Yuhang Chen retweetledi

Beautiful paper, MetaClaw
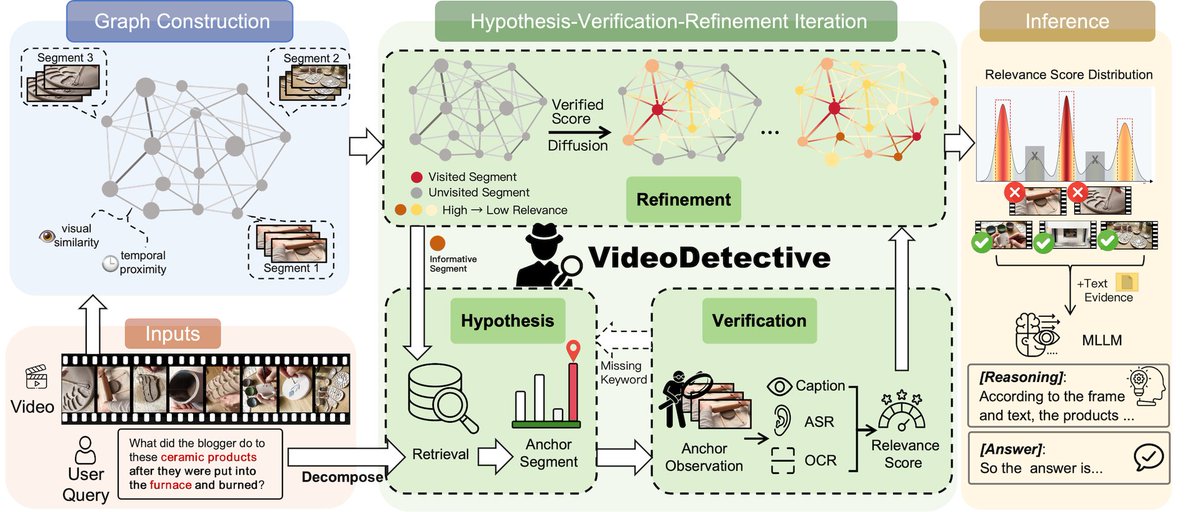
Shows how a deployed LLM agent can keep learning on the job without stopping service.
The current problem is that most agents in production stay frozen, so they keep making the same mistakes as user needs shift and new kinds of tasks appear.
The paper’s fix is to split improvement into 2 loops: a fast loop that turns failures into reusable written skills right away, and a slow loop that later updates the model itself.
That split matters because the new skills help immediately with no downtime, while the slower training runs only when the user is away, using idle time like sleep, inactivity, or meetings.
The authors tested this on a 934-question benchmark built as 44 simulated workdays and on a separate automated research pipeline that has 23 stages.
They found that skills alone raised accuracy by up to 32% relative, and the full setup lifted Kimi-K2.5 from 21.4% to 40.6% while also improving robustness on the research pipeline by 18.3%.
What makes the paper matter is the pattern behind the gains: production agents can adapt fast now and learn deeper later, so they improve from real use instead of staying frozen.

English