리뷰션이 모든 사용자에게 같은 가치를 주는 것은 아니라는 점도 UX의 부담으로 함께 정리되어 있다.
정리하면 OpenLedger는 데이터가 '누구의 것이었는지'와 '어떻게 쓰였는지'를 남기는 장부를 만들고, OpenGradient는 모델이 '어떤 버전으로' '어떤 방식으로' 실행되었는지와 그 실행을 '어떻게 검증할지'를 고르게 하며 Sentient는 그 모델과 에이전트가 공동체 안에서 '어떤 권리와 책임'으로 묶이고 '어떤 표준'으로 정품성과 수익화를 주장할지를 구성하는 쪽에 가깝다. 이 셋을 한 줄로 완전히 묶는 공식 통합은 2025년 12월 기준 확인된 형태로 제시되어 있지 않지만 데이터 등록과 버전 관리, 모델 호스팅과 검증 가능한 추론, 표준화된 지문과 거버넌스, 사용 기반 수익 분배라는 요소들이 각각의 프로젝트 설명 속에 자리하고 있다는 점은 분명하다. 결국 'AI 자산화 파이프라인'이라는 말은 마법처럼 한 번에 완성된 시스템을 뜻하기보다 데이터와 모델과 에이전트가 지나가는 지점마다 남는 기록과 증거 그리고 그 기록을 돈과 권리로 바꾸는 절차가 어디에 놓여 있는지를 차근차근 확인해 보는 관점에 가깝다.