Cheapshothubs
27.6K posts


SHOULD MEN TAKE OFF ON THEIR BIRTHDAYS?
I DON’T THINK SO.
English

Glamorous JP Morgan exec accused of turning married male broker into her office sex slave: Viagra spiking and litany of obscene forced acts that made him cry trib.al/BiXXCM0
English

@CollinRugg I never understood why a whole family travel together. It’s crazy
English
Cheapshothubs retweetledi

NEW: Hundreds of thousands of dollars were stolen from NASCAR legend Greg Biffle's accounts very soon after he and his family died in a plane crash in North Carolina.
Authorities now believe that the fraud and robbery may have been an "inside job."
Biffle went viral during Hurricane Helene for helping stranded people.
According to investigators, someone used Biffles' personal info to access his financial accounts and transferred funds.
Almost immediately after the tragedy that killed Biffle, his wife, and his children, suspicious activity began taking place on his family's email accounts and bank accounts. This included changes to emails, phone numbers, and passwords, according to WSOC TV.
Just hours after the plane crash, an email was sent to Biffle's email account that said: "I heard you're dead, rest in hell."
His home was also robbed. $30,000 in cash, handguns, and NASCAR memorabilia were stolen.
Detectives say that the burglary and fraud may have been coordinated and reliant on "insider" knowledge.
According to surveillance footage, a woman is seen walking through his home. She appeared to know where the security cameras were placed.
Detectives claim to have identified someone who matches the woman's description. She was reportedly identified during a celebration of life ceremony for the Biffle family.
Insane how evil people can be.
English
Cheapshothubs retweetledi

Cheapshothubs retweetledi

Cheapshothubs retweetledi

What an interesting thing for an American to care so much about. I wonder what originally inspired his interest in that.
Josie Stratman@JosieStratman
Mayor Mamdani, pressed on what he would say to King Charles if they talk later: “If I was to speak to the king… I would probably encourage him to return the Kohinoor diamond,” Mamdani says, referring to the gem in the British Crown Jewels, which taken from India.
English
Cheapshothubs retweetledi

“Jesus was wrong and needed to be corrected’ Lutheran pastor on Luke 10.
Imagine standing in a pulpit thinking you’re morally above Jesus Christ.
Yeah… Lutherans are outta control.
English
@hashjenni Excellent, please continue to share the good news!!
English

In case anyone isn’t aware, Trump is demanding Zambia to hand over its mineral rights by end of day tomorrow or the U.S. gov’t will cut off the country’s access to the AIDS medications that are literally keeping its citizens alive.
Just thought y’all should know.
English
Cheapshothubs retweetledi


Cheapshothubs retweetledi

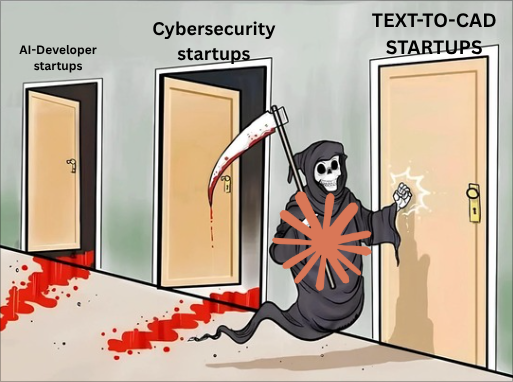
Codex computer use really is a goblin in your computer when you think about it
English
Cheapshothubs retweetledi
*Codex takes down the internet*
"Your honor, in his defense, my client was in Goblin mode."
English
Cheapshothubs retweetledi

Cheapshothubs retweetledi

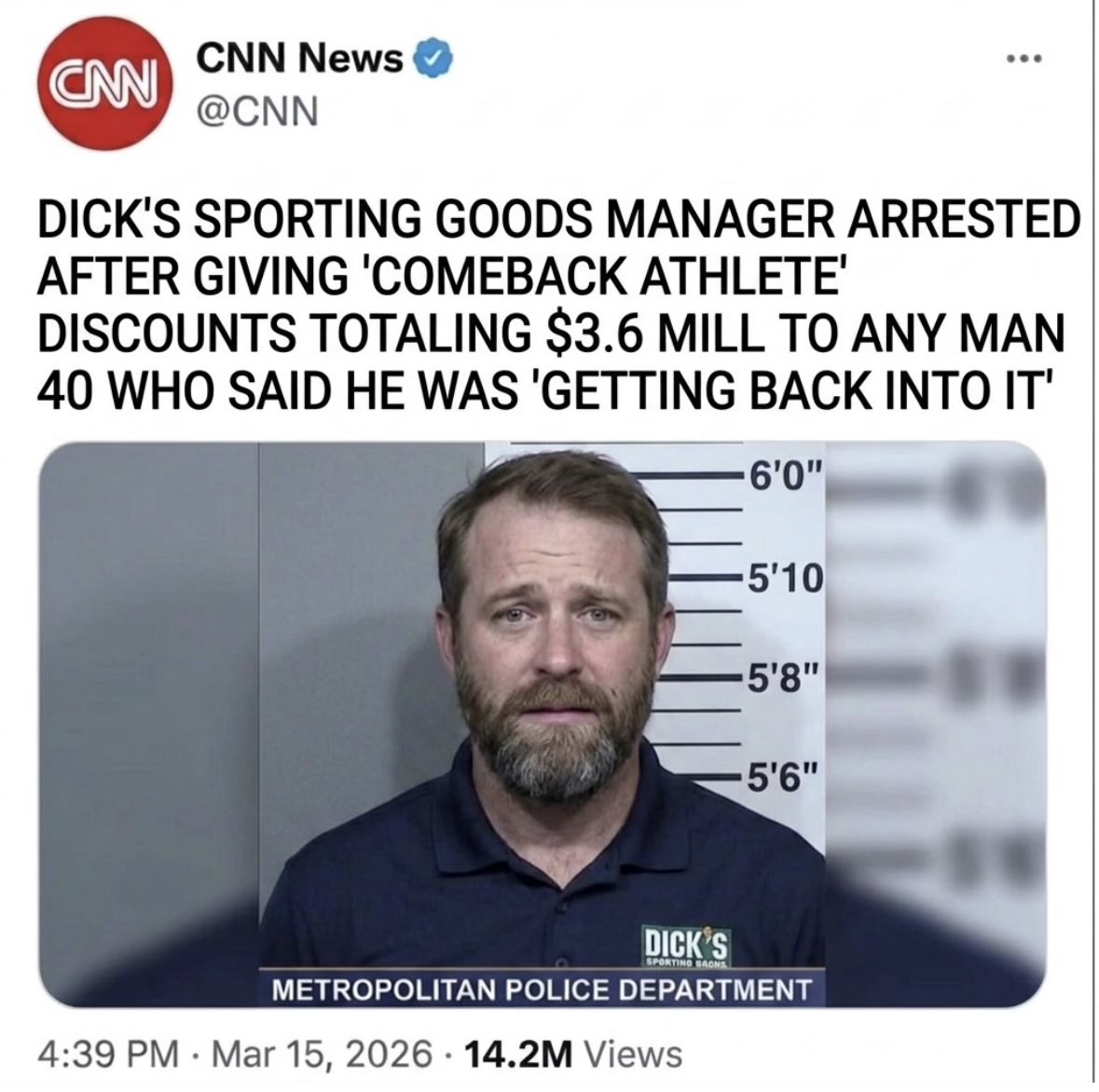
Deloitte executives finding out the interns have been pouring chemicals into waterways
Bitcoin Teddy@Bitcoin_Teddy
AOC says "rivers were on fire" because of corporations like Deloitte "pouring chemicals" into waterways. Deloitte is an accounting, consulting, and tax services firm. No idea what she's talking about.
English
Cheapshothubs retweetledi

Cheapshothubs retweetledi

Deloitte’s CEO finding out his accountants have been pouring chemicals into the river

Bitcoin Teddy@Bitcoin_Teddy
AOC says "rivers were on fire" because of corporations like Deloitte "pouring chemicals" into waterways. Deloitte is an accounting, consulting, and tax services firm. No idea what she's talking about.
English
Cheapshothubs retweetledi


Cheapshothubs retweetledi

Andrej Karpathy just sat down and built GPT from scratch, line by line, in 2 hours.
For Free. From the man who co-founded OpenAI.
This video is enough to become an AI engineer.
Bookmark it. Watch it tonight. Build your own GPT this week.
$5,000. $15,000. $40,000.
That's what bootcamps charge to teach less than what's in this 2-hour video.
This video fixes that this week.
Follow @codewithimanshu for more high-signal AI content that actually moves your engineering career forward.
↓
Karpathy doesn't explain GPT. He builds it.
Live. From "Attention is All You Need" the original paper. To the same architecture powering GPT-5.
Founding member of OpenAI in 2015. Senior Director of AI at Tesla. Now running Eureka Labs.
He's not teaching you how to use GPT. He's teaching you how it actually works at the source code level.
Most engineers will never understand transformers this deeply. The ones who do build the next generation of AI products.
Follow @codewithimanshu for breakdowns of every must-watch AI lecture worth your time.
↓
Here's what gets built in 2 hours. No fluff.
Tokenization and data loading.
The foundation of every modern LLM. Train/val splits done right. Batch loaders that don't break in production.
Most tutorials skip this. You can't ship anything serious without it.
The bigram baseline.
The simplest possible language model. Karpathy builds it first because it teaches you what every fancier model is actually trying to improve.
Once you understand bigrams, transformers become obvious. Skip this and the rest never clicks.
Follow @codewithimanshu for daily breakdowns of what AI engineers actually need to know.
↓
Self-attention. From scratch. Live.
This is the section that should have its own course.
Karpathy builds self-attention in 4 versions:
> Version 1: averaging past context with for loops
> Version 2: matrix multiply as weighted aggregation
> Version 3: adding softmax
> Version 4: full self-attention
Each version teaches you why the next one exists. Why attention works. Why matrix math replaces explicit loops. Why scaling matters.
You'll never look at "attention is all you need" the same way again.
Follow @codewithimanshu for production transformer breakdowns weekly.
↓
The 6 attention notes that change everything.
Karpathy drops 6 insights most engineers never hear:
> Attention as communication between tokens
> Attention has no notion of space, operates over sets
> No communication across batch dimension
> Encoder blocks vs decoder blocks
> Attention vs self-attention vs cross-attention
> Why we divide by sqrt(head_size)
Each one of these explains a different failure mode in production AI systems.
Most "AI engineers" can't answer these. The ones who can charge $300K.
Follow @codewithimanshu for the engineering insights that turn into job offers.
↓
Building the full transformer block.
Single self-attention head. Then multi-headed self-attention.
Feedforward layers. Residual connections. LayerNorm.
Each piece added with the reason it exists. Why residuals stop the model from collapsing. Why LayerNorm replaced BatchNorm. Why dropout matters at scale.
This is the architectural understanding that lets you debug any modern AI system.
Once you've built one transformer by hand, every paper you read becomes 10x clearer.
Follow @codewithimanshu for transformer architecture content every week.
↓
Scaling up to a real model.
Karpathy goes from baseline to a working GPT.
Hyperparameters. Dropout. Model dimensions. The exact tradeoffs every production model makes.
By the end you have a Shakespeare-generating language model running on your machine. From scratch. Built by you. Understood by you.
That's not a tutorial. That's an architectural unlock.
Follow @codewithimanshu for production model scaling breakdowns.
↓
Encoder vs decoder vs both.
The architecture choice that defines every modern AI product.
Why GPT is decoder-only. Why BERT is encoder-only. Why translation models use both.
Once you understand this, you can read any AI paper and immediately know what kind of system you're looking at.
This is the difference between someone who follows AI hype and someone who builds it.
Follow @codewithimanshu for AI architecture deep dives weekly.
↓
NanoGPT walkthrough.
Karpathy ends with a quick walk through nanoGPT. The repo every serious AI engineer has cloned at least once.
Batched multi-headed self-attention. Production-grade code. The clean version of everything you just built.
This is the bridge from "I built a toy GPT" to "I can read and modify production AI code."
Follow @codewithimanshu for repos every AI engineer should know.
↓
ChatGPT, pretraining, finetuning, RLHF.
The video closes with the full lineage. From your toy GPT to ChatGPT.
What changes when you scale up. Why RLHF matters. The exact path from research model to product.
You finish the video understanding the entire stack from raw paper to deployed product.
Most "AI experts" can't draw this map. After 2 hours, you can.
↓
What you'll be able to do after this.
Read "Attention is All You Need" and understand every line.
Debug attention layers when they break in production.
Build a custom language model on your own dataset.
Modify transformer architectures for specific use cases.
Have technical conversations with AI engineers without faking it.
Train a GPT on any data you want. Shakespeare. Code. Your own writing.
That's not "AI literacy." That's the foundation of an AI engineering career.
The kind of foundation that turns into senior roles and consulting contracts most people will never access.
↓
2 hours. Free. From the engineer who built it.
You'll spend longer in meetings this week and learn nothing.
This compounds for the rest of your career.
People who watch it can build GPT from scratch by Friday.
People who skip it stay confused about why their prompts fail in production.
Save the video. Watch it this week. Build something with the knowledge by the weekend.
Follow @codewithimanshu for more high-signal AI content from the people actually building the future.
English
Cheapshothubs retweetledi

$15,000/month
that’s what one boring expired patent could turn into, most people have no idea
meanwhile one guy:
- skipped Amazon trends
- scraped expired USPTO patents
- filtered 340,000 dead products
- found 6 with real demand
- sent the drawings to Alibaba
- put the first one into production
- all the code inside
- the full pipeline inside
- every prompt inside
the window is open while everyone is still hunting for “winning products”
Gipp 🦅@gippp69
English
Cheapshothubs retweetledi